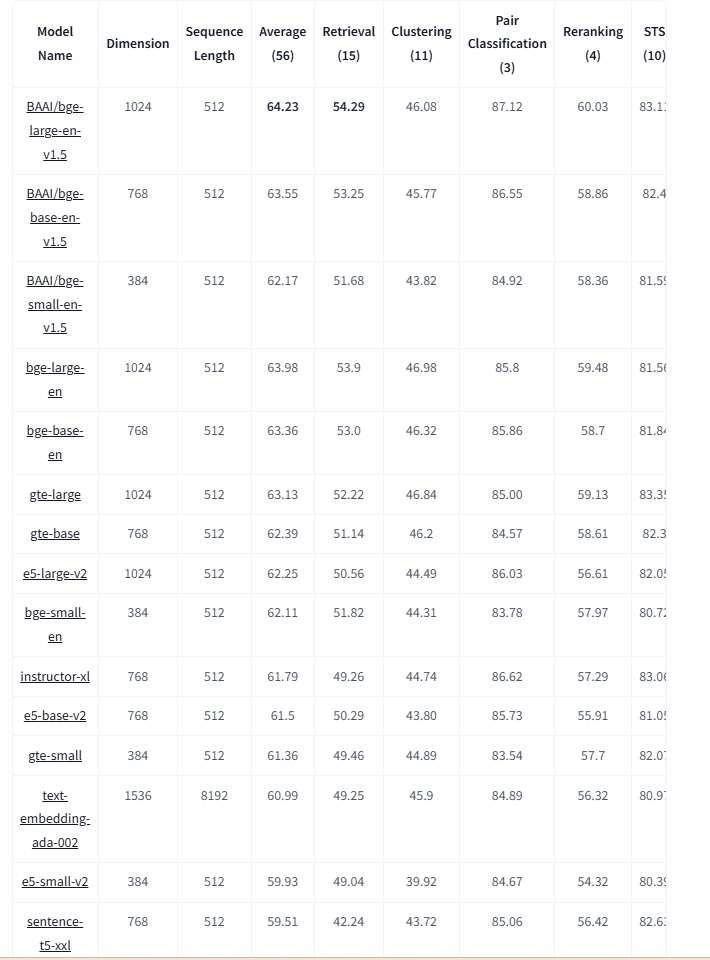
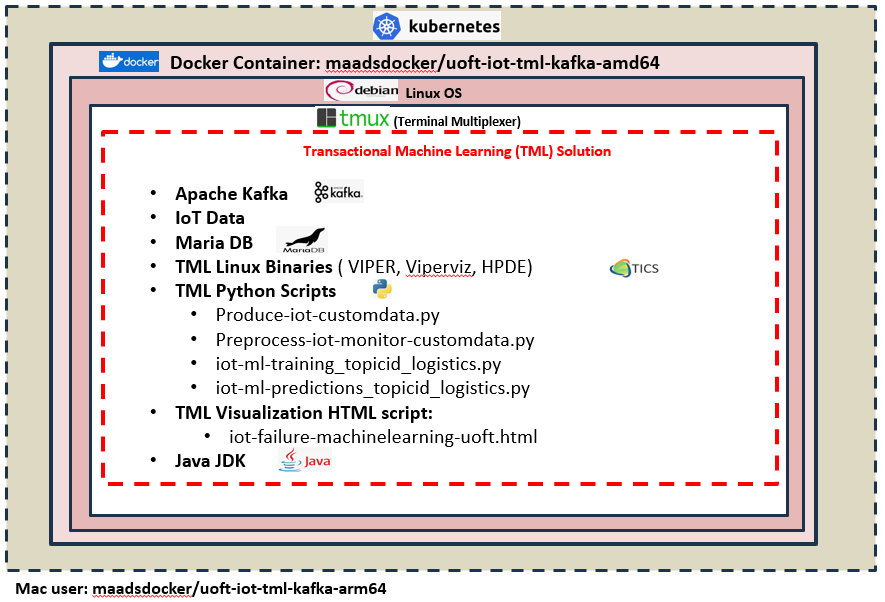
TML is the world’s only technology that can perform entity based machine learning, in-memory, on real-time data integrated with Apache Kafka. Any where you need to process real-time data - you NEED TML. It can be used in any industry globally.
Important
TML offers several advantages over conventional Stream Processing: In addition to being:
the FASTEST and EASIEST way to build advanced, scalable, secure, and cost-effective, real-time solutions, with GenAI, for the Enterprise,
in roughly TWO (2) minutes with
automated documentation,
automated docker builds and,
automated code commits to Github
with tight integration with Apache Airflow and Apache Kafka
More Reasons:
Stream Processing from AWS Kinesis, or Spark Streaming - Do Not perform in-memory entity based machine learning or processing of real-time data. TML Does.
2. Stream Processing technologies are very expensive. Because TML is comprised of 3 binaries they can be operated like microservices with very little cost
overhead (if any) due to in-memory processing of real-time data - this means no external databases are needed for machine learning reducing storage, compute
and network transfer costs.
Stream processing solutions still use SQL to process data. TML uses JSON processing, in-memory, which is faster, cheaper and easier to manage.
4. Performing machine learning with Streaming processing is difficult, costly, and does not perform entity based machine learning. TML performs in-memory
machine learning at the entity level for each device that is producing real-time data, this makes it very effective to learn each individual device behaviours
and predict future behaviours more accurately.
5. Stream Processing technologies still require lots of code. TML solutions are low-code or no-code using the TML Solution Studio (TSS). The TSS uses DAGs
that allows users to quickly configure their TML solutions, and automatically deploy it with Docker, automatically generate the documentations for the
solution, and commit code to Github repos.
6. TML is integrated with GenAI using PrivateGPT and Qdrant vector DB. This integration makes it the first solution that provides fast AI integrated with
real-time data processing and machine learning at the entity level.
7. To ingest data from devices TML offers pre-built client python code. Users can easily using gRPC, REST API, MQTT to ingest data directly from devices and
stream it to Kafka. Refer to STEP 3: Produce to Kafka Topics for more details.
TML is used by companies and people around the world to process real-time data. Because TML is free for students and researchers, it is used by thousands of
students in Universities and Colleges around the world as official part of the curriculum courses in IoT, Cybersecurity, Machine Learning, Data Science, and
Big Data Management courses.
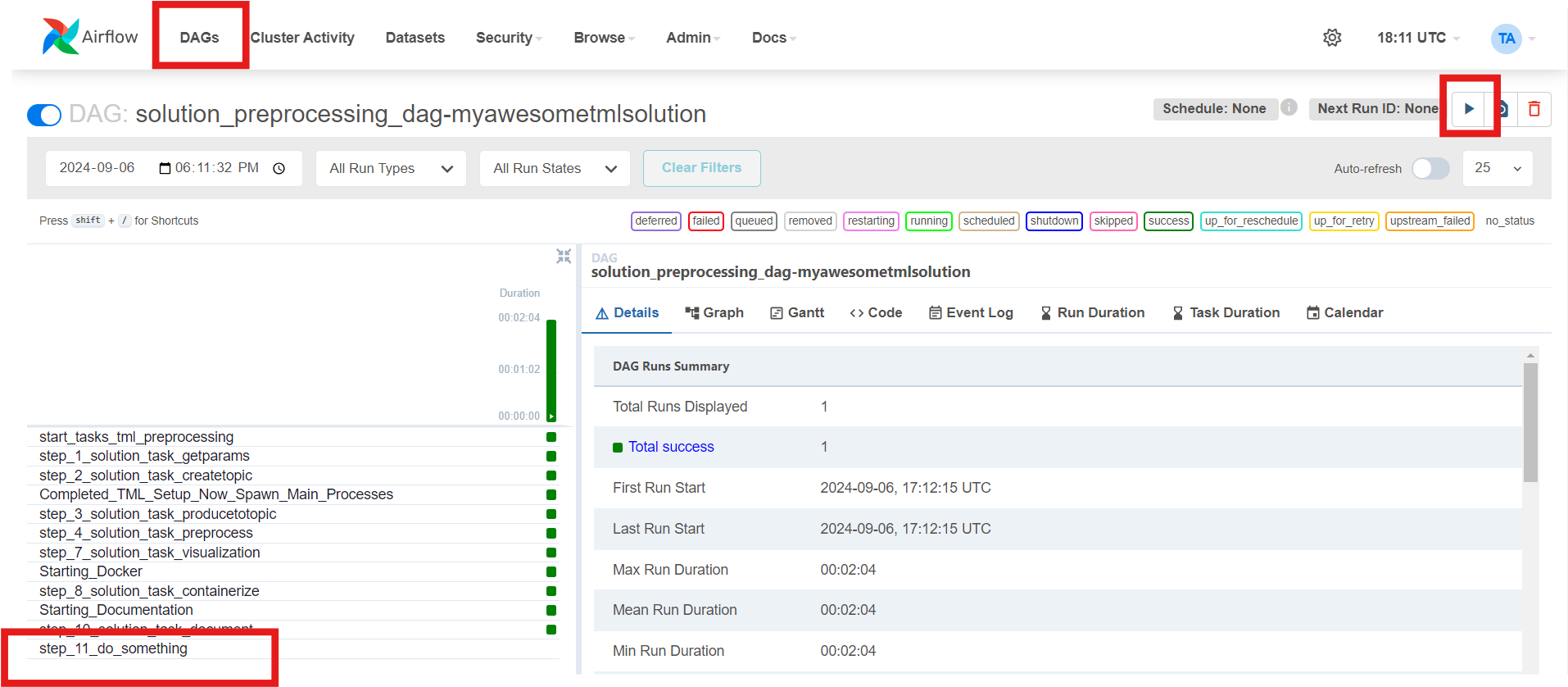
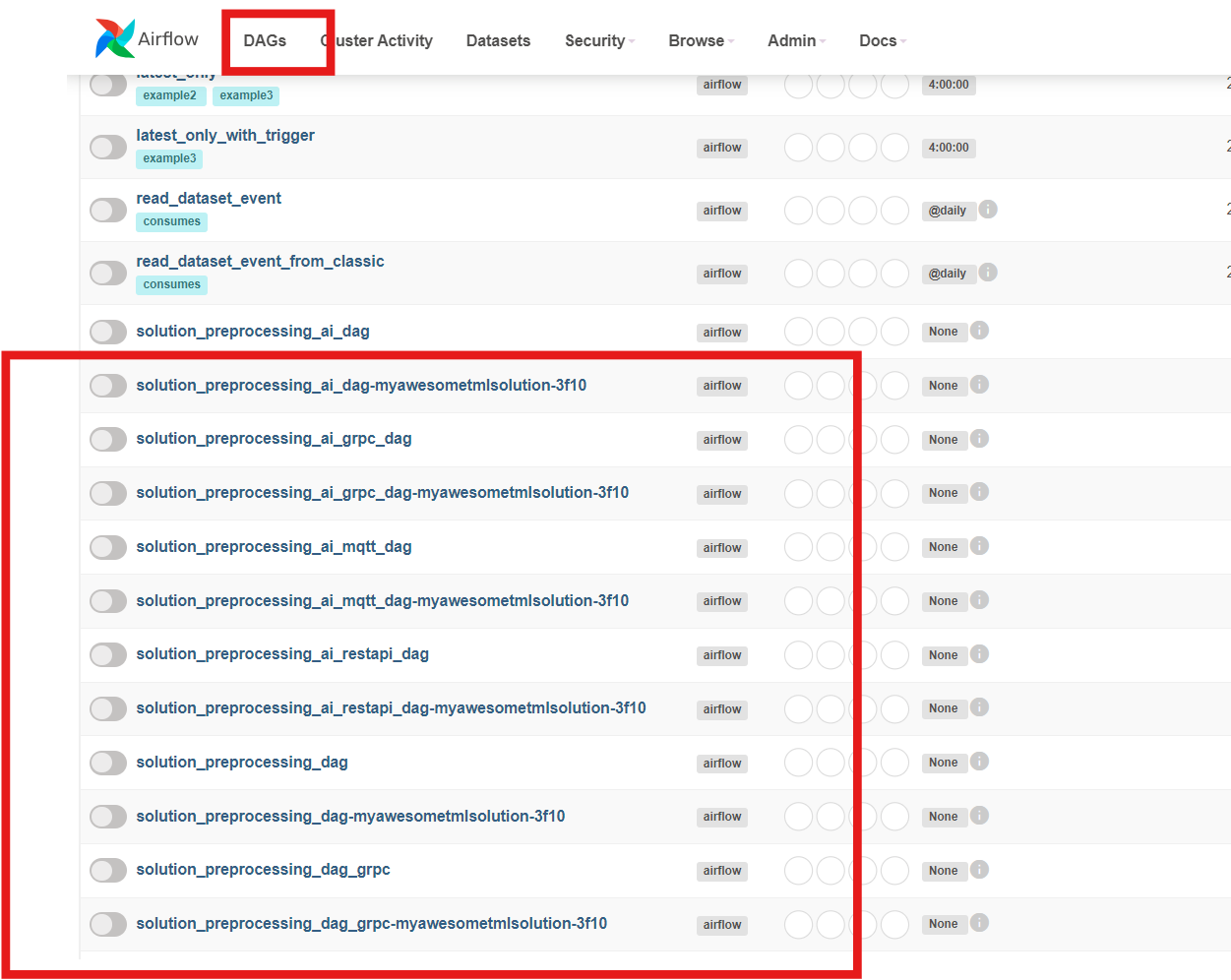
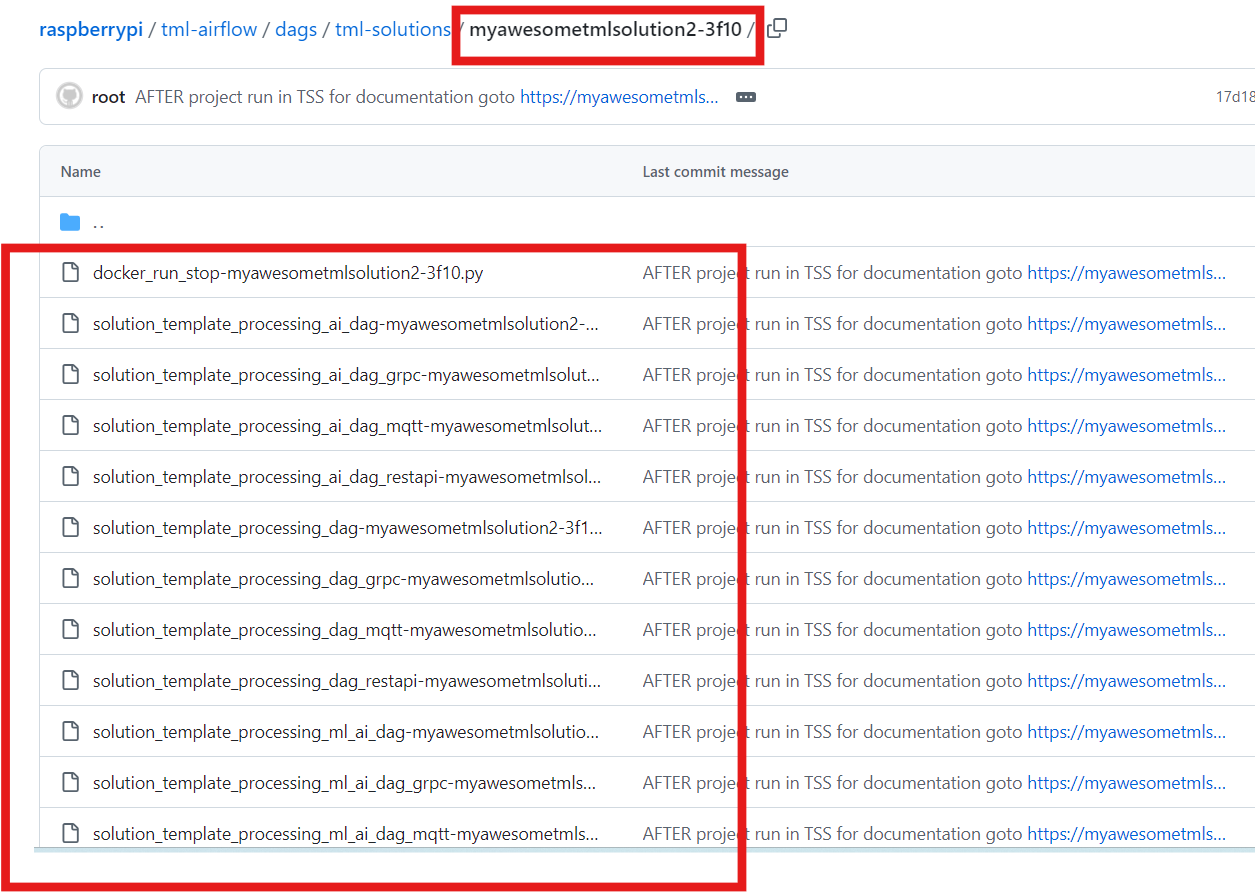
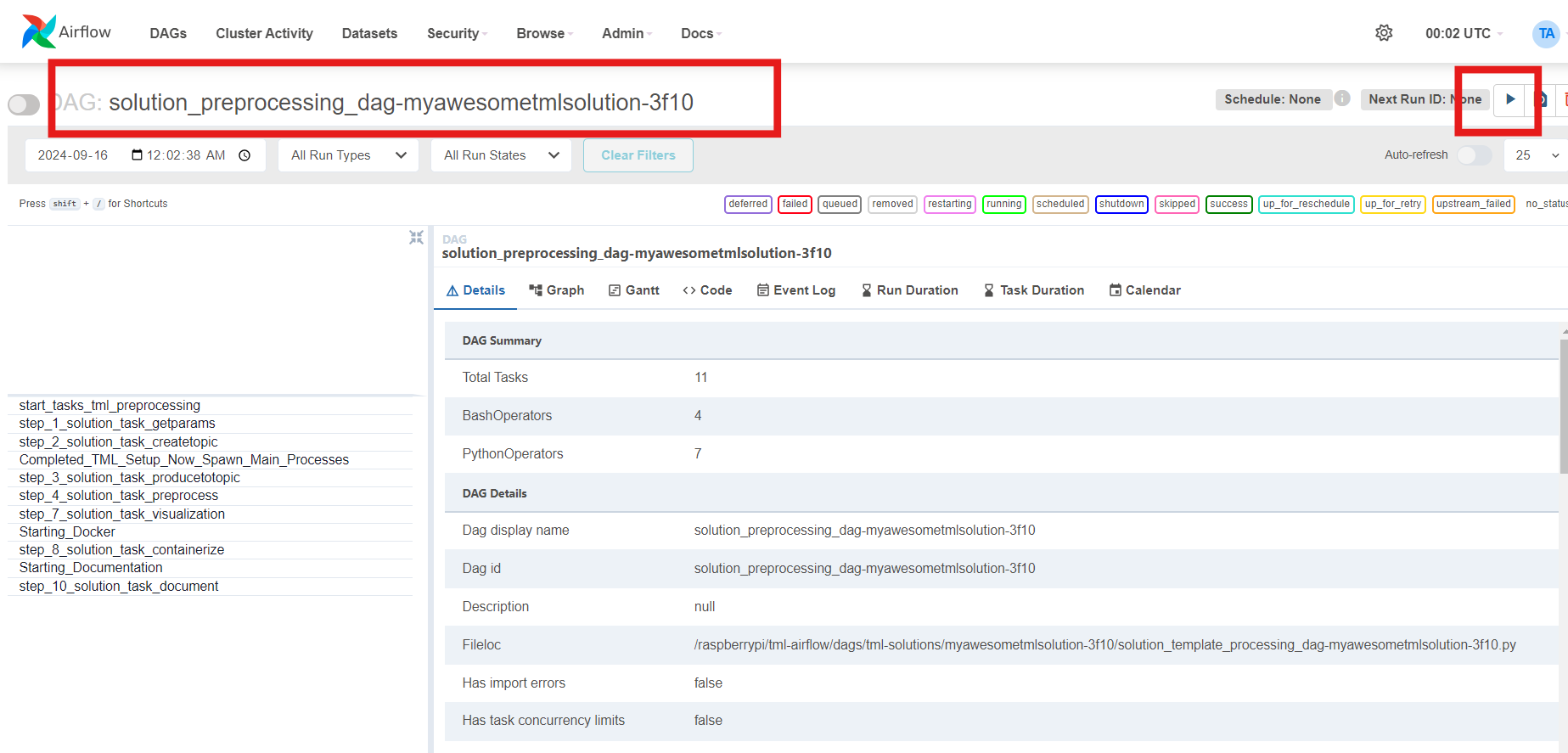
8.3. TML Solutions Can Be Built In 10 Steps Using Pre-Written DAGs (Directed Acyclic Graphs)
Users simply make configuration changes to the DAGs and build the solution. TML Studio will even automatically containerize your complete solution, and auto generate online documentation.
8.5. Pre-Written 10 Apache Airflow DAGs To Speed Up TML Solution Builds
The TML solution process with DAGS (explained in detail below). The entire TML solution build process is highly efficient; advanced, scalable, real-time TML solutions can be built in few hours with GenAI integrations!
The above process shows Ten (10) DAGs that are used to build advanced, scalable, real-time TML solutions with no-code - just configurations to the
DAGs.
Build Process starts with setting up system parameters for Initial TML Solution Setup. Users simply need to provide configuration information in the
following DAG:
Next, you want to start generating and producing data to the topics you creating and choose an Ingest Real-Time Data Method. TML provides you with FOUR
(4) methods to stream your own data from any device. This is done in the following DAGS - you need to CHOOSE ONE method:
You are also provided with an MQTT method - if you are using a MQTT broker for machine to machine communication.
After you have chosen an ingest data method and producing data, you are ready to Preprocess Real-Time Data - the next DAG performs this function:
STEP 4: Preprocesing Data: tml-system-step-4-kafka-preprocess-dag - Preprocessing is a very quick way to start generating insights from your real-
time in few minutes. All preprocessing is done in-memory and no external databases are needed, only Kafka. After you have preprocessed your data,
you can use this preprocessed data for machine learning - the next DAG performs this function.
preprocessed data for additional processing in machine learning. In the conventional machine learning sense, STEP 4 is like “feature engineering”
and STEP 4b is using the engineered features for a much deeper understanding of the data streaming variables.
files with machine learning outputs and incoprtaing “past memory” with sliding time windows. User can control how TML maintains past memory of past
sliding time windows. For details see How TML Maintains Past Memory of Events Using Sliding Time Windows
entity based machine learning models for
your real-time data. Note, TML will continuously build ML models are new data streams in. All machine learning is done in-memory and no external
databases are needed, only Kafka. As these models are trained on your real-time data - the next
DAG performs predictions.
learning training process in DAG 5.
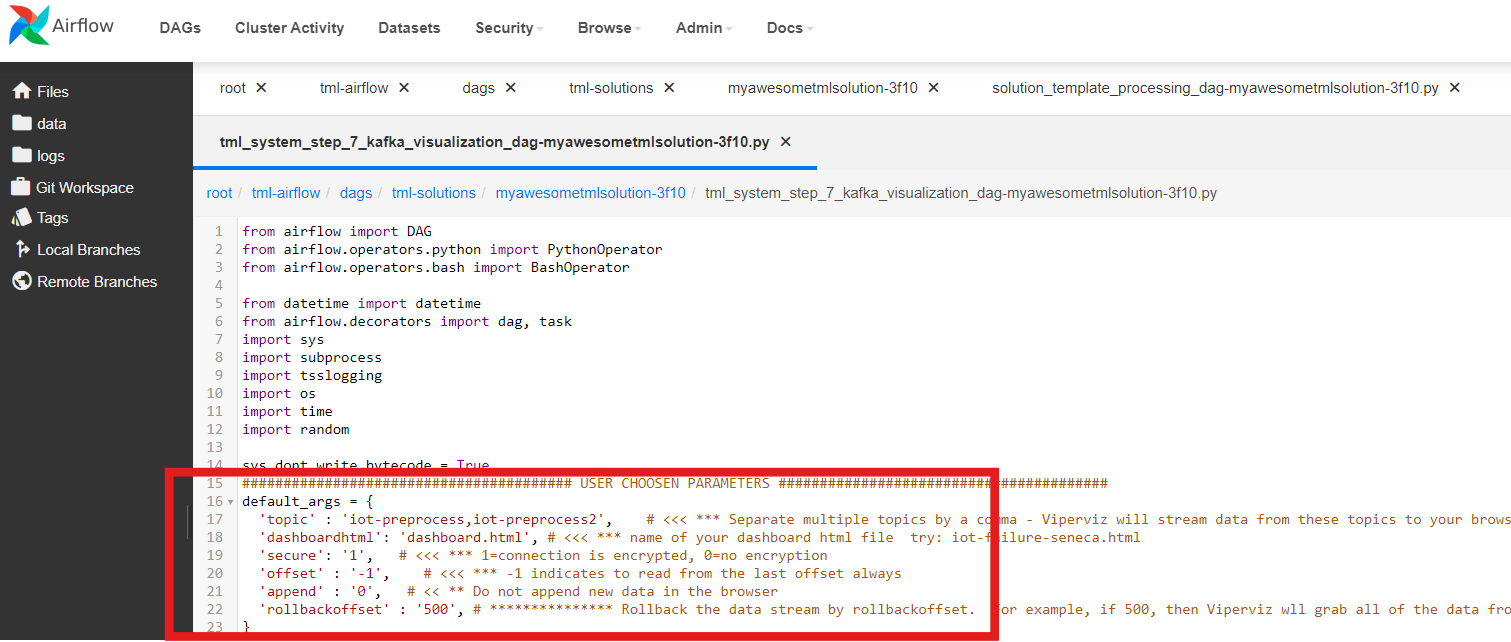
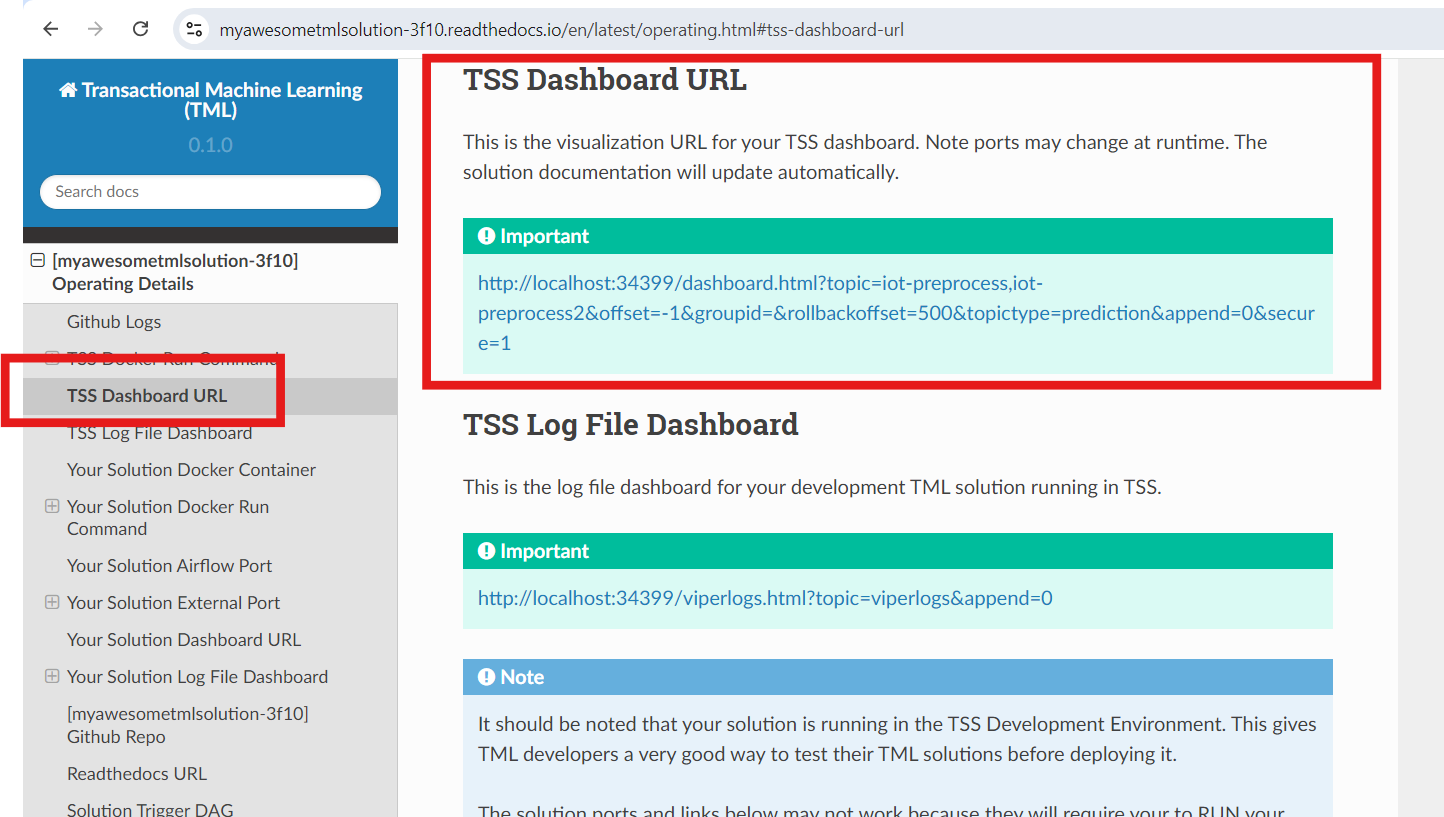
As predictions are being generated, you can stream these predictions to a real-time dashboard - the next DAG performs this function.
STEP 7: Real-Time Visualization: tml-system-step-7-kafka-visualization-dag - The visualization data are streamed directly from the TML solution
container over websockets to the
client browser, this eliminates any need for third-party visualization software. Now, that you have built the ENTIRE TML SOLUTION END-END you are
ready to deploy it to Docker - the next DAG performs this function.
YOU ARE DONE! You just build an advanced, scalable, end-end real-time solution and deployed it to Docker, integrated with AI and with online
documentation.
ENJOY!
DAGs (Directed Acyclic Graphs) are a powerful and easy way to build powerful (real-time) TML solutions quickly. Users are provided with the following DAGs:
Note
The numbers in the DAGs indicate solution process step. For example, step 2 is dependent on step 1.
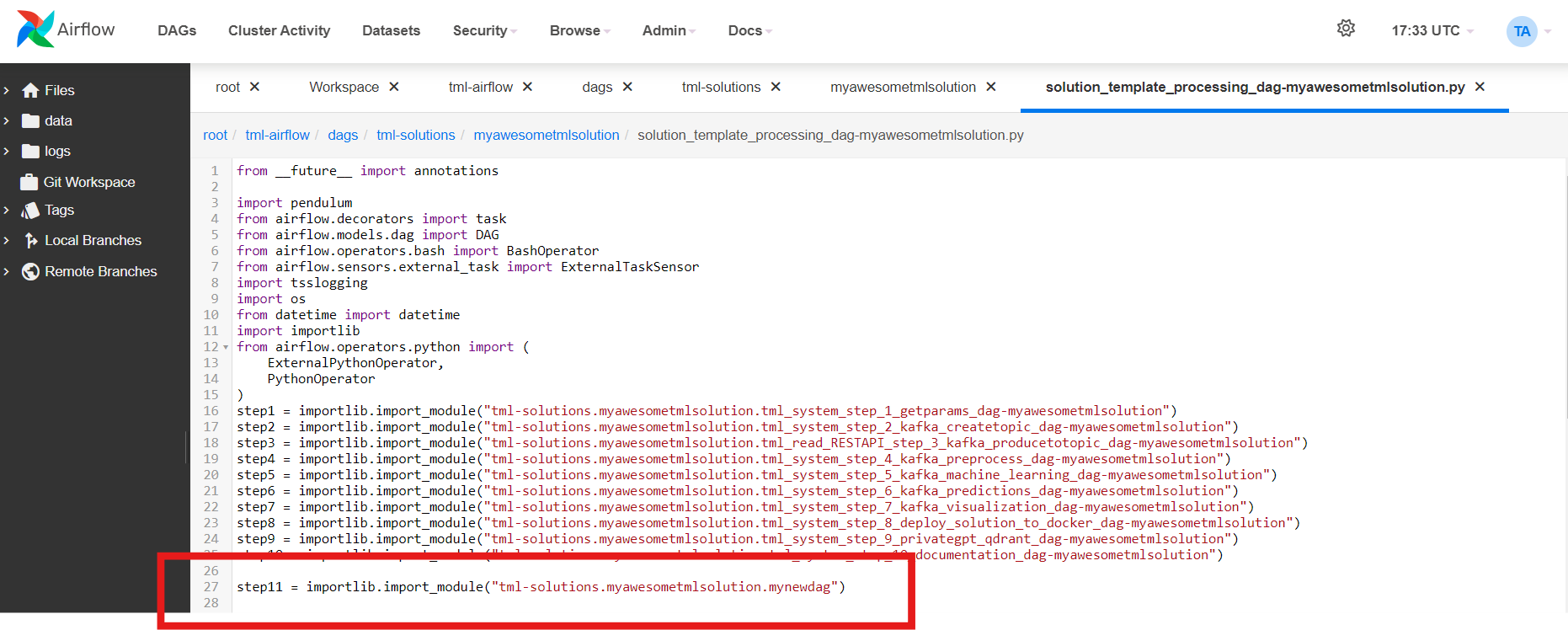
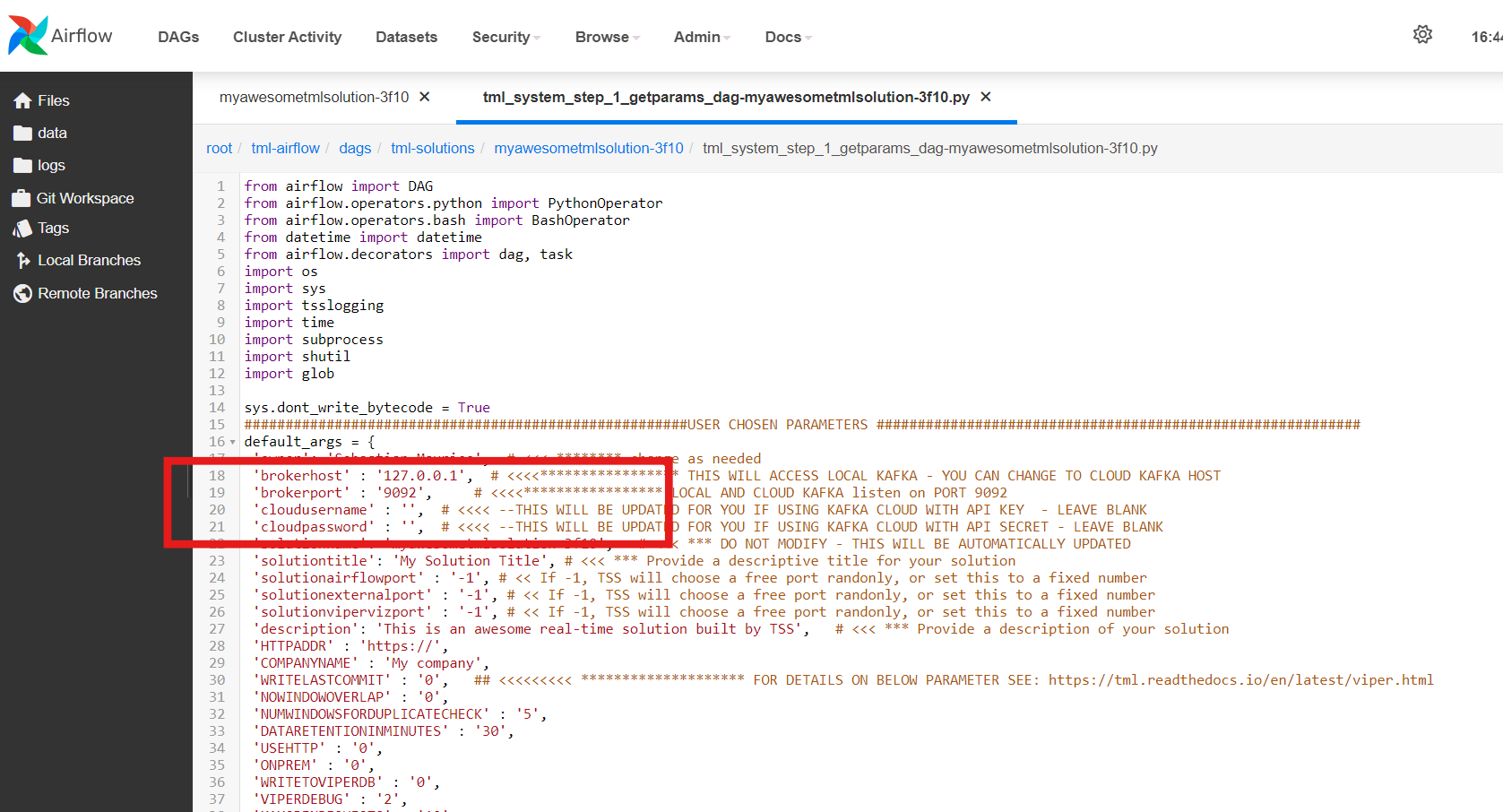
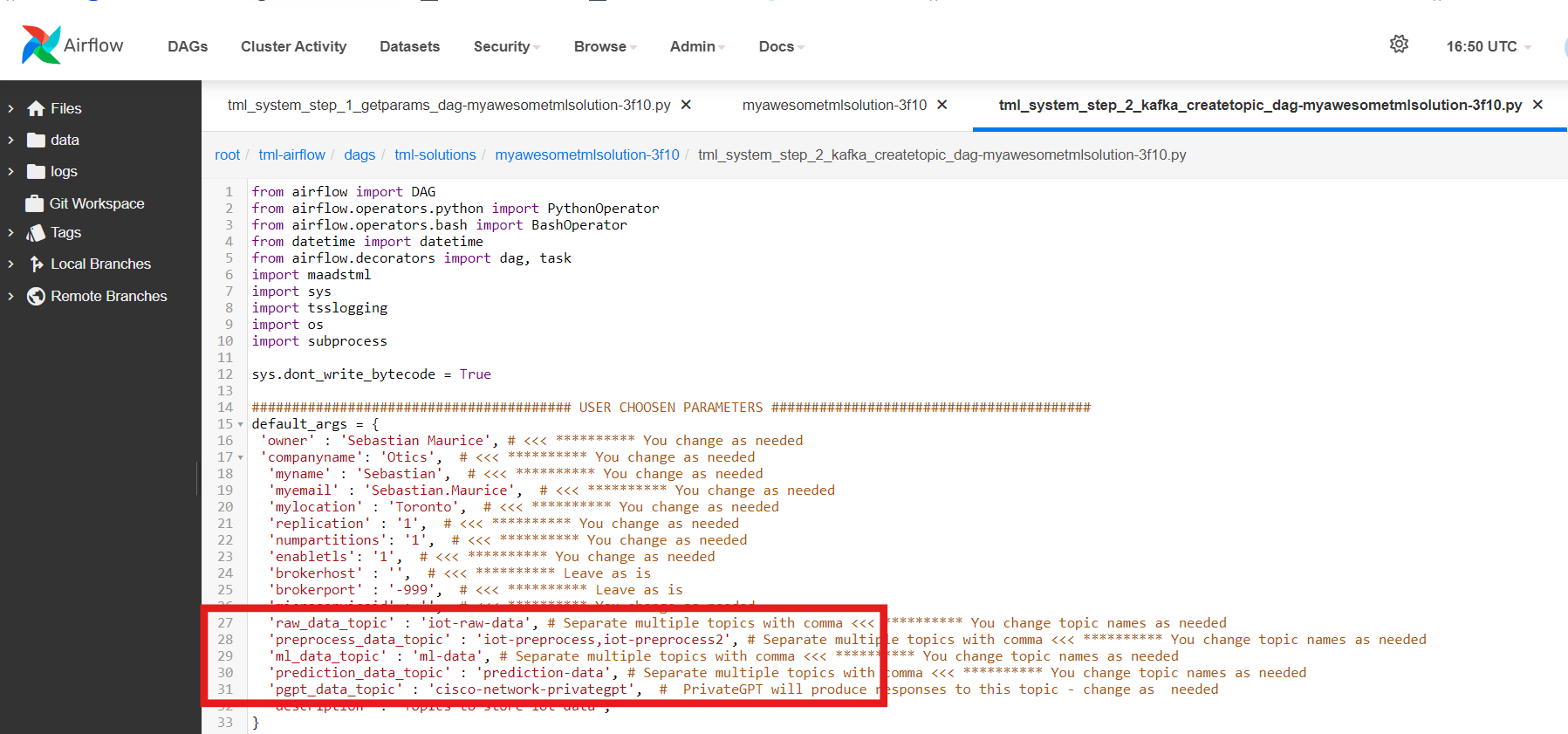
8.5.3. STEP 1: Get TML Core Params: tml_system_step_1_getparams_dag
Below is the complete definition of the tml_system_step_1_getparams_dag. Users only need to configure the code highlighted in the USER CHOSEN PARAMETERS.
Watch the YouTube video on dag configurations: YouTube video
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportosimportsysimporttssloggingimporttimeimportsubprocessimportshutilimportglobsys.dont_write_bytecode=True######################################################USER CHOSEN PARAMETERS ###########################################################default_args={'owner':'Sebastian Maurice',# <<< ******** change as needed'brokerhost':'127.0.0.1',# <<<<***************** THIS WILL ACCESS LOCAL KAFKA - YOU CAN CHANGE TO CLOUD KAFKA HOST'brokerport':'9092',# <<<<***************** LOCAL AND CLOUD KAFKA listen on PORT 9092'cloudusername':'',# <<<< --THIS WILL BE UPDATED FOR YOU IF USING KAFKA CLOUD WITH API KEY - LEAVE BLANK'cloudpassword':'',# <<<< --THIS WILL BE UPDATED FOR YOU IF USING KAFKA CLOUD WITH API SECRET - LEAVE BLANK'solutionname':'_mysolution_',# <<< *** DO NOT MODIFY - THIS WILL BE AUTOMATICALLY UPDATED'solutiontitle':'My Solution Title',# <<< *** Provide a descriptive title for your solution'solutionairflowport':'4040',# << If -1, TSS will choose a free port randonly, or set this to a fixed number'solutionexternalport':'5050',# << If -1, TSS will choose a free port randonly, or set this to a fixed number'solutionvipervizport':'6060',# << If -1, TSS will choose a free port randonly, or set this to a fixed number'description':'This is an awesome real-time solution built by TSS',# <<< *** Provide a description of your solution'HTTPADDR':'https://','COMPANYNAME':'My company','WRITELASTCOMMIT':'0',## <<<<<<<<< ******************** FOR DETAILS ON BELOW PARAMETER SEE: https://tml.readthedocs.io/en/latest/viper.html'NOWINDOWOVERLAP':'0','NUMWINDOWSFORDUPLICATECHECK':'5','DATARETENTIONINMINUTES':'1440','USEHTTP':'0','ONPREM':'0','WRITETOVIPERDB':'0','VIPERDEBUG':'2','MAXOPENREQUESTS':'10','LOGSTREAMTOPIC':'viperlogs','LOGSTREAMTOPICPARTITIONS':'1','LOGSTREAMTOPICREPLICATIONFACTOR':'3','LOGSENDTOEMAILS':'','LOGSENDTOEMAILSSUBJECT':'[VIPER]','LOGSENDTOEMAILFOOTER':'This e-mail is auto-generated by Transactional Machine Learning (TML) Technology Binaries: Viper, HPDE or Viperviz. For more information please contact your TML Administrator. Or, e-mail info@otics.ca for any questions or concerns regarding this e-mail. If you received this e-mail in error please delete it and inform your TML Admin or e-mail info@otics.ca, website: https://www.otics.ca. Thank you for using TML Data Stream Processing and Real-Time Transactional Machine Learning technologies.','LOGSENDINTERVALMINUTES':'500','LOGSENDINTERVALONLYERROR':'1','MAXTRAININGROWS':'300','MAXPREDICTIONROWS':'50','MAXPREPROCESSMESSAGES':'5000','MAXPERCMESSAGES':'5000','MAXCONSUMEMESSAGES':'5000','MAXVIPERVIZROLLBACKOFFSET':'','MAXVIPERVIZCONNECTIONS':'10','MAXURLQUERYSTRINGBYTES':'10000','MYSQLMAXLIFETIMEMINUTES':'4','MYSQLMAXCONN':'4','MYSQLMAXIDLE':'10','MYSQLHOSTNAME':'127.0.0.1:3306','KUBEMYSQLHOSTNAME':'mysql-service:3306',# this is the mysql service in kubernetes'MYSQLDB':'tmlids','MYSQLUSER':'root','SASLMECHANISM':'PLAIN','MINFORECASTACCURACY':'55','COMPRESSIONTYPE':'gzip','MAILSERVER':'',#i.e. smtp.broadband.rogers.com,'MAILPORT':'',#i.e. 465,'FROMADDR':'','SMTP_USERNAME':'','SMTP_PASSWORD':'','SMTP_SSLTLS':'true','SSL_CLIENT_CERT_FILE':'client.cer.pem','SSL_CLIENT_KEY_FILE':'client.key.pem','SSL_SERVER_CERT_FILE':'server.cer.pem','KUBERNETES':'0',}############################################################### DO NOT MODIFY BELOW ####################################################defreinitbinaries(sname):pywindowfiles=glob.glob("/tmux/pythonwindows_*")forfinpywindowfiles:try:withopen(f,'r',encoding='utf-8')asfile:data=file.readlines()fordindata:ifd!="":d=d.rstrip()v=subprocess.call(["tmux","kill-window","-t","{}".format(d)])os.remove(f)exceptExceptionase:print("ERROR=",e)passvizwindowfiles=glob.glob("/tmux/vipervizwindows_*")forfinvizwindowfiles:try:withopen(f,'r',encoding='utf-8')asfile:data=file.readlines()fordindata:d=d.rstrip()dsw=d.split(",")[0]dsp=d.split(",")[1]ifdsw!="":subprocess.call(["tmux","kill-window","-t","{}".format(dsw)])v=subprocess.call(["kill","-9","$(lsof -i:{} -t)".format(dsp)])time.sleep(1)os.remove(f)exceptExceptionase:pass# copy foldersshutil.copytree("/tss_readthedocs","/{}".format(sname),dirs_exist_ok=True)#remove local logstry:os.remove('/dagslocalbackup/logs.txt')exceptExceptionase:passdefupdateviperenv():# update ALLos.environ['tssbuild']="0"os.environ['tssdoc']="0"cloudusername=""cloudpassword=""if'KAFKACLOUDUSERNAME'inos.environ:cloudusername=os.environ['KAFKACLOUDUSERNAME']if'KAFKACLOUDPASSWORD'inos.environ:cloudpassword=os.environ['KAFKACLOUDPASSWORD']if'KAFKABROKERHOST'inos.environ:default_args['brokerhost']=os.environ['KAFKABROKERHOST']default_args['brokerport']=''if'SASLMECHANISM'inos.environ:default_args['SASLMECHANISM']=os.environ['SASLMECHANISM']if'127.0.0.1'indefault_args['brokerhost']:cloudusername=""cloudpassword=""if'KUBE'inos.environ:ifos.environ['KUBE']=="1":if'KAFKABROKERHOST'inos.environ:default_args['brokerhost']=os.environ['KAFKABROKERHOST']default_args['brokerport']=''if"KUBEBROKERHOST"inos.environ:buf=os.environ['KUBEBROKERHOST']sp=buf.split(":")default_args['brokerhost']=sp[0]default_args['brokerport']=sp[1]else:default_args['brokerhost']="kafka-service"filepaths=['/Viper-produce/viper.env','/Viper-preprocess/viper.env','/Viper-preprocess1/viper.env','/Viper-preprocess-pgpt/viper.env','/Viper-preprocess-agenticai/viper.env','/Viper-preprocess2/viper.env','/Viper-preprocess3/viper.env','/Viper-ml/viper.env','/Viper-predict/viper.env','/Viperviz/viper.env']formainfileinfilepaths:withopen(mainfile,'r',encoding='utf-8')asfile:data=file.readlines()r=0fordindata:ifd[0]=='#':r+=1continueif'KAFKA_CONNECT_BOOTSTRAP_SERVERS'ind:ifdefault_args['brokerport']=='':data[r]="KAFKA_CONNECT_BOOTSTRAP_SERVERS={}\n".format(default_args['brokerhost'])else:data[r]="KAFKA_CONNECT_BOOTSTRAP_SERVERS={}:{}\n".format(default_args['brokerhost'],default_args['brokerport'])if'CLOUD_USERNAME'ind:data[r]="CLOUD_USERNAME={}\n".format(cloudusername)if'CLOUD_PASSWORD'ind:data[r]="CLOUD_PASSWORD={}\n".format(cloudpassword)if'WRITELASTCOMMIT'ind:data[r]="WRITELASTCOMMIT={}\n".format(default_args['WRITELASTCOMMIT'])if'NOWINDOWOVERLAP'ind:data[r]="NOWINDOWOVERLAP={}\n".format(default_args['NOWINDOWOVERLAP'])if'NUMWINDOWSFORDUPLICATECHECK'ind:data[r]="NUMWINDOWSFORDUPLICATECHECK={}\n".format(default_args['NUMWINDOWSFORDUPLICATECHECK'])if'USEHTTP'ind:data[r]="USEHTTP={}\n".format(default_args['USEHTTP'])if'ONPREM'ind:data[r]="ONPREM={}\n".format(default_args['ONPREM'])if'WRITETOVIPERDB'ind:data[r]="WRITETOVIPERDB={}\n".format(default_args['WRITETOVIPERDB'])if'VIPERDEBUG'ind:data[r]="VIPERDEBUG={}\n".format(default_args['VIPERDEBUG'])if'MAXOPENREQUESTS'ind:data[r]="MAXOPENREQUESTS={}\n".format(default_args['MAXOPENREQUESTS'])if'LOGSTREAMTOPIC'ind:data[r]="LOGSTREAMTOPIC={}\n".format(default_args['LOGSTREAMTOPIC'])if'LOGSTREAMTOPICPARTITIONS'ind:data[r]="LOGSTREAMTOPICPARTITIONS={}\n".format(default_args['LOGSTREAMTOPICPARTITIONS'])if'LOGSTREAMTOPICREPLICATIONFACTOR'ind:data[r]="LOGSTREAMTOPICREPLICATIONFACTOR={}\n".format(default_args['LOGSTREAMTOPICREPLICATIONFACTOR'])if'LOGSENDTOEMAILS'ind:data[r]="LOGSENDTOEMAILS={}\n".format(default_args['LOGSENDTOEMAILS'])if'LOGSENDTOEMAILSSUBJECT'ind:data[r]="LOGSENDTOEMAILSSUBJECT={}\n".format(default_args['LOGSENDTOEMAILSSUBJECT'])if'LOGSENDTOEMAILFOOTER'ind:data[r]="LOGSENDTOEMAILFOOTER={}\n".format(default_args['LOGSENDTOEMAILFOOTER'])if'LOGSENDINTERVALMINUTES'ind:data[r]="LOGSENDINTERVALMINUTES={}\n".format(default_args['LOGSENDINTERVALMINUTES'])if'LOGSENDINTERVALONLYERROR'ind:data[r]="LOGSENDINTERVALONLYERROR={}\n".format(default_args['LOGSENDINTERVALONLYERROR'])if'MAXTRAININGROWS'ind:data[r]="MAXTRAININGROWS={}\n".format(default_args['MAXTRAININGROWS'])if'MAXPREDICTIONROWS'ind:data[r]="MAXPREDICTIONROWS={}\n".format(default_args['MAXPREDICTIONROWS'])if'MAXPREPROCESSMESSAGES'ind:data[r]="MAXPREPROCESSMESSAGES={}\n".format(default_args['MAXPREPROCESSMESSAGES'])if'MAXPERCMESSAGES'ind:data[r]="MAXPERCMESSAGES={}\n".format(default_args['MAXPERCMESSAGES'])if'MAXCONSUMEMESSAGES'ind:data[r]="MAXCONSUMEMESSAGES={}\n".format(default_args['MAXCONSUMEMESSAGES'])if'MAXVIPERVIZROLLBACKOFFSET'ind:data[r]="MAXVIPERVIZROLLBACKOFFSET={}\n".format(default_args['MAXVIPERVIZROLLBACKOFFSET'])if'MAXVIPERVIZCONNECTIONS'ind:data[r]="MAXVIPERVIZCONNECTIONS={}\n".format(default_args['MAXVIPERVIZCONNECTIONS'])if'MAXURLQUERYSTRINGBYTES'ind:data[r]="MAXURLQUERYSTRINGBYTES={}\n".format(default_args['MAXURLQUERYSTRINGBYTES'])if'MYSQLMAXLIFETIMEMINUTES'ind:data[r]="MYSQLMAXLIFETIMEMINUTES={}\n".format(default_args['MYSQLMAXLIFETIMEMINUTES'])if'MYSQLMAXCONN'ind:data[r]="MYSQLMAXCONN={}\n".format(default_args['MYSQLMAXCONN'])if'MYSQLMAXIDLE'ind:data[r]="MYSQLMAXIDLE={}\n".format(default_args['MYSQLMAXIDLE'])if'SASLMECHANISM'ind:data[r]="SASLMECHANISM={}\n".format(default_args['SASLMECHANISM'])if'MINFORECASTACCURACY'ind:data[r]="MINFORECASTACCURACY={}\n".format(default_args['MINFORECASTACCURACY'])if'COMPRESSIONTYPE'ind:data[r]="COMPRESSIONTYPE={}\n".format(default_args['COMPRESSIONTYPE'])if'MAILSERVER'ind:data[r]="MAILSERVER={}\n".format(default_args['MAILSERVER'])if'MAILPORT'ind:data[r]="MAILPORT={}\n".format(default_args['MAILPORT'])if'FROMADDR'ind:data[r]="FROMADDR={}\n".format(default_args['FROMADDR'])if'SMTP_USERNAME'ind:data[r]="SMTP_USERNAME={}\n".format(default_args['SMTP_USERNAME'])if'SMTP_PASSWORD'ind:data[r]="SMTP_PASSWORD={}\n".format(default_args['SMTP_PASSWORD'])if'SMTP_SSLTLS'ind:data[r]="SMTP_SSLTLS={}\n".format(default_args['SMTP_SSLTLS'])if'SSL_CLIENT_CERT_FILE'ind:data[r]="SSL_CLIENT_CERT_FILE={}\n".format(default_args['SSL_CLIENT_CERT_FILE'])if'SSL_CLIENT_KEY_FILE'ind:data[r]="SSL_CLIENT_KEY_FILE={}\n".format(default_args['SSL_CLIENT_KEY_FILE'])if'SSL_SERVER_CERT_FILE'ind:data[r]="SSL_SERVER_CERT_FILE={}\n".format(default_args['SSL_SERVER_CERT_FILE'])if'KUBERNETES'ind:data[r]="KUBERNETES={}\n".format(default_args['KUBERNETES'])if'COMPANYNAME'ind:data[r]="COMPANYNAME={}\n".format(default_args['COMPANYNAME'])if'MYSQLHOSTNAME'ind:if"KUBE"inos.environ:ifos.environ["KUBE"]=="1":data[r]="MYSQLHOSTNAME={}\n".format(default_args['KUBEMYSQLHOSTNAME'])else:data[r]="MYSQLHOSTNAME={}\n".format(default_args['MYSQLHOSTNAME'])else:data[r]="MYSQLHOSTNAME={}\n".format(default_args['MYSQLHOSTNAME'])if'MYSQLDB'ind:data[r]="MYSQLDB={}\n".format(default_args['MYSQLDB'])if'MYSQLUSER'ind:data[r]="MYSQLUSER={}\n".format(default_args['MYSQLUSER'])r+=1withopen(mainfile,'w',encoding='utf-8')asfile:file.writelines(data)subprocess.call("/tmux/starttml.sh",shell=True)time.sleep(3)defgetparams(**context):args=default_argsVIPERHOST=""VIPERPORT=""HTTPADDR=args['HTTPADDR']HPDEHOST=""HPDEPORT=""VIPERTOKEN=""HPDEHOSTPREDICT=""HPDEPORTPREDICT=""tsslogging.locallogs("INFO","STEP 1: Build started")try:ifos.environ['TSS']=="1":if'READTHEDOCS'inos.environ:iflen(os.environ['READTHEDOCS'])<4:sys.exit()f=open("/tmux/rd4.txt","w")rd=os.environ['READTHEDOCS']f.write(rd[:4])f.close()else:sys.exit()exceptExceptionase:passifos.environ['TSS']=="1":try:shutil.rmtree("/rawdata/rtms")exceptExceptionase:passtry:withopen("/tmux/step5.txt","r")asf:dirbuf=f.read()shutil.rmtree(dirbuf)exceptExceptionase:passsd=context['dag'].dag_idpname=args['solutionname']sname=tsslogging.rtdsolution(pname,sd)try:f=open("/tmux/step1projectname.txt","w")f.write(pname)f.close()exceptExceptionase:passtry:f=open("/tmux/step1solution.txt","w")f.write(sname)f.close()exceptExceptionase:passif'step1description'inos.environ:desc=os.environ['step1description']else:desc=args['description']if'step1solutiontitle'inos.environ:stitle=os.environ['step1solutiontitle']else:stitle=args['solutiontitle']brokerhost=args['brokerhost']brokerport=args['brokerport']reinitbinaries(sname)updateviperenv()withopen("/Viper-produce/admin.tok","r")asf:VIPERTOKEN=f.read()ifVIPERHOST=="":withopen('/Viper-produce/viper.txt','r')asf:output=f.read()VIPERHOST=output.split(",")[0]VIPERPORT=output.split(",")[1]withopen('/Viper-preprocess/viper.txt','r')asf:output=f.read()VIPERHOSTPREPROCESS=output.split(",")[0]VIPERPORTPREPROCESS=output.split(",")[1]withopen('/Viper-preprocess1/viper.txt','r')asf:output=f.read()VIPERHOSTPREPROCESS1=output.split(",")[0]VIPERPORTPREPROCESS1=output.split(",")[1]withopen('/Viper-preprocess2/viper.txt','r')asf:output=f.read()VIPERHOSTPREPROCESS2=output.split(",")[0]VIPERPORTPREPROCESS2=output.split(",")[1]withopen('/Viper-preprocess3/viper.txt','r')asf:output=f.read()VIPERHOSTPREPROCESS3=output.split(",")[0]VIPERPORTPREPROCESS3=output.split(",")[1]withopen('/Viper-preprocess-pgpt/viper.txt','r')asf:output=f.read()VIPERHOSTPREPROCESSPGPT=output.split(",")[0]VIPERPORTPREPROCESSPGPT=output.split(",")[1]withopen('/Viper-preprocess-agenticai/viper.txt','r')asf:output=f.read()VIPERHOSTPREPROCESSAGENTICAI=output.split(",")[0]VIPERPORTPREPROCESSAGENTICAI=output.split(",")[1]withopen('/Viper-ml/viper.txt','r')asf:output=f.read()VIPERHOSTML=output.split(",")[0]VIPERPORTML=output.split(",")[1]withopen('/Viper-predict/viper.txt','r')asf:output=f.read()VIPERHOSTPREDICT=output.split(",")[0]VIPERPORTPREDICT=output.split(",")[1]withopen('/Hpde/hpde.txt','r')asf:output=f.read()HPDEHOST=output.split(",")[0]HPDEPORT=output.split(",")[1]withopen('/Hpde-predict/hpde.txt','r')asf:output=f.read()HPDEHOSTPREDICT=output.split(",")[0]HPDEPORTPREDICT=output.split(",")[1]if'CHIP'inos.environ:chip=os.environ['CHIP']chip=chip.lower()else:chip='amd64'if'VIPERVIZPORT'inos.environ:ifos.environ['VIPERVIZPORT']!=''andos.environ['VIPERVIZPORT']!='-1':vipervizport=int(os.environ['VIPERVIZPORT'])else:vipervizport=tsslogging.getfreeport()else:vipervizport=tsslogging.getfreeport()# Check the solution airflow port and see if user modfifed port in kubernetesifdefault_args['solutionairflowport']!='-1':solutionairflowport=int(default_args['solutionairflowport'])if'KUBE'inos.environ:ifos.environ['KUBE']=='1'andint(os.environ['SOLUTIONAIRFLOWPORT'])!='-1':solutionairflowport=int(os.environ['SOLUTIONAIRFLOWPORT'])else:if'KUBE'inos.environ:ifos.environ['KUBE']=="0":solutionairflowport=tsslogging.getfreeport()elifint(os.environ['SOLUTIONAIRFLOWPORT'])!='-1':solutionairflowport=int(os.environ['SOLUTIONAIRFLOWPORT'])else:solutionairflowport=tsslogging.getfreeport()else:solutionairflowport=tsslogging.getfreeport()# Check the solution external port and see if user modfifed port in kubernetesifdefault_args['solutionexternalport']!='-1':solutionexternalport=int(default_args['solutionexternalport'])if'KUBE'inos.environ:ifos.environ['KUBE']=='1'andint(os.environ['SOLUTIONEXTERNALPORT'])!='-1':solutionexternalport=int(os.environ['SOLUTIONEXTERNALPORT'])else:if'KUBE'inos.environ:ifos.environ['KUBE']=="0":solutionexternalport=tsslogging.getfreeport()elifint(os.environ['SOLUTIONEXTERNALPORT'])!='-1':solutionexternalport=int(os.environ['SOLUTIONEXTERNALPORT'])else:solutionexternalport=tsslogging.getfreeport()else:solutionexternalport=tsslogging.getfreeport()# Check the solution visualization port and see if user modfifed port in kubernetesifdefault_args['solutionvipervizport']!='-1':solutionvipervizport=int(default_args['solutionvipervizport'])if'KUBE'inos.environ:ifos.environ['KUBE']=='1'andint(os.environ['SOLUTIONVIPERVIZPORT'])!='-1':solutionvipervizport=int(os.environ['SOLUTIONVIPERVIZPORT'])else:if'KUBE'inos.environ:ifos.environ['KUBE']=="0":solutionvipervizport=tsslogging.getfreeport()elifint(os.environ['SOLUTIONVIPERVIZPORT'])!='-1':solutionvipervizport=int(os.environ['SOLUTIONVIPERVIZPORT'])else:solutionvipervizport=tsslogging.getfreeport()else:solutionvipervizport=tsslogging.getfreeport()if'AIRFLOWPORT'inos.environ:airflowport=os.environ['AIRFLOWPORT']else:airflowport=tsslogging.getfreeport()externalport=VIPERPORTif'EXTERNALPORT'inos.environ:ifos.environ['EXTERNALPORT']!="-1":externalport=os.environ['EXTERNALPORT']tss=os.environ['TSS']task_instance=context['task_instance']iftss=="1":task_instance.xcom_push(key="{}_SOLUTIONEXTERNALPORT".format(sname),value="_{}".format(solutionexternalport))task_instance.xcom_push(key="{}_SOLUTIONVIPERVIZPORT".format(sname),value="_{}".format(solutionvipervizport))task_instance.xcom_push(key="{}_SOLUTIONAIRFLOWPORT".format(sname),value="_{}".format(solutionairflowport))else:task_instance.xcom_push(key="{}_SOLUTIONEXTERNALPORT".format(sname),value="_{}".format(os.environ['SOLUTIONEXTERNALPORT']))task_instance.xcom_push(key="{}_SOLUTIONVIPERVIZPORT".format(sname),value="_{}".format(os.environ['SOLUTIONVIPERVIZPORT']))task_instance.xcom_push(key="{}_SOLUTIONAIRFLOWPORT".format(sname),value="_{}".format(os.environ['SOLUTIONAIRFLOWPORT']))# killports()if'MQTTUSERNAME'inos.environ:task_instance.xcom_push(key="{}_MQTTUSERNAME".format(sname),value=os.environ['MQTTUSERNAME'])else:task_instance.xcom_push(key="{}_MQTTUSERNAME".format(sname),value="")if'MQTTPASSWORD'inos.environ:task_instance.xcom_push(key="{}_MQTTPASSWORD".format(sname),value=os.environ['MQTTPASSWORD'])else:task_instance.xcom_push(key="{}_MQTTPASSWORD".format(sname),value="")if'KAFKACLOUDUSERNAME'inos.environ:task_instance.xcom_push(key="{}_KAFKACLOUDUSERNAME".format(sname),value=os.environ['KAFKACLOUDUSERNAME'])else:task_instance.xcom_push(key="{}_KAFKACLOUDUSERNAME".format(sname),value="")if'KAFKACLOUDPASSWORD'inos.environ:task_instance.xcom_push(key="{}_KAFKACLOUDPASSWORD".format(sname),value=os.environ['KAFKACLOUDPASSWORD'])else:task_instance.xcom_push(key="{}_KAFKACLOUDPASSWORD".format(sname),value="")task_instance.xcom_push(key="{}_TSS".format(sname),value="_{}".format(tss))task_instance.xcom_push(key="{}_EXTERNALPORT".format(sname),value="_{}".format(externalport))task_instance.xcom_push(key="{}_AIRFLOWPORT".format(sname),value="_{}".format(airflowport))task_instance.xcom_push(key="{}_VIPERVIZPORT".format(sname),value="_{}".format(vipervizport))task_instance.xcom_push(key="{}_VIPERTOKEN".format(sname),value=VIPERTOKEN)task_instance.xcom_push(key="{}_VIPERHOST".format(sname),value=VIPERHOST)task_instance.xcom_push(key="{}_VIPERPORT".format(sname),value="_{}".format(VIPERPORT))task_instance.xcom_push(key="{}_VIPERHOSTPRODUCE".format(sname),value=VIPERHOST)task_instance.xcom_push(key="{}_VIPERPORTPRODUCE".format(sname),value="_{}".format(VIPERPORT))task_instance.xcom_push(key="{}_VIPERHOSTPREPROCESS".format(sname),value=VIPERHOSTPREPROCESS)task_instance.xcom_push(key="{}_VIPERPORTPREPROCESS".format(sname),value="_{}".format(VIPERPORTPREPROCESS))task_instance.xcom_push(key="{}_VIPERHOSTPREPROCESS1".format(sname),value=VIPERHOSTPREPROCESS1)task_instance.xcom_push(key="{}_VIPERPORTPREPROCESS1".format(sname),value="_{}".format(VIPERPORTPREPROCESS1))task_instance.xcom_push(key="{}_VIPERHOSTPREPROCESS2".format(sname),value=VIPERHOSTPREPROCESS2)task_instance.xcom_push(key="{}_VIPERPORTPREPROCESS2".format(sname),value="_{}".format(VIPERPORTPREPROCESS2))task_instance.xcom_push(key="{}_VIPERHOSTPREPROCESS3".format(sname),value=VIPERHOSTPREPROCESS3)task_instance.xcom_push(key="{}_VIPERPORTPREPROCESS3".format(sname),value="_{}".format(VIPERPORTPREPROCESS3))task_instance.xcom_push(key="{}_VIPERHOSTPREPROCESSPGPT".format(sname),value=VIPERHOSTPREPROCESSPGPT)task_instance.xcom_push(key="{}_VIPERPORTPREPROCESSPGPT".format(sname),value="_{}".format(VIPERPORTPREPROCESSPGPT))task_instance.xcom_push(key="{}_VIPERHOSTPREPROCESSAGENTICAI".format(sname),value=VIPERHOSTPREPROCESSAGENTICAI)task_instance.xcom_push(key="{}_VIPERPORTPREPROCESSAGENTICAI".format(sname),value="_{}".format(VIPERPORTPREPROCESSAGENTICAI))task_instance.xcom_push(key="{}_VIPERHOSTML".format(sname),value=VIPERHOSTML)task_instance.xcom_push(key="{}_VIPERPORTML".format(sname),value="_{}".format(VIPERPORTML))task_instance.xcom_push(key="{}_VIPERHOSTPREDICT".format(sname),value=VIPERHOSTPREDICT)task_instance.xcom_push(key="{}_VIPERPORTPREDICT".format(sname),value="_{}".format(VIPERPORTPREDICT))task_instance.xcom_push(key="{}_HTTPADDR".format(sname),value=HTTPADDR)task_instance.xcom_push(key="{}_HPDEHOST".format(sname),value=HPDEHOST)task_instance.xcom_push(key="{}_HPDEPORT".format(sname),value="_{}".format(HPDEPORT))task_instance.xcom_push(key="{}_HPDEHOSTPREDICT".format(sname),value=HPDEHOSTPREDICT)task_instance.xcom_push(key="{}_HPDEPORTPREDICT".format(sname),value="_{}".format(HPDEPORTPREDICT))task_instance.xcom_push(key="{}_solutionname".format(sd),value=sname)task_instance.xcom_push(key="{}_projectname".format(sd),value=pname)task_instance.xcom_push(key="{}_solutiondescription".format(sname),value=desc)task_instance.xcom_push(key="{}_solutiontitle".format(sname),value=stitle)task_instance.xcom_push(key="{}_containername".format(sname),value='')task_instance.xcom_push(key="{}_brokerhost".format(sname),value=brokerhost)task_instance.xcom_push(key="{}_brokerport".format(sname),value="_{}".format(brokerport))task_instance.xcom_push(key="{}_chip".format(sname),value=chip)tsslogging.locallogs("INFO","STEP 1: completed - TML system parameters successfully gathered")
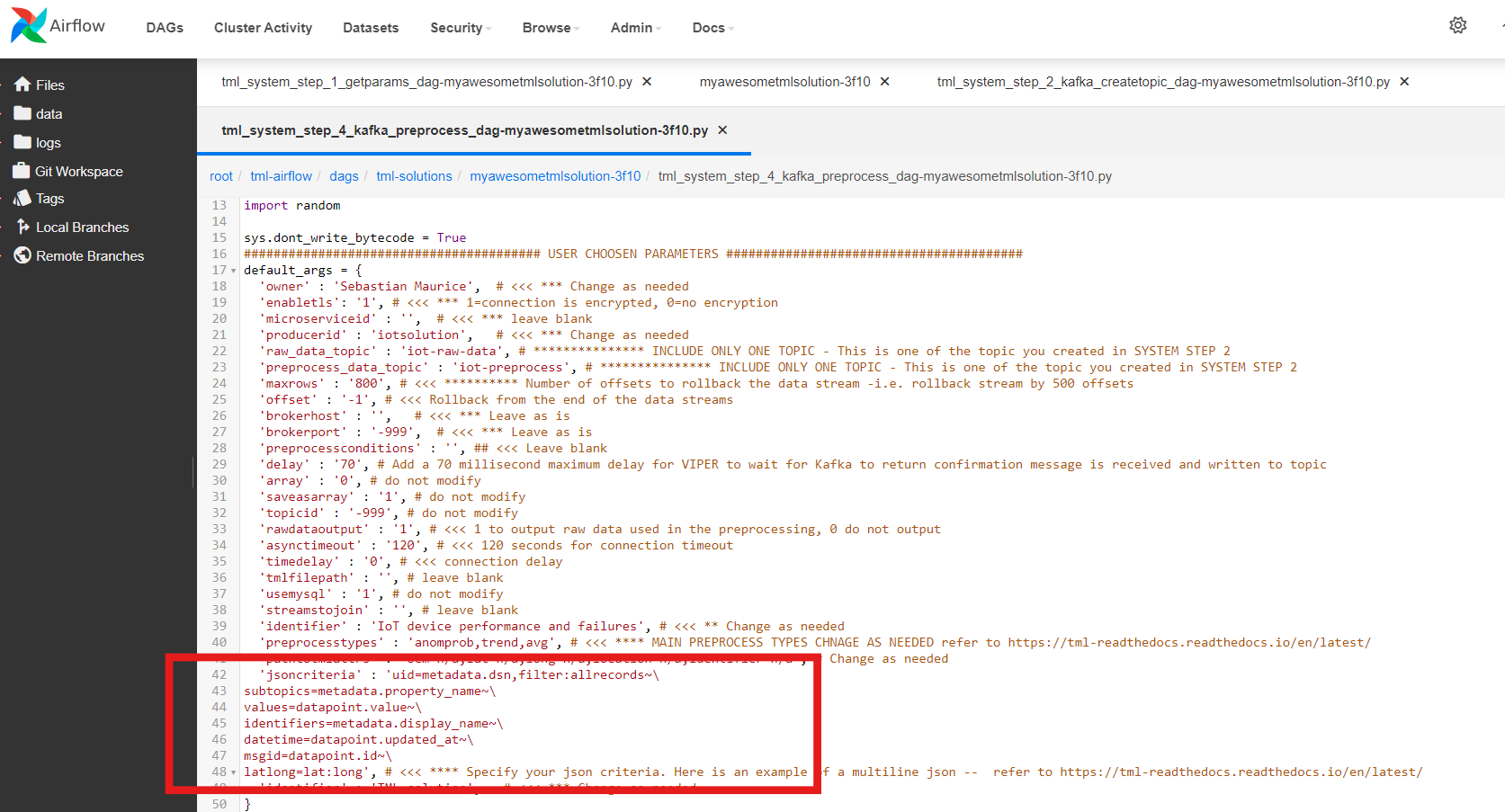
Below is the complete definition of the tml_system_step_2_kafka_createtopic_dag that creates all the topics for your solution. Users only need to configure the code highlighted in the USER CHOSEN PARAMETERS.
Tip
Watch the YouTube video for Step 2 dag configurations. YouTube Video
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportmaadstmlimportsysimporttssloggingimportosimportsubprocesssys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice',# <<< ********** You change as needed'companyname':'Otics',# <<< ********** You change as needed'myname':'Sebastian',# <<< ********** You change as needed'myemail':'Sebastian.Maurice',# <<< ********** You change as needed'mylocation':'Toronto',# <<< ********** You change as needed'replication':'1',# <<< ********** You change as needed'numpartitions':'1',# <<< ********** You change as needed'enabletls':'1',# <<< ********** You change as needed'brokerhost':'',# <<< ********** Leave as is'brokerport':'-999',# <<< ********** Leave as is'microserviceid':'',# <<< ********** You change as needed'raw_data_topic':'iot-raw-data',# Separate multiple topics with comma <<< ********** You change topic names as needed'preprocess_data_topic':'iot-preprocess,iot-preprocess2',# Separate multiple topics with comma <<< ********** You change topic names as needed'ml_data_topic':'ml-data',# Separate multiple topics with comma <<< ********** You change topic names as needed'prediction_data_topic':'prediction-data',# Separate multiple topics with comma <<< ********** You change topic names as needed'pgpt_data_topic':'cisco-network-privategpt',# PrivateGPT will produce responses to this topic - change as needed'description':'Topics to store iot data',}######################################## DO NOT MODIFY BELOW #############################################defdeletetopics(topic):if'KUBE'inos.environ:ifos.environ['KUBE']=="1":returnbuf="/Kafka/kafka_2.13-3.0.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic {} --delete".format(topic)proc=subprocess.run(buf,shell=True)#proc.terminate()#proc.wait()repo=tsslogging.getrepo()tsslogging.tsslogit("Deleting topic {} in {}".format(topic,os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")defsetupkafkatopics(**context):# Set personal datatsslogging.locallogs("INFO","STEP 2: Create topics started")args=default_argscompanyname=args['companyname']myname=args['myname']myemail=args['myemail']mylocation=args['mylocation']description=args['description']# Replication factor for Kafka redundancyreplication=int(args['replication'])# Number of partitions for joined topicnumpartitions=int(args['numpartitions'])# Enable SSL/TLS communication with Kafkaenabletls=int(args['enabletls'])# If brokerhost is empty then this function will use the brokerhost address in yourbrokerhost=args['brokerhost']# If this is -999 then this function uses the port address for Kafka in VIPER.ENV in the# field 'KAFKA_CONNECT_BOOTSTRAP_SERVERS'brokerport=int(args['brokerport'])# If you are using a reverse proxy to reach VIPER then you can put it here - otherwise if# empty then no reverse proxy is being usedmicroserviceid=args['microserviceid']if'step2raw_data_topic'inos.environ:args['raw_data_topic']=os.environ['step2raw_data_topic']if'step2preprocess_data_topic'inos.environ:args['preprocess_data_topic']=os.environ['step2preprocess_data_topic']raw_data_topic=args['raw_data_topic']preprocess_data_topic=args['preprocess_data_topic']ml_data_topic=args['ml_data_topic']prediction_data_topic=args['prediction_data_topic']sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPRODUCE".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPRODUCE".format(sname))mainbroker=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_brokerhost".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))ti=context['task_instance']ti.xcom_push(key="{}_companyname".format(sname),value=companyname)ti.xcom_push(key="{}_myname".format(sname),value=myname)ti.xcom_push(key="{}_myemail".format(sname),value=myemail)ti.xcom_push(key="{}_mylocation".format(sname),value=mylocation)ti.xcom_push(key="{}_replication".format(sname),value="_{}".format(replication))ti.xcom_push(key="{}_numpartitions".format(sname),value="_{}".format(numpartitions))ti.xcom_push(key="{}_enabletls".format(sname),value="_{}".format(enabletls))ti.xcom_push(key="{}_microserviceid".format(sname),value=microserviceid)ti.xcom_push(key="{}_raw_data_topic".format(sname),value=raw_data_topic)ti.xcom_push(key="{}_preprocess_data_topic".format(sname),value=preprocess_data_topic)ti.xcom_push(key="{}_ml_data_topic".format(sname),value=ml_data_topic)ti.xcom_push(key="{}_prediction_data_topic".format(sname),value=prediction_data_topic)############################################################################################################## CREATE TOPIC TO STORE TRAINED PARAMS FROM ALGORITHMtopickeys=['raw_data_topic','preprocess_data_topic','ml_data_topic','prediction_data_topic','pgpt_data_topic']VIPERHOSTMAIN="{}{}".format(HTTPADDR,VIPERHOST)ptarr=""forkintopickeys:producetotopic=args[k]description=args['description']ifproducetotopic!="":ptarr=ptarr+producetotopic.strip()+","topicsarr=producetotopic.split(",")fortopicintopicsarr:iftopic!=''and"127.0.0.1"inmainbroker:try:deletetopics(topic)exceptExceptionase:print("ERROR: ",e)continueif'127.0.0.1'inmainbroker:replication=1#for topic in topicsarr:ifptarr!='':ptarr=ptarr[:-1]print("Creating topic=",ptarr)try:result=maadstml.vipercreatetopic(VIPERTOKEN,VIPERHOSTMAIN,VIPERPORT[1:],ptarr,companyname,myname,myemail,mylocation,description,enabletls,brokerhost,brokerport,numpartitions,replication,microserviceid='')exceptExceptionase:tsslogging.locallogs("ERROR","STEP 2: Cannot create topic {} in {} - {}".format(ptarr,os.path.basename(__file__),e))repo=tsslogging.getrepo()tsslogging.tsslogit("Cannot create topic {} in {} - {}".format(topic,os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")tsslogging.locallogs("INFO","STEP 2: Completed")
You must CHOOSE how you want to ingest data and produce to a Kafka topic.
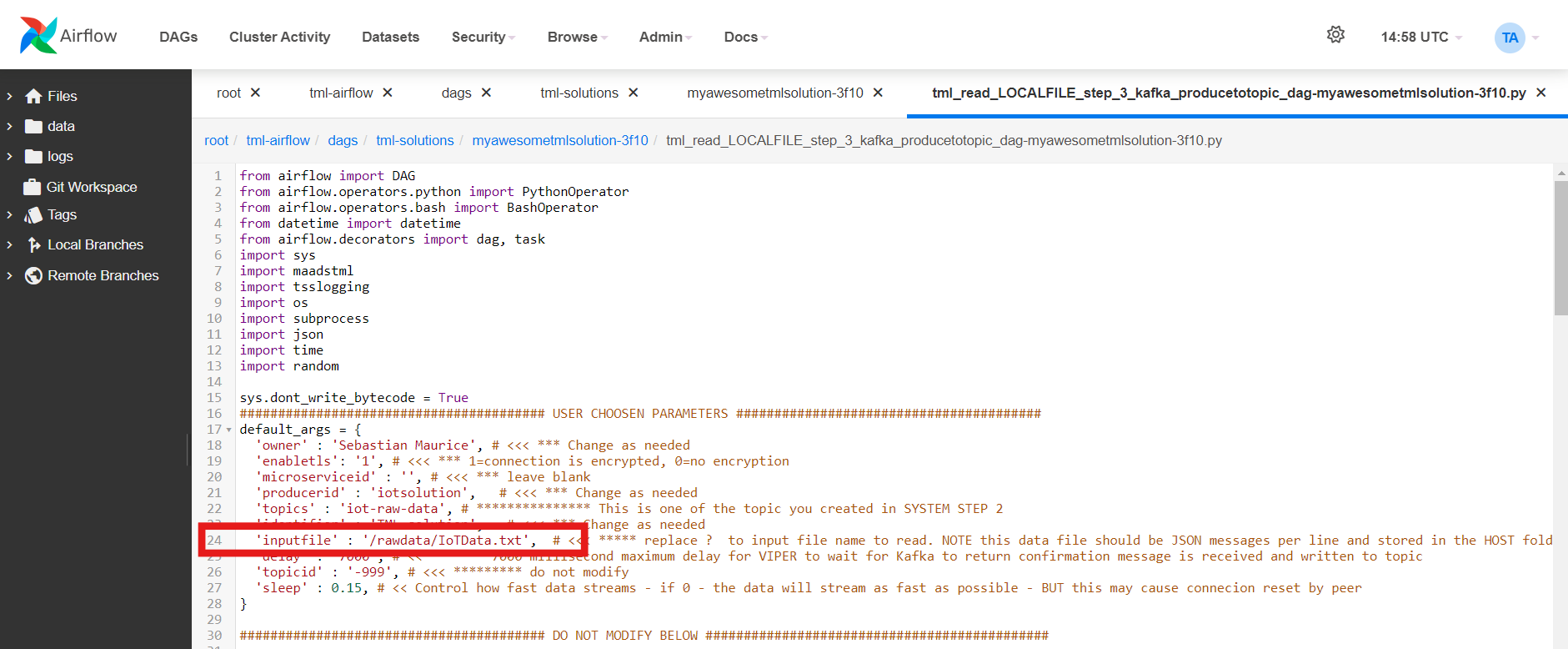
TML solution provides 4 (FOUR) ways to ingest data and produce to a topic: MQTT, gRPC, RESTAPI, LOCALFILE. The following DAGs in the table are SERVER
files. These server files wait for connections from the client files. For further convenience, client files are provides to access the server DAGs below.
Tip
The client examples for LOCALFILE, REST, MQTT, gRPC the data file can be download from Github:
8.5.5.2. STEP 3a: Produce Data Using MQTT: tml-read-MQTT-step-3-kafka-producetotopic-dag
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportpaho.mqtt.clientaspahofrompahoimportmqttimportsysimportmaadstmlimporttssloggingimportosimportsubprocessimporttimeimportrandomimportjsonsys.dont_write_bytecode=True################################################## MQTT SERVER ###################################### This is a MQTT server that will handle connections from a client. It will handle connections# from an MQTT client for on_message, on_connect, and on_subscribe# If Connecting to HiveMQ cluster you will need USERNAME/PASSWORD and mqtt_enabletls = 1# USERNAME/PASSWORD should be set in your DOCKER RUN command of the TSS container######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice','enabletls':'1','microserviceid':'','producerid':'iotsolution','topics':'iot-raw-data',# *************** This is one of the topic you created in SYSTEM STEP 2'identifier':'TML solution','mqtt_broker':'',# <<<****** Enter MQTT broker i.e. test.mosquitto.org'mqtt_port':'',# <<<******** Enter MQTT port i.e. 1883, 8883 (for HiveMQ cluster)'mqtt_subscribe_topic':'',# <<<******** enter name of MQTT to subscribe to i.e. tml/iot'mqtt_enabletls':'0',# set 1=TLS, 0=no TLSS'delay':'7000',# << ******* 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'topicid':'-999',# <<< ********* do not modify}######################################## DO NOT MODIFY BELOW ############################################## This sets the lat/longs for the IoT devices so it can be mapVIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""VIPERHOSTFROM=""# this is change 5# setting callbacks for different events to see if it works, print the message etc.defon_connect(client,userdata,flags,rc,properties=None):print("CONNACK received with code %s."%rc)# print which topic was subscribed todefon_subscribe(client,userdata,mid,granted_qos,properties=None):print("Subscribed: "+str(mid)+" "+str(granted_qos))defon_message(client,userdata,msg):data=json.loads(msg.payload.decode("utf-8"))datad=json.dumps(data)readdata(datad)defmqttserverconnect():repo=tsslogging.getrepo()tsslogging.tsslogit("MQTT producing DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")username=""password=""if'MQTTUSERNAME'inos.environ:username=os.environ['MQTTUSERNAME']if'MQTTPASSWORD'inos.environ:password=os.environ['MQTTPASSWORD']try:client=paho.Client(paho.CallbackAPIVersion.VERSION2)mqttBroker=default_args['mqtt_broker']mqttport=int(default_args['mqtt_port'])ifdefault_args['mqtt_enabletls']=="1":client.tls_set(tls_version=mqtt.client.ssl.PROTOCOL_TLS)client.username_pw_set(username,password)exceptExceptionase:tsslogging.locallogs("ERROR","Cannot connect to MQTT broker in {} - {}".format(os.path.basename(__file__),e))tsslogging.tsslogit("ERROR: Cannot connect to MQTT broker in {} - {}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")print("ERROR: Cannot connect to MQTT broker")returnclient.connect(mqttBroker,mqttport)ifclient:print("Connected")tsslogging.locallogs("INFO","MQTT connection established...")client.on_subscribe=on_subscribeclient.on_message=on_messageb=client.subscribe(default_args['mqtt_subscribe_topic'],qos=1)if'MQTT_ERR_SUCCESS'notinstr(b):print("ERROR Making a connection to HiveMQ:",b)tsslogging.locallogs("ERROR","Cannot connect to MQTT broker in {} - {}".format(os.path.basename(__file__),str(b)))tsslogging.tsslogit("CANNOT Connect to MQTT Broker in {}".format(os.path.basename(__file__)),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")else:client.on_connect=on_connectclient.loop_forever()else:print("Cannot Connect")tsslogging.locallogs("ERROR","Cannot connect to MQTT broker in {} - {}".format(os.path.basename(__file__),e))tsslogging.tsslogit("CANNOT Connect to MQTT Broker in {}".format(os.path.basename(__file__)),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")defproducetokafka(value,tmlid,identifier,producerid,maintopic,substream,args):inputbuf=valuetopicid=int(args['topicid'])# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=int(args['delay'])enabletls=int(args['enabletls'])identifier=args['identifier']try:result=maadstml.viperproducetotopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,producerid,enabletls,delay,'','','',0,inputbuf,substream,topicid,identifier)exceptExceptionase:print("ERROR:",e)defreaddata(valuedata):# MAin Kafka topic to store the real-time datamaintopic=default_args['topics']producerid=default_args['producerid']try:producetokafka(valuedata,"","",producerid,maintopic,"",default_args)# change time to speed up or slow down data#time.sleep(0.15)exceptExceptionase:print(e)passdefwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefstartproducing(**context):globalVIPERTOKENglobalVIPERHOSTglobalVIPERPORTglobalHTTPADDRglobalVIPERHOSTFROMtsslogging.locallogs("INFO","STEP 3: producing data started")sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPRODUCE".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPRODUCE".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))hs,VIPERHOSTFROM=tsslogging.getip(VIPERHOST)ti=context['task_instance']ti.xcom_push(key="{}_PRODUCETYPE".format(sname),value='MQTT')ti.xcom_push(key="{}_TOPIC".format(sname),value=default_args['topics'])buf=default_args['mqtt_broker']+":"+default_args['mqtt_port']ti.xcom_push(key="{}_CLIENTPORT".format(sname),value="")buf="MQTT Subscription Topic: "+default_args['mqtt_subscribe_topic']ti.xcom_push(key="{}_IDENTIFIER".format(sname),value=buf)ti.xcom_push(key="{}_FROMHOST".format(sname),value="{},{}".format(hs,VIPERHOSTFROM))ti.xcom_push(key="{}_TOHOST".format(sname),value=VIPERHOST)ti.xcom_push(key="{}_TSSCLIENTPORT".format(sname),value="_{}".format(default_args['mqtt_port']))ti.xcom_push(key="{}_TMLCLIENTPORT".format(sname),value="_{}".format(default_args['mqtt_port']))ti.xcom_push(key="{}_PORT".format(sname),value="_{}".format(VIPERPORT))ti.xcom_push(key="{}_HTTPADDR".format(sname),value=HTTPADDR)sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('produce',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-produce","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOSTFROM,VIPERPORT[1:]),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]mqttserverconnect()
Note
There is no MQTT client because MQTT is machine to machine communication, which means if a machine is writing to an MQTT broker, the above DAG
automatically
gets an on_message(client, userdata, msg) event and streams the data to Kafka. This is a powerful way to use TML with MQTT to process real-time data
instantly.
importpaho.mqtt.clientaspahofrompahoimportmqttimporttimeimportsysfromdatetimeimportdatetimedefault_args={'mqtt_broker':'b526253c5560459da5337e561c142369.s1.eu.hivemq.cloud',# <<<****** Enter MQTT broker i.e. test.mosquitto.org'mqtt_port':'8883',# <<<******** Enter MQTT port i.e. 1883'mqtt_subscribe_topic':'tml/iot',# <<<******** enter name of MQTT to subscribe to i.e. encyclopedia/#'mqtt_enabletls':'1',# << Enable TLS if connecting to a cloud cluster like HiveMQ}sys.dont_write_bytecode=True################################################## MQTT SERVER ###################################### This is a MQTT server that will handle connections from a client. It will handle connections# from an MQTT client for on_message, on_connect, and on_subscribe######################################## USER CHOOSEN PARAMETERS ########################################defmqttconnection():username="<Enter MQTT username>"password="<Enter MQTT password>"client=paho.Client(paho.CallbackAPIVersion.VERSION2)mqttBroker=default_args['mqtt_broker']mqttport=int(default_args['mqtt_port'])client.tls_set(tls_version=mqtt.client.ssl.PROTOCOL_TLS)client.username_pw_set(username,password)client.connect(mqttBroker,mqttport)client.subscribe(default_args['mqtt_subscribe_topic'],qos=1)returnclientdefpublishtomqttbroker(client,line):b=client.publish(topic=default_args['mqtt_subscribe_topic'],payload=line,qos=1,retain=False)if'MQTT_ERR_SUCCESS'instr(b):print(line)client.loop()else:print("ERROR Making a connection to HiveMQ:",b)defreaddatafile(client,inputfile):############################################################### NOTE: You can send any "EXTERNAL" data through this API# It is reading a localfile as an example############################################################try:file1=open(inputfile,'r')print("Data Producing to Kafka Started:",datetime.now())exceptExceptionase:print("ERROR: Something went wrong ",e)returnk=0whileTrue:line=file1.readline()line=line.replace(";"," ")print("line=",line)# add lat/long/identifierk=k+1try:ifline=="":#breakfile1.seek(0)k=0print("Reached End of File - Restarting")print("Read End:",datetime.now())continuepublishtomqttbroker(client,line)# change time to speed up or slow down datatime.sleep(.15)exceptExceptionase:print(e)time.sleep(.15)passclient=mqttconnection()inputfile="IoTDatasample.txt"readdatafile(client,inputfile)
8.5.5.6. STEP 3b: Produce Data Using RESTAPI: tml-read-RESTAPI-step-3-kafka-producetotopic-dag
importmaadstmlfromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorimportjsonfromdatetimeimportdatetime,timezonefromairflow.decoratorsimportdag,taskfromflaskimportFlask,request,jsonifyfromgevent.pywsgiimportWSGIServerimportsysimporttssloggingimportosimportsubprocessimporttimeimportrandomimportshlexfromtypingimportDict,AnyimportreimportthreadingfromfastapiimportFastAPIfromfastapi.middleware.corsimportCORSMiddlewareimportuvicornfromtypingimportList#import nest_asyncio#nest_asyncio.apply()lock=threading.Lock()mqtt_lock=threading.Lock()sys.path.insert(0,os.path.dirname(os.path.abspath(__file__)))importscadaglobalsassgimportscada_modbusascvimportmqtt_loopasmqVIPERTOKEN=""#os.environ['VIPERTOKEN']VIPERHOST=""#os.environ['VIPERHOST']VIPERPORT=""#os.environ['VIPERPORT']HTTPADDR=""sys.dont_write_bytecode=True################################################## REST API SERVER ###################################### This is a REST API server that will handle connections from a client# There are two endpoints you can use to stream data to this server:# 1. jsondataline - You can POST a single JSONs from your client app. Your json will be streamed to Kafka topic.# 2. jsondataarray - You can POST JSON arrays from your client app. Your json will be streamed to Kafka topic.######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice','enabletls':'1','microserviceid':'','producerid':'iotsolution','topics':'iot-raw-data',# *************** This is one of the topic you created in SYSTEM STEP 2'identifier':'TML solution','tss_rest_port':'9001',# <<< ***** replace replace with port number i.e. this is listening on port 9000'rest_port':'9002',# <<< ***** replace replace with port number i.e. this is listening on port 9000'delay':'7000',# << ******* 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'topicid':'-999',# <<< ********* do not modify}######################################## DO NOT MODIFY BELOW #############################################defwriteviperlogs(errortype,message,VIPERTOKEN,VIPERHOST,VIPERPORT):args=default_argsdt=datetime.now(timezone.utc)timestamp=dt.strftime("[%a, %d %b %Y %H:%M:%S UTC]")vmsg=f"{timestamp}{errortype.upper()} [{message}]"Logjson=json.dumps({"MESSAGE":str(vmsg),"SERVICE":"TML-Plugin","HOST":VIPERHOST,"PORT":str(VIPERPORT),"KAFKA_CONNECT_BOOTSTRAP_SERVERS":"Kafka Broker"})#Logjson=f'{"MESSAGE":"{vmsg}","SERVICE": "TML-Plugin", "HOST": "{VIPERHOST}","PORT": "{str(VIPERPORT)}","KAFKA_CONNECT_BOOTSTRAP_SERVERS": "Kafka Broker"}'# print("Logjson=",Logjson)producetokafka(Logjson,"","","plugin-producer","viperlogs","",args,VIPERTOKEN,VIPERHOST,VIPERPORT)defproducetokafka(value,tmlid,identifier,producerid,maintopic,substream,args,VIPERTOKEN,VIPERHOST,VIPERPORT):inputbuf=valuetopicid=int(args['topicid'])# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=int(args['delay'])enabletls=int(args['enabletls'])identifier=args['identifier']try:result=maadstml.viperproducetotopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,producerid,enabletls,delay,'','','',0,inputbuf,substream,topicid,identifier)print("produce result========",result)exceptExceptionase:print("ERROR:",e)# Check if tmux window exists BEFORE creatingdeftmuxsession(windowinstance,steps):chip='amd64'mainos='linux'cdir=''isnew1=0isnew2=0viperrun=''viperport=-1if'CHIP'inos.environ:chip=os.environ['CHIP']chip=chip.lower()windowinstance=windowinstance.replace("_","-")# start the binaryifsteps=="4":cdir="/Viper-preprocess"viperrun=f"/Viper-preprocess/viper-{mainos}-{chip}"ifsteps=="5":cdir="/Viper-ml"viperrun=f"/Viper-ml/viper-{mainos}-{chip}"ifsteps=="6":cdir="/Viper-predict"viperrun=f"/Viper-predict/viper-{mainos}-{chip}"ifsteps=="9":cdir="/Viper-preprocess-pgpt"viperrun=f"/Viper-preprocess-pgpt/viper-{mainos}-{chip}"ifsteps=="9b":cdir="/Viper-preprocess-agenticai"viperrun=f"/Viper-preprocess-agenticai/viper-{mainos}-{chip}"ifwindowinstance!='default':check_result=subprocess.run(["tmux","has-session","-t",f"plugin_{windowinstance}"],capture_output=True)check_result2=subprocess.run(["tmux","has-session","-t",f"plugin_{windowinstance}_{steps}"],capture_output=True)ifcheck_result.returncode!=0:# Window doesn't exist - create itsubprocess.run(["tmux","new-session","-d","-s",f"plugin_{windowinstance}"])subprocess.run(["tmux","send-keys","-t",f"plugin_{windowinstance}",f"cd /{cdir}","ENTER"],capture_output=True,text=True)isnew1=1else:subprocess.run(["tmux","send-keys","-t",f"plugin_{windowinstance}","C-c"])ifcheck_result2.returncode!=0:# Window doesn't exist - create itsubprocess.run(["tmux","new-session","-d","-s",f"plugin_{windowinstance}_{steps}"])isnew2=1else:subprocess.run(["tmux","send-keys","-t",f"plugin_{windowinstance}_{steps}","C-c"])withopen(f"{cdir}/viper.txt",'r',encoding='utf-8')asfile:line=file.readline()oldviperport=line.split(",")[1]ifwindowinstance!='default':subprocess.run(["tmux","send-keys","-t",f"plugin_{windowinstance}_{steps}",f"cd /{cdir}","ENTER"],capture_output=True,text=True)subprocess.run(["tmux","send-keys","-t",f"plugin_{windowinstance}_{steps}",viperrun,"ENTER"],capture_output=True,text=True)ifisnew2:time.sleep(5)withopen(f"{cdir}/viper.txt",'r',encoding='utf-8')asfile:line=file.readline()viperport=line.split(",")[1]returnoldviperport,viperport,f"plugin_{windowinstance}_{steps}",f"plugin_{windowinstance}"#start the script# subprocess.run(["tmux", "send-keys", "-t", f"plugin_{windowinstance}", new_pythonrun, "ENTER"], capture_output=True, text=True)defflatten_for_shell(arg_list):"""Flatten lists and remove newlines from strings"""flat_args=[]forarginarg_list:ifisinstance(arg,list):# Strip newlines/spaces from each list item before joiningcleaned_items=[str(x).replace('\n','').replace('\r','').strip()forxinarg]joined=' '.join(cleaned_items)flat_args.append(f'"{joined}"')else:# Strip newlines from single args tooarg_str=str(arg).replace('\n','').replace('\r','').strip()if' 'inarg_stror','inarg_str:flat_args.append(f'"{arg_str}"')else:ifarg_str.isdigit():flat_args.append(arg_str)else:flat_args.append(f'"{arg_str}"')return' '.join(flat_args)defstopstart(step,stepsarr,windowinstance='default'):print("Stopstart")pythonrun=''print("windowinstance==",windowinstance)print("step==",isinstance(step,str),step)step=str(step)ifstep=="4":oldviperport,viperport,vwn,swn=tmuxsession(windowinstance,step)ifwindowinstance=='default':viperport=oldviperportwithopen("/tmux/step4_preprocess.txt",'r',encoding='utf-8')asfile:lines=file.readlines()pythonrun=lines[2].strip()# Index 2 = 3rd linewn=lines[1].strip()args=shlex.split(pythonrun)args[-4]=stepsarr[-5]# raw_data_topicargs[-3]=stepsarr[-4]# preprocesstypesargs[-2]=stepsarr[-3]# jsoncriteriaargs[-1]=stepsarr[-2]# preprocess_data_topicargs[-6]=viperport# rollbackoffsetargs[-5]=stepsarr[-1]# rollbackoffsetnew_pythonrun=flatten_for_shell(args)#shlex.join(flatten_for_shell(args))print(f"new_pythonrun: {new_pythonrun}")elifstep=="5":oldviperport,viperport,vwn,swn=tmuxsession(windowinstance,step)ifwindowinstance=='default':viperport=oldviperportwithopen("/tmux/step5_ml.txt",'r',encoding='utf-8')asfile:lines=file.readlines()pythonrun=lines[2].strip()# Index 2 = 3rd linewn=lines[1].strip()args=shlex.split(pythonrun)args[-11]=viperport# viper portargs[-8]=stepsarr[-8]args[-7]=stepsarr[-7]args[-6]=stepsarr[-6]args[-5]=stepsarr[-5]args[-4]=stepsarr[-4]args[-3]=stepsarr[-3]args[-2]=stepsarr[-2]args[-1]=stepsarr[-1]new_pythonrun=flatten_for_shell(args)#shlex.join(flatten_for_shell(args))print(f"new_pythonrun: {new_pythonrun}")elifstep=="6":oldviperport,viperport,vwn,swn=tmuxsession(windowinstance,step)ifwindowinstance=='default':viperport=oldviperportwithopen("/tmux/step6_predictions.txt",'r',encoding='utf-8')asfile:lines=file.readlines()pythonrun=lines[2].strip()# Index 2 = 3rd linewn=lines[1].strip()args=shlex.split(pythonrun)args[-10]=viperport# viper portargs[-7]=stepsarr[-7]args[-6]=stepsarr[-6]args[-5]=stepsarr[-5]args[-4]=stepsarr[-4]args[-3]=stepsarr[-3]args[-2]=stepsarr[-2]args[-1]=stepsarr[-1]new_pythonrun=flatten_for_shell(args)#shlex.join(flatten_for_shell(args))print(f"new_pythonrun: {new_pythonrun}")elifstep=="9":oldviperport,viperport,vwn,swn=tmuxsession(windowinstance,step)ifwindowinstance=='default':viperport=oldviperportwithopen("/tmux/step9_ai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()pythonrun=lines[2].strip()# Index 2 = 3rd linewn=lines[1].strip()args=shlex.split(pythonrun)args[-24]=viperport# viper portargs[-23]=stepsarr[-18]#vectorcollectionnameargs[-22]=stepsarr[-17]#consumefromargs[-21]=stepsarr[-16]#pgpt data topicargs[-18]=stepsarr[-15]#rollbackargs[-17]=stepsarr[-14]#promptargs[-16]=stepsarr[-13]#contextargs[-15]=stepsarr[-12]#keyattributeargs[-14]=stepsarr[-11]#keyprocessargs[-13]=stepsarr[-10]#hyperbatchargs[-12]=stepsarr[-9]#docfolderargs[-11]=stepsarr[-8]#docingestintervalargs[-7]=stepsarr[-7]#tempargs[-6]=stepsarr[-6]#vectorsearchargs[-5]=stepsarr[-5]##context windowargs[-4]=stepsarr[-4]#pgptcontainernameargs[-3]=stepsarr[-3]#pgpthostargs[-2]=stepsarr[-2]#pgptportargs[-1]=stepsarr[-1]#vectordimensionnew_pythonrun=flatten_for_shell(args)#shlex.join(flatten_for_shell(args))print(f"new_pythonrun: {new_pythonrun}")elifstep=="9b":oldviperport,viperport,vwn,swn=tmuxsession(windowinstance,step)ifwindowinstance=='default':viperport=oldviperportwithopen("/tmux/step9b_agenticai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()pythonrun=lines[2].strip()# Index 2 = 3rd linewn=lines[1].strip()args=shlex.split(pythonrun)args[-27]=viperport# viper portargs[-26]=stepsarr[-17]args[-25]=stepsarr[-16]args[-23]=stepsarr[-15]args[-22]=stepsarr[-14]args[-18]=stepsarr[-13]args[-17]=stepsarr[-12]args[-14]=stepsarr[-11]args[-13]=stepsarr[-10]args[-12]=stepsarr[-9]args[-11]=stepsarr[-8]args[-10]=stepsarr[-7]args[-9]=stepsarr[-6]args[-8]=stepsarr[-5]args[-7]=stepsarr[-4]args[-3]=stepsarr[-3]args[-2]=stepsarr[-2]args[-1]=stepsarr[-1]new_pythonrun=flatten_for_shell(args)#shlex.join(flatten_for_shell(args))print(f"new_pythonrun: {new_pythonrun}")new_pythonrun=new_pythonrun.replace("<<n>>",'\n')ifwindowinstance=='default':subprocess.run(["tmux","send-keys","-t",wn,"C-c"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"{}".format(new_pythonrun),"ENTER"],capture_output=True,text=True)else:subprocess.run(["tmux","send-keys","-t","{}".format(swn),"{}".format(new_pythonrun),"ENTER"],capture_output=True,text=True)#subprocess.run(["tmux", "new", "-d", "-s", "{}".format(windowinstance)])#subprocess.run(["tmux", "send-keys", "-t", "{}".format(windowinstance), "{}".format(new_pythonrun), "ENTER"],capture_output=True, text=True)defterminatetmuxwindows(step,wn):# Get all tmux sessionswt=""ifwn=='all':result=subprocess.run(['tmux','list-sessions'],capture_output=True,text=True)sessions=result.stdout.strip().split('\n')forsessioninsessions:ifsession.startswith('plugin_'):session_name=session.split(':')[0]subprocess.run(['tmux','kill-session','-t',session_name])print(f"Killed tmux session: {session_name}")mw=session_name.split("_")[1]#session_name.replace("plugin_", "", 1)mw=session_namewt=wt+mw+","wt=wt[:-1]withopen("/tmux/step4_preprocess.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wn+","withopen("/tmux/step5_ml.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wn+","withopen("/tmux/step6_predictions.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wn+","withopen("/tmux/step9_ai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wnwithopen("/tmux/step9b_agenticai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wnelifwn=='default':ifstep=="4":withopen("/tmux/step4_preprocess.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wnifstep=="5":withopen("/tmux/step5_ml.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wnifstep=="6":withopen("/tmux/step6_predictions.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wnifstep=="9b":withopen("/tmux/step9b_agenticai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wnifstep=="9":withopen("/tmux/step9_ai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wnifstep=="0":withopen("/tmux/step4_preprocess.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wn+","withopen("/tmux/step5_ml.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wn+","withopen("/tmux/step6_predictions.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wn+","withopen("/tmux/step9_ai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wnwithopen("/tmux/step9b_agenticai.txt",'r',encoding='utf-8')asfile:lines=file.readlines()wn=lines[1].strip()subprocess.run(["tmux","send-keys","-t",wn,"C-c"])wt=wt+wnelse:subprocess.run(['tmux','kill-session','-t',f"plugin_{wn}_{step}"])subprocess.run(['tmux','kill-session','-t',f"plugin_{wn}"])wt=wnreturnwtdefgettmlsystemsparams():repo=tsslogging.getrepo()############################################### API Routes ########################################ifVIPERHOST!="":#app = Flask(__name__)app=FastAPI()app.add_middleware(CORSMiddleware,allow_origins=["*"],# Allow all for devallow_credentials=True,allow_methods=["*"],allow_headers=["*"],)#-------------------------------- TERMINATE WINDOW -----------------------------------------------------@app.post('/api/v1/terminatewindow')defwindowterminate(jdata:dict):# jdata = request.get_json()ifnotjdata:return"Missing windows",400step=jdata.get('step','')windowname=jdata.get('windowname','')ifwindowname!='':wd=terminatetmuxwindows(step,windowname)return{'status':f"success: windows terminated: {wd}",}return{'status':'success: no windows terminated',}#-------------------------------- CREATETOPIC -----------------------------------------------------@app.post('/api/v1/createtopic')defstorecreatetopic(jdata:dict):# jdata = request.get_json()ifnotjdataornotjdata.get('topics'):return"Missing topics",400topics=jdata.get('topics')numpartitions=int(jdata.get('numpartitions',3))replication=int(jdata.get('replication',1))description=jdata.get('description','user topic')enabletls=int(jdata.get('enabletls',1))ptarr=[t.strip()fortintopics.split(",")ift.strip()]brokerhost=''brokerport=''try:forptinptarr:iflen(pt)>0:result=maadstml.vipercreatetopic(VIPERTOKEN,VIPERHOST,VIPERPORT,pt,'companyname','myname','myemail','mylocation',description,enabletls,brokerhost,brokerport,numpartitions,replication,'')print(result)writeviperlogs("INFO",f"Creating Topic: {pt}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{'status':'success','topics':topics,'partitions':numpartitions,'replication':replication,'description':description}exceptExceptionase:writeviperlogs("ERROR",f"Creating Topic failed: {pt}: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{'status':f"error: {e}",'topics':topics,'partitions':numpartitions,'replication':replication,'description':description}#-------------------------------- PREPROCESS -----------------------------------------------------@app.post('/api/v1/preprocess')defstorepreprocess(jdata:dict):# jdata = request.get_json()ifnotjdataornotjdata.get('rawdatatopic'):return"Missing preprocess or invalid preprocess",400step=str(jdata.get('step',''))try:ifstep=='4':step4raw_data_topic=jdata.get('rawdatatopic','')step4preprocess_data_topic=jdata.get('preprocessdatatopic','')step4preprocesstypes=jdata.get('preprocesstypes','')step4jsoncriteria=jdata.get('jsoncriteria','')rollbackoffset=jdata.get('rollbackoffsets',200)windowinstance=jdata.get("windowinstance","default")step4arr=[step4raw_data_topic,step4preprocesstypes,step4jsoncriteria,step4preprocess_data_topic,rollbackoffset]stopstart(step,step4arr,windowinstance)elifstep=='4c':maxrows=jdata.get('maxrows',10)searchterms=jdata.get('searchterms','')rememberpastwindows=jdata.get('rememberpastwindows',5)patternwindowthreshold=jdata.get('patternwindowthreshold',30)raw_data_topic=jdata.get('raw_data_topic','')rtmsstream=jdata.get('rtmsstream','')rtmsscorethreshold=jdata.get('rtmsscorethreshold',0.6)attackscorethreshold=jdata.get('attackscorethreshold',0.6)patternscorethreshold=jdata.get('patternscorethreshold',0.6)localsearchtermfolder=jdata.get('localsearchtermfolder','')localsearchtermfolderinterval=jdata.get('localsearchtermfolderinterval','')rtmsfoldername=jdata.get('rtmsfoldername','')rtmsmaxwindows=jdata.get('rtmsmaxwindows',10000)windowinstance=jdata.get("windowinstance","default")step4carr=[maxrows,searchterms,rememberpastwindows,patternwindowthreshold,raw_data_topic,rtmsstream,rtmsscorethreshold,attackscorethreshold,patternscorethreshold,localsearchtermfolder,localsearchtermfolderinterval,rtmsfoldername,rtmsmaxwindows]stopstart(step,step4carr,windowinstance)return{'status':'success','step4raw_data_topic':jdata.get('rawdatatopic',''),'step4preprocess_data_topic':jdata.get('preprocessdatatopic',''),'step4preprocesstypes':jdata.get('preprocesstypes',''),'step4jsoncriteria':jdata.get('jsoncriteria',''),'rollbackoffset':jdata.get('rollbackoffset',400),'windowinstance':jdata.get("windowinstance","default")}exceptExceptionase:writeviperlogs("ERROR",f"Preprocessing failed: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{'status':f"error:{e}",'step4raw_data_topic':jdata.get('rawdatatopic',''),'step4preprocess_data_topic':jdata.get('preprocessdatatopic',''),'step4preprocesstypes':jdata.get('preprocesstypes',''),'step4jsoncriteria':jdata.get('jsoncriteria',''),'rollbackoffset':jdata.get('rollbackoffset',400),'windowinstance':jdata.get("windowinstance","default")}#-------------------------------- MACHINE LEARNING -----------------------------------------------------@app.post('/api/v1/ml')defstoreml(jdata:dict):# jdata = request.get_json()ifnotjdata:return"Missing ml or invalid ml",400step=str(jdata.get('step',''))try:ifstep=="5":trainingdatafolder=jdata.get('trainingdatafolder','')ml_data_topic=jdata.get('ml_data_topic','')preprocess_data_topic=jdata.get('preprocess_data_topic','')islogistic=jdata.get('islogistic',0)dependentvariable=jdata.get('dependentvariable','failure')independentvariables=jdata.get('independentvariables','')processlogic=jdata.get('processlogic','')rollbackoffsets=jdata.get('rollbackoffsets',50)windowinstance=jdata.get('windowinstance','default')step5arr=[rollbackoffsets,processlogic,independentvariables,dependentvariable,islogistic,preprocess_data_topic,ml_data_topic,trainingdatafolder]stopstart(step,step5arr,windowinstance)return{'status':"success",'trainingdatafolder':jdata.get('trainingdatafolder',''),'ml_data_topic':jdata.get('ml_data_topic',''),'preprocess_data_topic':jdata.get('preprocess_data_topic',''),'islogistic':jdata.get('islogistic',0),'dependentvariable':jdata.get('dependentvariable','failure'),'independentvariables':jdata.get('independentvariables',''),'processlogic':jdata.get('processlogic',''),'rollbackoffsets':jdata.get('rollbackoffsets',50),'windowinstance':jdata.get('windowinstance','default')}exceptExceptionase:writeviperlogs("ERROR",f"Machine learning failed: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{'status':f"error:{e}",'trainingdatafolder':jdata.get('trainingdatafolder',''),'ml_data_topic':jdata.get('ml_data_topic',''),'preprocess_data_topic':jdata.get('preprocess_data_topic',''),'islogistic':jdata.get('islogistic',0),'dependentvariable':jdata.get('dependentvariable','failure'),'independentvariables':jdata.get('independentvariables',''),'processlogic':jdata.get('processlogic',''),'rollbackoffsets':jdata.get('rollbackoffsets',50),'windowinstance':jdata.get("windowinstance","default")}#-------------------------------- PREDICTIONS -----------------------------------------------------@app.post('/api/v1/predict')defpredictdata(jdata:dict):# jdata = request.get_json()ifnotjdata:return"Missing ml or invalid prediction",400step=str(jdata.get('step',''))try:ifstep=="6":pathtoalgos=jdata.get('pathtoalgos','')maxrows=jdata.get('rollbackoffsets',50)consumefrom=jdata.get('consumefrom','')inputdata=jdata.get('inputdata','')streamstojoin=jdata.get('streamstojoin','')ml_prediction_topic=jdata.get('ml_prediction_topic','')preprocess_data_topic=jdata.get('preprocess_data_topic','')windowinstance=jdata.get('windowinstance','default')step6arr=[maxrows,preprocess_data_topic,ml_prediction_topic,streamstojoin,inputdata,consumefrom,pathtoalgos]stopstart(step,step6arr,windowinstance)return{'status':"success",'pathtoalgos':jdata.get('pathtoalgos',''),'maxrows':jdata.get('rollbackoffsets',50),'consumefrom':jdata.get('consumefrom',''),'inputdata':jdata.get('inputdata',''),'streamstojoin':jdata.get('streamstojoin',''),'ml_prediction_topic':jdata.get('ml_prediction_topic',''),'preprocess_data_topic':jdata.get('preprocess_data_topic',''),'windowinstance':jdata.get('windowinstance','default')}exceptExceptionase:writeviperlogs("ERROR",f"Predictions failed: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{'status':f"error:{e}",'pathtoalgos':jdata.get('pathtoalgos',''),'maxrows':jdata.get('rollbackoffsets',50),'consumefrom':jdata.get('consumefrom',''),'inputdata':jdata.get('inputdata',''),'streamstojoin':jdata.get('streamstojoin',''),'ml_prediction_topic':jdata.get('ml_prediction_topic',''),'preprocess_data_topic':jdata.get('preprocess_data_topic',''),'windowinstance':jdata.get('windowinstance','default')}#-------------------------------- AI -----------------------------------------------------@app.post('/api/v1/ai')defaidata(jdata:dict):# jdata = request.get_json()ifnotjdata:return"Missing ai or invalid ai",400step=str(jdata.get('step',''))try:ifstep=="9":vectordimension=jdata.get('vectordimension','768')contextwindowsize=jdata.get('contextwindowsize','8192')#agent - team lead - supervisorvectorsearchtype=jdata.get('vectorsearchtype','Manhattan')temperature=float(jdata.get('temperature','0.1'))docfolderingestinterval=jdata.get('docfolderingestinterval','900')docfolder=jdata.get('docfolder','')vectordbcollectionname=jdata.get('vectordbcollectionname','tml-pgpt')hyperbatch=jdata.get('hyperbatch','0')keyprocesstype=jdata.get('keyprocesstype','')keyattribute=jdata.get('keyattribute','hyperprediction')context=jdata.get('context','')prompt=jdata.get('prompt','')pgptport=jdata.get('pgptport','8001')pgpthost=jdata.get('pgpthost','http://127.0.0.1')pgpt_data_topic=jdata.get('pgpt_data_topic','')consumefrom=jdata.get('consumefrom','')rollbackoffset=jdata.get('rollbackoffset','5')pgptcontainername=jdata.get('pgptcontainername','maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-v2')windowinstance=jdata.get('windowinstance','default')step9arr=[vectordbcollectionname,consumefrom,pgpt_data_topic,rollbackoffset,prompt,context,keyattribute,keyprocesstype,hyperbatch,docfolder,docfolderingestinterval,temperature,vectorsearchtype,contextwindowsize,pgptcontainername,pgpthost,pgptport,vectordimension]stopstart(step,step9arr,windowinstance)return{'status':"success",'vectordimension':jdata.get('vectordimension','768'),'contextwindowsize':jdata.get('contextwindowsize','8192'),#agent - team lead - supervisor'vectorsearchtype':jdata.get('vectorsearchtype','Manhattan'),'temperature':jdata.get('temperature','0.1'),'docfolderingestinterval':jdata.get('docfolderingestinterval','900'),'docfolder':jdata.get('docfolder',''),'vectordbcollectionname':jdata.get('vectordbcollectionname','tml-pgpt'),'hyperbatch':jdata.get('hyperbatch','0'),'keyprocesstype':jdata.get('keyprocesstype',''),'keyattribute':jdata.get('keyattribute','hyperprediction'),'context':jdata.get('context',''),'prompt':jdata.get('prompt',''),'pgptport':jdata.get('pgptport','8001'),'pgpthost':jdata.get('pgpthost','http://127.0.0.1'),'pgpt_data_topic':jdata.get('pgpt_data_topic',''),'consumefrom':jdata.get('consumefrom',''),'rollbackoffset':jdata.get('rollbackoffset','5'),'pgptcontainername':jdata.get('pgptcontainername','maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-v2'),'windowinstance':jdata.get('windowinstance','default')}exceptExceptionase:writeviperlogs("ERROR",f"AI failed: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{'status':f"error:{e}",'vectordimension':jdata.get('vectordimension','768'),'contextwindowsize':jdata.get('contextwindowsize','8192'),#agent - team lead - supervisor'vectorsearchtype':jdata.get('vectorsearchtype','Manhattan'),'temperature':jdata.get('temperature','0.1'),'docfolderingestinterval':jdata.get('docfolderingestinterval','900'),'docfolder':jdata.get('docfolder',''),'vectordbcollectionname':jdata.get('vectordbcollectionname','tml-pgpt'),'hyperbatch':jdata.get('hyperbatch','0'),'keyprocesstype':jdata.get('keyprocesstype',''),'keyattribute':jdata.get('keyattribute','hyperprediction'),'context':jdata.get('context',''),'prompt':jdata.get('prompt',''),'pgptport':jdata.get('pgptport','8001'),'pgpthost':jdata.get('pgpthost','http://127.0.0.1'),'pgpt_data_topic':jdata.get('pgpt_data_topic',''),'consumefrom':jdata.get('consumefrom',''),'rollbackoffset':jdata.get('rollbackoffset','5'),'pgptcontainername':jdata.get('pgptcontainername','maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-v2'),'windowinstance':jdata.get('windowinstance','default')}#-------------------------------- AGENTIC AI -----------------------------------------------------@app.post('/api/v1/agenticai')defagenticaidata(jdata:dict):# jdata = request.get_json()ifnotjdata:return"Missing agentic ai or invalid agentic ai",400step=str(jdata.get('step',''))try:ifstep=="9b":maxrows=jdata.get('rollbackoffsets',10)ollamamodel=jdata.get('ollama-model','phi3:3.8b,phi3:3.8b,llama3.2:3b')#agent - team lead - supervisorvectordbpath=jdata.get('vectordbpath','/rawdata/vectordb')temperature=float(jdata.get('temperature','0.1'))vectordbcollectionname=jdata.get('vectordbcollectionname','tml-llm-model')ollamacontainername=jdata.get('ollamacontainername','maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-llama3-tools')embedding=jdata.get('embedding','nomic-embed-text')agents_topic_prompt=jdata.get('agents_topic_prompt','')teamlead_topic=jdata.get('teamlead_topic','team-lead-responses')teamleadprompt=jdata.get('teamleadprompt','')supervisor_topic=jdata.get('supervisor_topic','supervisor-responses')supervisorprompt=jdata.get('supervisorprompt','')agenttoolfunctions=jdata.get('agenttoolfunctions','')agent_team_supervisor_topic=jdata.get('agent_team_supervisor_topic','all-agents-responses')contextwindow=jdata.get('contextwindow','4096')localmodelsfolder=jdata.get('localmodelsfolder','/rawdata/ollama')agenttopic=jdata.get('agenttopic','agent-responses')windowinstance=jdata.get('windowinstance','default')step9barr=[maxrows,ollamamodel,vectordbpath,temperature,vectordbcollectionname,ollamacontainername,embedding,agents_topic_prompt,teamlead_topic,teamleadprompt,supervisor_topic,supervisorprompt,agenttoolfunctions,agent_team_supervisor_topic,contextwindow,localmodelsfolder,agenttopic]stopstart(step,step9barr,windowinstance)return{'status':"success",'rollbackoffset':jdata.get('rollbackoffsets',10),'ollamamodel':jdata.get('ollama-model','phi3:3.8b,phi3:3.8b,llama3.2:3b'),#agent - team lead - supervisor'vectordbpath':jdata.get('vectordbpath','/rawdata/vectordb'),'temperature':jdata.get('temperature','0.1'),'vectordbcollectionname':jdata.get('vectordbcollectionname','tml-llm-model'),'ollamacontainername':jdata.get('ollamacontainername','maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-llama3-tools'),'embedding':jdata.get('embedding','nomic-embed-text'),'agents_topic_prompt':jdata.get('agents_topic_prompt',''),'teamlead_topic':jdata.get('teamlead_topic','team-lead-responses'),'teamleadprompt':jdata.get('teamleadprompt',''),'supervisor_topic':jdata.get('supervisor_topic','supervisor-responses'),'supervisorprompt':jdata.get('supervisorprompt',''),'agenttoolfunctions':jdata.get('agenttoolfunctions',''),'agent_team_supervisor_topic':jdata.get('agent_team_supervisor_topic','all-agents-responses'),'contextwindow':jdata.get('contextwindow','4096'),'localmodelsfolder':jdata.get('localmodelsfolder','/rawdata/ollama'),'agenttopic':jdata.get('agenttopic','agent-responses'),'windowinstance':jdata.get('windowinstance','default')}exceptExceptionase:writeviperlogs("ERROR",f"Agentic AI failed: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{'status':f"error:{e}",'rollbackoffset':jdata.get('rollbackoffsets',10),'ollamamodel':jdata.get('ollama-model','phi3:3.8b,phi3:3.8b,llama3.2:3b'),#agent - team lead - supervisor'vectordbpath':jdata.get('vectordbpath','/rawdata/vectordb'),'temperature':jdata.get('temperature','0.1'),'vectordbcollectionname':jdata.get('vectordbcollectionname','tml-llm-model'),'ollamacontainername':jdata.get('ollamacontainername','maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-llama3-tools'),'embedding':jdata.get('embedding','nomic-embed-text'),'agents_topic_prompt':jdata.get('agents_topic_prompt',''),'teamlead_topic':jdata.get('teamlead_topic','team-lead-responses'),'teamleadprompt':jdata.get('teamleadprompt',''),'supervisor_topic':jdata.get('supervisor_topic','supervisor-responses'),'supervisorprompt':jdata.get('supervisorprompt',''),'agenttoolfunctions':jdata.get('agenttoolfunctions',''),'agent_team_supervisor_topic':jdata.get('agent_team_supervisor_topic','all-agents-responses'),'contextwindow':jdata.get('contextwindow','4096'),'localmodelsfolder':jdata.get('localmodelsfolder','/rawdata/ollama'),'agenttopic':jdata.get('agenttopic','agent-responses'),'windowinstance':jdata.get('windowinstance','default')}#-------------------------------- CONSUME -----------------------------------------------------@app.post('/api/v1/consume')defconsumedata(jdata:dict):# jdata = request.get_json()osdu=jdata.get('osdu','false')kind=jdata.get('kind','tml')ifnotjdataornotjdata.get('topic'):ifosdu=='false':return"Missing ml or invalid consume",400else:return{"kind":f"{kind}","id":"consume-error","error":{"code":400,"message":"Missing topic or invalid consume request","reason":"Topic parameter required"}}forward_statuses=[]maintopic=jdata.get('topic','')forwardurl=jdata.get('forwardurl','')legal=jdata.get('legal','tml-legal')forward_headers={'Content-Type':'application/json'}ifmaintopic!='':try:rollbackoffsets=int(jdata.get('rollbackoffsets',100))enabletls=int(jdata.get('enabletls',1))consumerid='tmlconsumerplugin'companyname='companyname'offset=int(jdata.get('offset',-1))brokerhost=''brokerport=-999microserviceid=''topicid=jdata.get('topicid','-999')preprocesstype=''delay=100partition=-1result=maadstml.viperconsumefromtopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,consumerid,companyname,partition,enabletls,delay,offset,brokerhost,brokerport,microserviceid,topicid,rollbackoffsets,preprocesstype)now_iso=datetime.utcnow().isoformat()+"Z"result=json.loads(result)ifosdu=='false':response={'status':'consumed','topic':maintopic,'Messages':result,# viperconsumefromtopic output'consumer_id':consumerid}else:response={"kind":f"{kind}","id":f"osdu:tml:consume:{maintopic}:{int(time.time())}","data":{"Topic":maintopic,"ConsumerID":consumerid,"CompanyName":companyname,"Messages":result,# Your viperconsumefromtopic output"Partition":partition,"Offset":offset,"RollbackOffsets":rollbackoffsets,"meta":{"dataPartitionId":"tml-id","createTime":f"{now_iso}","modificationTime":f"{now_iso}","acl":{"viewers":["data.default.viewers@tml.group"],"owners":["data.default.owners@tml.group"]},"legal":{"legaltags":f"{legal}","status":"compliant"}}}}ifforwardurl=='':#print("response=",response)returnresponseelse:farr=[fw.strip()forfwinforwardurl.split(",")]# Clean whitespaceforfwinfarr:try:fwdresponse=requests.post(f"{fw}",json=response,headers={'Content-Type':'application/json','data-partition-id':'tml-id'},timeout=30)forward_statuses.append({'url':fw.strip(),'status':fwdresponse.status_code,'success':fwdresponse.ok})exceptExceptionase:forward_statuses.append({'url':fw.strip(),'error':str(e)})writeviperlogs("ERROR",f"Forwarding URL failed: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)response['forward_statuses']=forward_statusesreturnresponseexceptExceptionase:print("Error=",e)writeviperlogs("ERROR",f"Consume failed: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)return{"error":f"Consumption failed: {e}"}##################### INDUSTRIAL API ###############################################################-------------------------------- SCADA/MODBUS -----------------------------------------------------@app.post("/api/v1/scada_modbus_read")asyncdefstart_vessel_read(req:dict):#req = request.get_json()job_id=str(time.time())scada_cfg={"host":req.get("scada_host","127.0.0.1"),"port":req.get("scada_port",2502),"unit_id":req.get("slave_id",1),}withlock:# ✅ Thread-safeifsg.read_jobandsg.read_job["stop"]:# Don't sleep - just skip or queuepass# Stop existing thread firstifsg.read_threadandsg.read_thread.is_alive():sg.read_job["stop"]=Truesg.read_thread.join(timeout=float(req.get("read_interval_seconds",0.3))+1.0)sg.read_job={"stop":False,"job_id":job_id}sg.read_thread=threading.Thread(target=cv.modbus_read_loop,args=(scada_cfg,req.get("read_interval_seconds",0.3),req.get("callback_url",""),req.get("max_reads",-1),req.get("fields",[]),req.get("scaling",{}),req.get("start_register",40001)-40001,req.get("sendtotopic",""),job_id,VIPERTOKEN,VIPERHOST,VIPERPORT,default_args,req.get("vessel_names",{}),req.get("createvariables","")# ✅ Dynamic from request),daemon=True,)sg.read_thread.start()return{"message":"SCADA Vessel read started","job_id":job_id,"config_from_request":{"fields":len(req.get("fields",[])),"has_createvariables":bool(req.get("createvariables"))}}@app.post("/api/v1/vessel_data")defvessel_data_callback(data:dict):# data = request.get_json()# DYNAMIC: Handle ANY data structure from callbackvessel=data.get('vessel',data)# Nested OR flat# DYNAMIC: Find vessel identifier (vesselIndex OR first field)vessel_id=(vesselor{}).get('vesselIndex',next(iter(vessel),'N/A')ifvesselelse'N/A')# DYNAMIC: Find pressure field (operatingPressure OR first numeric)pressure=0forkey,valinvessel.items():ifisinstance(val,(int,float))and'pressure'inkey.lower():pressure=valbreakprint(f"📨 Job {data.get('job_id','N/A')} | Vessel {vessel_id}: {pressure:.1f}")print(f" Total fields: {len(vessel)ifvesselelse0}")# DYNAMIC: Show computed vars (anything not in original fields list)original_fields=data.get('fields',[])computed_fields={k:vfork,vinvessel.items()ifknotinoriginal_fieldsandisinstance(v,(int,float))}forfield,valueinlist(computed_fields.items())[:3]:print(f" {field}: {value:.0f}")print(json.dumps(data))returnjson.dumps(data)@app.post("/api/v1/scada_read_stop")defstop_vessel_read():ifsg.read_job:sg.read_job["stop"]=Truereturn{"message":"Stop signal sent"}@app.get("/api/v1/scada_status")defstatus():return{"running":sg.read_jobisnotNoneandnotsg.read_job.get("stop",True)ifsg.read_jobelseFalse}################################# MQTT #############################################################@app.post("/api/v1/mqtt_subscribe")defstart_mqtt_subscribe(req:dict):try:job_id=str(time.time())mqtt_cfg={"broker":req.get("mqtt_broker",""),"port":int(req.get("mqtt_port","8883")),"topic":req.get("mqtt_subscribe_topic",""),"sendtotopic":req.get("sendtotopic",""),"username":os.environ.get('MQTTUSERNAME',''),"password":os.environ.get('MQTTPASSWORD',''),"enable_tls":req.get("mqtt_enabletls","1"),"VIPERTOKEN":app.config['VIPERTOKEN'],"VIPERHOST":app.config['VIPERHOST'],"VIPERPORT":app.config['VIPERPORT'],"default_args":default_args,}withmqtt_lock:# New lock for MQTT globals (add to scadaglobals.py)# Stop existing MQTT threadifsg.mqtt_threadandsg.mqtt_thread.is_alive():sg.mqtt_job["stop"]=Truesg.mqtt_client.disconnect()# sg.mqtt_thread.join(timeout=2.0)sg.mqtt_job={"stop":False,"job_id":job_id}sg.mqtt_thread=threading.Thread(target=mq.mqttserverconnect_threaded,# Your function, modified belowargs=(mqtt_cfg,job_id),daemon=False)sg.mqtt_thread.start()# Keep this thread alive as long as the job is runningreturn{"message":"MQTT subscription started","job_id":job_id}exceptExceptionase:print("❌ JSON ERROR:",str(e))return{"error":f"JSON parse failed: {str(e)}"}####################################################################################################@app.post('/api/v1/jsondataline')defstorejsondataline(jdata:dict):# jdata = request.get_json()topic=jdata.get('sendtotopic','')jdata=json.dumps(jdata)readdata(jdata,VIPERTOKEN,VIPERHOST,VIPERPORT,topic)return"ok"@app.post('/api/v1/jsondataarray')defstorejsondataarray(jdata:List[dict]):# jdata = request.get_json()foriteminjdata:topic=item.get('sendtotopic','')item=json.dumps(item)readdata(item,VIPERTOKEN,VIPERHOST,VIPERPORT,topic)return"ok"####################################################################################################@app.post('/api/v1/health')deftmux_health_check_json()->Dict[str,Any]:defrun_tmux(cmd):try:result=subprocess.run(['tmux']+cmd,capture_output=True,text=True,timeout=10)returnresult.stdout.strip()except:return""result={"timestamp":datetime.now().isoformat(),"sessions":[],"summary":{"total_plugin_windows":0,"error_count":0,"healthy":True}}# Get clean session listsessions_raw=run_tmux(['ls','-F','#{session_name}'])orrun_tmux(['list-sessions','-F','#{session_name}'])sessions=[s.strip()forsinsessions_raw.split('\n')ifs.strip()]crash_patterns=[r'panic[:\s]',r'fatal\s+error',r'segmentation.*fault',r'SIGSEGV',r'runtime\s+error',r'goroutine\s+panic',r'signal:.*killed',r'signal:.*abrt']forsession_nameinsessions:# ✅ FIX 1: Check if SESSION starts with plugin_is_plugin_session=session_name.startswith('plugin_')session_name_user="n/a"ifis_plugin_session:session_name_user=session_name.split("_")[1]session_data={"name":session_name,"user_session":session_name_user,"is_plugin_session":is_plugin_session,"plugin_windows":[],"status":"healthy","plugin_window_count":0}# Get windows for this sessionwindows_raw=run_tmux(['list-windows','-t',session_name,'-F','#{window_index}:#{window_name}'])windows=[wforwinwindows_raw.split('\n')if':'inw]# ✅ FIX 2: Include ANY window starting with plugin_ OR session is plugin_plugin_windows=[]forwininwindows:win_index,win_name=win.split(':',1)# Check if WINDOW starts with plugin_ OR SESSION is plugin_#if win_name.startswith('plugin_') or is_plugin_session:plugin_windows.append((win_index,win_name))# Process plugin windowsforwin_index,win_nameinplugin_windows:result["summary"]["total_plugin_windows"]+=1session_data["plugin_window_count"]+=1pane_content=run_tmux(['capture-pane','-t',f'{session_name}:{win_index}.0','-S','-1000','-e','-q'])crashes=[line.strip()forlineinpane_content.split('\n')ifany(re.search(p,line,re.IGNORECASE)forpincrash_patterns)]window_data={"index":win_index,"name":win_name,"status":"healthy"ifnotcrasheselse"crashed","crash_lines":crashes[:5]}ifcrashes:result["summary"]["error_count"]+=1session_data["status"]="unhealthy"result["summary"]["healthy"]=Falsesession_data["plugin_windows"].append(window_data)# ✅ FIX 3: Include ANY session with plugin activityifsession_data["plugin_window_count"]>0oris_plugin_session:result["sessions"].append(session_data)writeviperlogs("INFO",f"{result}",VIPERTOKEN,VIPERHOST,VIPERPORT)returnresult#####################################################################################################app.run(port=default_args['rest_port']) # for devifos.environ['TSS']=="0":try:#http_server = WSGIServer(('', int(default_args['rest_port'])), app)uvicorn.run(app,# Replace 'your_file_name' with actual filenamehost="0.0.0.0",port=int(default_args['rest_port']),log_level="info",reload=False# Disable reload in production)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 3: Cannot connect to WSGIServer in {} - {}".format(os.path.basename(__file__),e))tsslogging.tsslogit("ERROR: Cannot connect to WSGIServer in {}".format(os.path.basename(__file__)),"ERROR")# tsslogging.git_push("/{}".format(repo),"Entry from {} - {}".format(os.path.basename(__file__),e),"origin")print("ERROR: Cannot connect to WSGIServer")writeviperlogs("ERROR",f"Cannot start TML Plugin server: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)returnelse:try:print("Listening")writeviperlogs("INFO","TML Plugin Server Started",VIPERTOKEN,VIPERHOST,VIPERPORT)#http_server = WSGIServer(('', int(default_args['tss_rest_port'])), app)uvicorn.run(app,# Replace 'your_file_name' with actual filenamehost="0.0.0.0",port=int(default_args['tss_rest_port']),log_level="info",reload=False# Disable reload in production)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 3: Cannot connect to WSGIServer in {} - {}".format(os.path.basename(__file__),e))tsslogging.tsslogit("ERROR: Cannot connect to WSGIServer in {}".format(os.path.basename(__file__)),"ERROR")# tsslogging.git_push("/{}".format(repo),"Entry from {} - {}".format(os.path.basename(__file__),e),"origin")print("ERROR: Cannot connect to WSGIServer")writeviperlogs("ERROR",f"Cannot start plugin server: {e}",VIPERTOKEN,VIPERHOST,VIPERPORT)returntsslogging.locallogs("INFO","STEP 3: RESTAPI HTTP Server started ... successfully")# http_server.serve_forever()#return [VIPERTOKEN,VIPERHOST,VIPERPORT]defreaddata(valuedata,VIPERTOKEN,VIPERHOST,VIPERPORT,topic=''):args=default_args# MAin Kafka topic to store the real-time dataiftopic=='':maintopic=args['topics']else:maintopic=topicproducerid=args['producerid']try:producetokafka(valuedata,"","",producerid,maintopic,"",args,VIPERTOKEN,VIPERHOST,VIPERPORT)# change time to speed up or slow down data#time.sleep(0.15)exceptExceptionase:print(e)passdefwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefstartproducing(**context):globalVIPERTOKEN,VIPERHOST,VIPERPORT,HTTPADDRsd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPRODUCE".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPRODUCE".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))tsslogging.locallogs("INFO","STEP 3: producing data started")chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))hs,VIPERHOSTFROM=tsslogging.getip(VIPERHOST)ti=context['task_instance']ti.xcom_push(key="{}_PRODUCETYPE".format(sname),value='REST')ti.xcom_push(key="{}_TOPIC".format(sname),value=default_args['topics'])ifos.environ['TSS']=="0":ti.xcom_push(key="{}_CLIENTPORT".format(sname),value="_{}".format(default_args['rest_port']))else:ti.xcom_push(key="{}_CLIENTPORT".format(sname),value="_{}".format(default_args['tss_rest_port']))ti.xcom_push(key="{}_TSSCLIENTPORT".format(sname),value="_{}".format(default_args['tss_rest_port']))ti.xcom_push(key="{}_TMLCLIENTPORT".format(sname),value="_{}".format(default_args['rest_port']))ti.xcom_push(key="{}_IDENTIFIER".format(sname),value=default_args['identifier'])ti.xcom_push(key="{}_FROMHOST".format(sname),value="{},{}".format(hs,VIPERHOSTFROM))ti.xcom_push(key="{}_TOHOST".format(sname),value=VIPERHOST)ti.xcom_push(key="{}_PORT".format(sname),value="_{}".format(VIPERPORT))ti.xcom_push(key="{}_HTTPADDR".format(sname),value=HTTPADDR)wn=windowname('produce',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-produce","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOSTFROM,VIPERPORT[1:]),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]os.environ['VIPERTOKEN']=VIPERTOKENos.environ['VIPERHOST']=VIPERHOSTos.environ['VIPERPORT']=VIPERPORTgettmlsystemsparams()
importrequestsimportsysfromdatetimeimportdatetimeimporttimeimportjsonsys.dont_write_bytecode=True# defining the api-endpointrest_port="9002"# <<< ***** Change Port to match the Server Rest_PORThttpaddr="http:"# << Change to https or http# Modify the apiroute: jsondataline, or jsondataarray# 1. jsondataline: You can send One Json message at a time# 1. jsondatarray: You can send a Json arrayapiroute="jsondataline"# USE THIS ENDPOINT IF TML RUNNING IN DOCKER CONTAINER# DOCKER CONTAINER ENDPOINT#API_ENDPOINT = "{}//localhost:{}/{}".format(httpaddr,rest_port,apiroute)# USE THIS ENDPOINT IF TML RUNNING IN KUBERNETES# KUBERNETES ENDPOINTAPI_ENDPOINT="{}//tml.tss/ext/{}".format(httpaddr,apiroute)defsend_tml_data(data):# data to be sent to apiheaders={'Content-type':'application/json'}print(API_ENDPOINT)r=requests.post(url=API_ENDPOINT,data=json.dumps(data),headers=headers)# extracting response textreturnr.textdefreaddatafile(inputfile):############################################################### NOTE: You can send any "EXTERNAL" data through this API# It is reading a localfile as an example############################################################try:file1=open(inputfile,'r')print("Data Producing to Kafka Started:",datetime.now())exceptExceptionase:print("ERROR: Something went wrong ",e)returnk=0whileTrue:line=file1.readline()line=line.replace(";"," ")print("line=",line)# add lat/long/identifierk=k+1try:ifline=="":#breakfile1.seek(0)k=0print("Reached End of File - Restarting")print("Read End:",datetime.now())continueret=send_tml_data(line)print(ret)# change time to speed up or slow down datatime.sleep(.1)exceptExceptionase:print(e)time.sleep(0.1)passdefstart():inputfile="IoTData.txt"readdatafile(inputfile)if__name__=='__main__':start()
The REST API client runs outside the TML solution container. The client api gives you the capability of connecting to your internal systems or devices and stream the data directly to the TML server producer. The TML server producer receives data from REST API client and produces the data to Kafka.
Important
The REST API client runs outside the TML solution container. This is a very simple and convenient way to stream any type of json data from any device in your
environment.
8.5.5.11. STEP 3c: Produce Data Using gRPC: tml-read-gRPC-step-3-kafka-producetotopic-dag
importasyncioimportsignalfromgoogle.protobuf.json_formatimportMessageToJsonfromgrpc_reflection.v1alphaimportreflectionimportmaadstmlfromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportgrpcfromconcurrentimportfuturesimporttimeimporttml_grpc_pb2_grpcaspb2_grpcimporttml_grpc_pb2aspb2importtssloggingimportsysimportosimportsubprocessimportrandomimportjsonimportnest_asyncionest_asyncio.apply()#from grpc.experimental import aiosys.dont_write_bytecode=True################################################## gRPC SERVER ################################################ This is a gRPCserver that will handle connections from a client# There are two endpoints you can use to stream data to this server:# 1. jsondataline - You can POST a single JSONs from your client app. Your json will be streamed to Kafka topic.# 2. jsondataarray - You can POST JSON arrays from your client app. Your json will be streamed to Kafka topic.######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< ***** leave blank'producerid':'iotsolution',# <<< *** Change as needed'topics':'iot-raw-data',# *************** This is one of the topic you created in SYSTEM STEP 2'identifier':'TML solution',# <<< *** Change as needed'tss_gRPC_Port':'9001',# <<< ***** replace with gRPC port i.e. this gRPC server listening on port 9001'gRPC_Port':'9002',# <<< ***** replace with gRPC port i.e. this gRPC server listening on port 9001'delay':'7000',# << ******* 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'topicid':'-999',# <<< ********* do not modify}######################################## DO NOT MODIFY BELOW #############################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""VIPERHOSTFROM=""classTmlprotoService(pb2_grpc.TmlprotoServicer):def__init__(self,*args,**kwargs):passasyncdefGetServerResponse(self,request,context):maintopic=default_args['topics']producerid=default_args['producerid']ifrequest!=None:try:message=json.dumps(json.loads(request.message))inputbuf=f"{message}"print("inputbuf=",inputbuf)topicid=default_args['topicid']# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topi> delay=int(args['delay'])enabletls=int(default_args['enabletls'])identifier=default_args['identifier']delay=int(default_args['delay'])try:result=maadstml.viperproducetotopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,producerid,enabletls,delay,'','','',0,inputbuf,'',topicid,identifier)returnpb2.MessageResponse(message="Success producing message",received=True)exceptExceptionase:returnpb2.MessageResponse(message="Failed to produce message, err={} message={}".format(e,inputbuf),received=False)exceptExceptionase:returnpb2.MessageResponse(message="Failed to produce message, err={} message={}".format(e,inputbuf),received=False)returnpb2.MessageResponse(message="Failed to produce message",received=False)asyncdefserve():tsslogging.locallogs("INFO","STEP 3: producing data started")repo=tsslogging.getrepo()tsslogging.tsslogit("gRPC producing DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")mainport=0server_options=[("grpc.keepalive_time_ms",20000),("grpc.keepalive_timeout_ms",10000),("grpc.http2.min_ping_interval_without_data_ms",5000),("grpc.max_connection_idle_ms",10000),("grpc.max_connection_age_ms",30000),("grpc.max_connection_age_grace_ms",5000),("grpc.http2.max_pings_without_data",5),("grpc.keepalive_permit_without_calls",1),]try:server=grpc.aio.server(futures.ThreadPoolExecutor(),options=server_options)# server = grpc.server(futures.ThreadPoolExecutor(max_workers=100))SERVICE_NAMES=(pb2.DESCRIPTOR.services_by_name["Tmlproto"].full_name,reflection.SERVICE_NAME,)reflection.enable_server_reflection(SERVICE_NAMES,server)pb2_grpc.add_TmlprotoServicer_to_server(TmlprotoService(),server)ifos.environ['TSS']=="0":# server_creds = grpc.alts_server_credentials()withopen('/{}/tml-airflow/certs/server.key'.format(repo),'rb')asf:server_key=f.read()withopen('/{}/tml-airflow/certs/server.crt'.format(repo),'rb')asf:server_cert=f.read()server_creds=grpc.ssl_server_credentials([(server_key,server_cert)])mainport=int(default_args['gRPC_Port'])server.add_secure_port("[::]:{}".format(int(default_args['gRPC_Port'])),server_creds)else:server.add_insecure_port("[::]:{}".format(int(default_args['tss_gRPC_Port'])))mainport=int(default_args['tss_gRPC_Port'])exceptExceptionase:tsslogging.locallogs("ERROR","STEP 3: Cannot connect to gRPC server in {} - {}".format(os.path.basename(__file__),e))tsslogging.tsslogit("ERROR: Cannot connect to gRPC server in {} - {}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")print("ERROR: Cannot connect to gRPC server in:",e)returntsslogging.locallogs("INFO","STEP 3: gRPC server started .. waiting for connections")awaitserver.start()print("gRPC server started - listening on port ",mainport)awaitserver.wait_for_termination()asyncdefshutdown_server(server)->None:#logging.info ("Shutting down server...")awaitserver.stop(None)defhandle_sigterm(sig,frame)->None:asyncio.create_task(shutdown_server(server))asyncdefhandle_sigint()->None:loop=asyncio.get_running_loop()forsigin(signal.SIGINT,signal.SIGTERM):loop.add_signal_handler(sig,loop.stop)defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefstartproducing(**context):globalVIPERTOKENglobalVIPERHOSTglobalVIPERPORTglobalHTTPADDRglobalVIPERHOSTFROMtsslogging.locallogs("INFO","STEP 3: producing data started")sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPRODUCE".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPRODUCE".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))hs,VIPERHOSTFROM=tsslogging.getip(VIPERHOST)ti=context['task_instance']ti.xcom_push(key="{}_PRODUCETYPE".format(sname),value='gRPC')ti.xcom_push(key="{}_TOPIC".format(sname),value=default_args['topics'])ifos.environ['TSS']=="0":ti.xcom_push(key="{}_CLIENTPORT".format(sname),value="_{}".format(default_args['gRPC_Port']))else:ti.xcom_push(key="{}_CLIENTPORT".format(sname),value="_{}".format(default_args['tss_gRPC_Port']))ti.xcom_push(key="{}_TSSCLIENTPORT".format(sname),value="_{}".format(default_args['tss_gRPC_Port']))ti.xcom_push(key="{}_TMLCLIENTPORT".format(sname),value="_{}".format(default_args['gRPC_Port']))ti.xcom_push(key="{}_IDENTIFIER".format(sname),value=default_args['identifier'])ti.xcom_push(key="{}_FROMHOST".format(sname),value="{},{}".format(hs,VIPERHOSTFROM))ti.xcom_push(key="{}_TOHOST".format(sname),value=VIPERHOST)ti.xcom_push(key="{}_PORT".format(sname),value=VIPERPORT)ti.xcom_push(key="{}_HTTPADDR".format(sname),value=HTTPADDR)wn=windowname('produce',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-produce","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOSTFROM,VIPERPORT[1:]),"ENTER"])tsslogging.locallogs("INFO","STEP 3: producing data completed")if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]# serve()server=Nonesignal.signal(signal.SIGTERM,handle_sigterm)try:print("Starting asyncio event loop")asyncio.get_event_loop().run_until_complete(serve())exceptKeyboardInterrupt:pass
importgrpcimporttml_grpc_pb2_grpcaspb2_grpcimporttml_grpc_pb2aspb2importsysfromdatetimeimportdatetimeimporttimeimportosimportsubprocessimportbase64importjson# Set kubernetes = 1 if TML solution running in kubernetes# Set kubernetes = 0 if TML solution running in dockerimportwarnings#warnings.filterwarnings("error")#host='tml.tss:443' #- use this if using Kuberneteshost='127.0.01:9002'#- use this if running TML in standalong docker containersys.dont_write_bytecode=True# NOTE YOU WILL NEED TO INSTALL grpcurl in Linuxdefsendgrpcurl(mjson):#first encode the jsonmainjson='{"message":'+json.dumps(mjson)+'}'# mainjson=pb2.Message(message=mjson)sent=0whilesent==0:cmd="grpcurl -insecure -keepalive-time 10 -import-path . -proto tml_grpc.proto -d '{}' {} tmlproto.Tmlproto/GetServerResponse 2>/dev/null".format(mainjson,host)# print("CMD=",cmd.replace("\n",""))cmd=cmd.replace("\n","")print(cmd)proc=subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE)out,err=proc.communicate()proc.terminate()proc.wait()ifout.decode('utf-8')=="":sent=0else:print(out.decode('utf-8'))sent=1breakdefreaddata(inputfile):############################################################### NOTE: You can send any "EXTERNAL" data through this API# It is reading a localfile as an example############################################################try:file1=open(inputfile,'r')print("Data Producing to Kafka Started:",datetime.now())exceptExceptionase:print("ERROR: Something went wrong ",e)returnk=0whileTrue:line=file1.readline()line=line.replace(";"," ")# print("line2=",line)# add lat/long/identifierk=k+1try:ifline=="":#breakfile1.seek(0)k=0print("Reached End of File - Restarting")print("Read End:",datetime.now())continuesendgrpcurl(line.rstrip())time.sleep(.0)exceptExceptionase:print("Main loop error=",e)time.sleep(.5)passif__name__=='__main__':try:inputfile="IoTData.txt"#result = readdata(inputfile) ##### UNCOMMENT TO READ FILEprint(f'{result}')exceptExceptionase:print("ERROR: ",e)
8.5.5.14. STEP 3c.i: gRPC API CLIENT: Explanation
The gRPC API client runs outside the TML solution container. The client api gives you the capability of connecting to your internal systems or devices and stream the data directly to the TML server producer. The TML server producer receives data from gRPC API client and produces the data to Kafka.
Important
The gRPC API client runs outside the TML solution container. This is a very simple and convenient way to stream any type of json data from any device in your
environment.
8.5.5.16. STEP 3d: Produce Data Using LOCALFILE: tml-read-LOCALFILE-step-3-kafka-producetotopic-dag
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimportmaadstmlimporttssloggingimportosimportsubprocessimportjsonimporttimeimportrandomimportthreadingfromcontextlibimportcontextmanagerfromcontextlibimportExitStackimportresys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< *** leave blank'producerid':'iotsolution',# <<< *** Change as needed'topics':'iot-raw-data',# *************** This is one of the topic you created in SYSTEM STEP 2'identifier':'TML solution',# <<< *** Change as needed'inputfile':'',#'/rawdatademo/cisco_network_data.txt', # <<< ***** replace ? to input file name to read. NOTE this data file should be JSON messages per line and stored in the HOST folder mapped to /rawdata folder'delay':'7000',# << ******* 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'topicid':'-999',# <<< ********* do not modify'sleep':0.15,# << Control how fast data streams - if 0 - the data will stream as fast as possible - BUT this may cause connecion reset by peer'docfolder':'mylogs,mylogs2',# You can read TEXT files or any file in these folders that are inside the volume mapped to /rawdata'doctopic':'rtms-stream-mylogs,rtms-stream-mylogs2',# This is the topic that will contain the docfolder file data'chunks':3000,# if 0 the files in docfolder are read line by line, otherwise they are read by chunks i.e. 512'docingestinterval':0,# specify the frequency in seconds to read files in docfolder - if 0 the files are read ONCE}######################################## DO NOT MODIFY BELOW ############################################## This sets the lat/longs for the IoT devices so it can be mapVIPERTOKEN=""VIPERHOST=""VIPERPORT=""defread_in_chunks(file_object,chunk_size=1024):"""Lazy function (generator) to read a file piece by piece. Default chunk size: 1k."""whileTrue:try:ifchunk_size!=0:data=file_object.read(chunk_size).decode('utf-8')iflen(data)>0anddata[-1]!=' ':ct=0forcinreversed(data):ifc==' ':breakct=ct+1ifct<len(data):file_object.seek(file_object.tell()-ct)data=data[:len(data)-ct]else:data=file_object.readline().decode('utf-8')data=data.replace('"','').replace("'","").replace("\\n"," ").replace('\n'," ").replace("\\r"," ").replace('\r'," ").replace(';'," ").replace('&'," ").strip()ifnotdata:breakyielddataexceptExceptionase:breakdefreadallfiles(fd,tr,cs=1024):args=default_argsproducerid='userfilestream'print("fd=",fd.name)forpieceinread_in_chunks(fd,cs):piece=re.sub(' +',' ',piece)pj='{"RTMSMessage":"'+piece+'"}'producetokafka(pj,"","",producerid,tr,"",args)return[]defingestfiles():args=default_argsbuf=default_args['docfolder']chunks=int(default_args['chunks'])maintopic=default_args['doctopic']producerid='userfilestream'interval=int(default_args['docingestinterval'])#gather files in the foldersdirbuf=buf.split(",")# check if user wants to split folders to separate topicsmaintopicbuf=maintopic.split(",")iflen(maintopicbuf)>1:iflen(dirbuf)!=len(maintopicbuf):tsslogging.locallogs("ERROR","STEP 3: Produce LOCALFILE in {} You specified multiple doctopics, then must match docfolder".format(os.path.basename(__file__)))returneliflen(maintopicbuf)==1andlen(dirbuf)>1:foriinrange(len(dirbuf)-1):maintopicbuf.append(maintopic)else:returnwhileTrue:fordr,trinzip(dirbuf,maintopicbuf):filenames=[]ifos.path.isdir("/rawdata/{}".format(dr)):a=[os.path.join("/rawdata/{}".format(dr),f)forfinos.listdir("/rawdata/{}".format(dr))ifos.path.isfile(os.path.join("/rawdata/{}".format(dr),f))]filenames.extend(a)print("filename=",filenames)iflen(filenames)>0:withExitStack()asstack:files=[stack.enter_context(open(i,"rb"))foriinfilenames]contents=[readallfiles(file,tr,chunks)forfileinfiles]ifinterval==0:breakelse:time.sleep(interval)defstartdirread():if'docfolder'notindefault_argsand'doctopic'notindefault_argsand'chunks'notindefault_argsand'docingestinterval'notindefault_args:returnifdefault_args['docfolder']!=''anddefault_args['doctopic']!='':print("INFO startdirread")try:t=threading.Thread(name='child procs',target=ingestfiles)t.start()exceptExceptionase:print(e)defproducetokafka(value,tmlid,identifier,producerid,maintopic,substream,args):inputbuf=valuetopicid=int(args['topicid'])# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=int(args['delay'])enabletls=int(args['enabletls'])identifier=args['identifier']try:result=maadstml.viperproducetotopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,producerid,enabletls,delay,'','','',0,inputbuf,substream,topicid,identifier)# print("result=",result)exceptExceptionase:print("ERROR:",e)defreaddata():repo=tsslogging.getrepo()tsslogging.tsslogit("Localfile producing DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")args=default_argsinputfile=args['inputfile']# MAin Kafka topic to store the real-time datamaintopic=args['topics']producerid=args['producerid']startdirread()ifmaintopic==''orinputfile=='':returnk=0try:file1=open(inputfile,'r')print("Data Producing to Kafka Started:",datetime.now())exceptExceptionase:tsslogging.locallogs("ERROR","Localfile producing DAG in {} - {}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Localfile producing DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")returntsslogging.locallogs("INFO","STEP 3: reading local file..successfully")whileTrue:line=file1.readline()line=line.replace(";"," ")print("line=",line)# add lat/long/identifierk=k+1try:ifline=="":#breakfile1.seek(0)k=0print("Reached End of File - Restarting")print("Read End:",datetime.now())continueproducetokafka(line.strip(),"","",producerid,maintopic,"",args)# change time to speed up or slow down datatime.sleep(args['sleep'])exceptExceptionase:print(e)passfile1.close()defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefstartproducing(**context):tsslogging.locallogs("INFO","STEP 3: producing data started")sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPRODUCE".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPRODUCE".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))VIPERHOSTFROM=tsslogging.getip(VIPERHOST)ti=context['task_instance']ti.xcom_push(key="{}_PRODUCETYPE".format(sname),value='LOCALFILE')ti.xcom_push(key="{}_TOPIC".format(sname),value=default_args['topics'])ti.xcom_push(key="{}_CLIENTPORT".format(sname),value="")ti.xcom_push(key="{}_IDENTIFIER".format(sname),value="{},{}".format(default_args['identifier'],default_args['inputfile']))ti.xcom_push(key="{}_FROMHOST".format(sname),value=VIPERHOSTFROM)ti.xcom_push(key="{}_TOHOST".format(sname),value=VIPERHOST)ti.xcom_push(key="{}_TSSCLIENTPORT".format(sname),value="")ti.xcom_push(key="{}_TMLCLIENTPORT".format(sname),value="")ti.xcom_push(key="{}_PORT".format(sname),value="_{}".format(VIPERPORT))ti.xcom_push(key="{}_HTTPADDR".format(sname),value=HTTPADDR)inputfile=default_args['inputfile']if'step3localfileinputfile'inos.environ:default_args['inputfile']=os.environ['step3localfileinputfile']ti.xcom_push(key="{}_inputfile".format(sname),value=default_args['inputfile'])else:ti.xcom_push(key="{}_inputfile".format(sname),value=default_args['inputfile'])docfolder=''if'docfolder'indefault_argsand'doctopic'indefault_args:docfolder=default_args['docfolder']ti.xcom_push(key="{}_docfolder".format(sname),value=default_args['docfolder'])ti.xcom_push(key="{}_doctopic".format(sname),value=default_args['doctopic'])ti.xcom_push(key="{}_chunks".format(sname),value="_{}".format(default_args['chunks']))ti.xcom_push(key="{}_docingestinterval".format(sname),value="_{}".format(default_args['docingestinterval']))else:ti.xcom_push(key="{}_docfolder".format(sname),value='')ti.xcom_push(key="{}_doctopic".format(sname),value='')ti.xcom_push(key="{}_chunks".format(sname),value='')ti.xcom_push(key="{}_docingestinterval".format(sname),value='')if'step3localfiledocfolder'inos.environ:default_args['docfolder']=os.environ['step3localfiledocfolder']ti.xcom_push(key="{}_docfolder".format(sname),value=default_args['docfolder'])chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('produce',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-produce","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}\"{}\"\"{}\"".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],inputfile,docfolder),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]inputfile=sys.argv[5]default_args['inputfile']=inputfiledocfolder=sys.argv[6]default_args['docfolder']=docfolderreaddata()
The parameters docfolder, doctopic, are needed for https://tml.readthedocs.io/en/latest/tmlbuilds.html#step-4c-preprocesing-3-data-tml-system-step-4c-kafka-preprocess-dag. For details on correlating past information in real-time using sliding time windows, refer to: How TML Maintains Past Memory of Events Using Sliding Time Windows
Parameter
Explanation
inputfile
This is the container path to your local filename. For example,
When you start TSS you must do a volume mapping to the /rawdata
If you are producing data by reading from a local file, you must ensure that when you run the TSS Docker Run Command that you map a volume on your
host system to the rawdata folder in the container; then change the inputfile to /rawdata/<your filename> For example, you need add -v <path to a
local folder on your machine>:/rawdata. to the docker run command:
-v /your_localmachine/foldername:/rawdata:z
For example, your TSS Docker Run should look similar to this - replace /your_localmachine/foldername
with actual name:
TML preprocesses real-time data for every entity along each sliding time window. This is quick and powerful way to accelerate insights from real-time data with very little effort. TML provide over 35 different preprocessing types:
Tip
Watch the YouTube on how to configure the parameters in this dag. YouTube Video
Preprocessing Type
Description
anomprob
This will determine the probability
that there is an anomaly for each
entity in the sliding time windows
anomprobx-y
where X and Y are numbers or “n”,
if “n” means examine all anomalies for recurring
patterns.
This will find the anomalies in the data
ignoring set patterns. They allow you to check
if the anomaly
in the streams are truly anomalies
and not some pattern. For example,
if a IoT device shuts off and turns
on again routinely,
this may be picked up as an anomaly
when in fact it is normal behaviour.
So, to ignore these cases,
if ANOMPROB2-5, tells Viper,
check anomaly with patterns of 2-5 peaks.
If the stream has two classes and these
two classes are like 0 and 1000, and show
a pattern,
then they should not be considered
an anomaly. Meaning, class=0, is the
device shutting down, class=1000
is the device turning back on.
If ANOMPROB3-10, Viper will check for
patterns of classes 3 to 10 to see if
they recur routinely. This is very helpful
to reduce false
positives and false negatives.
autocorr
This will determine the autocorrelation
in the data for each entity in the
sliding time windows
avg
This will determine the average
value for each entity in the sliding
time windows
std
This will determine the standard deviation
value for each entity in the sliding
time windows
datacleanstd#_#
This is a powerful function for data cleaning.
It uses a Standard Deviation Filter (often referred to as Z-Score filtering).
In data science and AI, this is a standard technique used to
automatically remove “outliers” or “noise” from a dataset to ensure
your model is looking at reliable trends rather than anomalies.
It also allows users to eliminate extreme values before the analysis
begins.
The code defines an “envelope” or a safe zone as:
upperLimit: Mean + (Tolerance * StdDev)
lowerLimit: Mean - (Tolerance * StdDev)
where Tolerance = #, Mean=mean of all data in the sliding time window,
StdDev=standard deviation of all data in the sliding time window.
For example, if you specify ddatacleanstd3:
then TML defines the envelope as:
upperLimit: Mean + (3 * StdDev)
lowerLimit: Mean - (3 * StdDev)
any data point inside this envelope (inclusive)
is considered “safe” - any point outside this envelope
is consider an outlier or noise and will be removed from analysis.
You can specify any reasonable number:
datacleanstd5,
upperLimit: Mean + (5 * StdDev)
lowerLimit: Mean - (5 * StdDev)
datacleanstd10,
upperLimit: Mean + (10 * StdDev)
lowerLimit: Mean - (10 * StdDev)
etc.
Or, to delete extreme values first you can specify:
datacleanstd5_10000, this will delete any value
less than -10000 or greater 10000, it will then perform
the Z-score filtering.
This function ensures you have clean data in your analysis
and machine learning/AI.
datacleanmad_#
This is another powerful function for data cleaning.
It uses Mean Absolute Deviation (MAD) to clean the data.
You can choose to delete extreme values first: i.e.
datacleanmad_10000
datacleaniqr_#
This is another powerful function for data cleaning.
It uses Inter Quartile Range (IQR) to clean the data.
You can choose to delete extreme values first: i.e.
datacleaniqr_10000
avgtimediff
This will determine the average time
in seconds between the first and last
timestamp for each entity in sliding windows;
time should be in this
layout:2006-01-02T15:04:05.
consistency
This will check if the data all have
consistent data types. Returns 1 for
consistent data types, 0 otherwise for
each entity in sliding windows
count
This will count the number of numeric
data points in the sliding time
windows for each entity
countstr
This will count the number of string
values in the sliding time windows for
each entity
cv
This will determine the coefficient of
variation average of the median and
the midhinge for each entity in sliding
windows
dataage_[UTC offset]_[timetype]
dataage can be used to check the
last update time of the data in
the data stream from current local
time. You can specify the UTC offset
to adjust the
current time to match the timezone of
the data stream. You can specify timetype
as millisecond, second, minute, hour, day.
For example, if
dataage_1_minute, then this processtype
will compare the last timestamp in the data
stream, to the local UTC time offset +1 and
compute the time difference
between the data stream timestamp and
current local time and return the difference
in minutes. This is a very powerful processtype
for data quality and
data assurance programs for any number of
data streams.
diff
This will find the difference between
the highest and lowest points in
the sliding time windows for each entity
diffmargin
This will find the percentage difference
between the highest and lowest points
in the sliding time windows for each entity
entropy
This will determine the entropy in the
data for each entity in the sliding
time windows; will compute the amount
of information in the data stream.
geodiff
This will determine the distance
in kilimetres between two latitude
and longitude points for each entity
in sliding windows
gm (geometric mean)
This will determine the geometric
mean for each entity in sliding windows
hm (harmonic mean)
This will determine the harmonic
mean for each entity in sliding windows
iqr
This will compute the interquartile
range between Q1 and Q3 for each
entity in sliding windows
kurtosis
This will determine the kurtosis
for each entity in sliding windows
mad
This will determine the mean absolute
deviation for each entity in sliding windows
max
This will determine the maximum
value for each entity in the sliding
time windows
median
This will find the median of
the numeric points in the sliding
time windows for each entity
meanci95
returns a 95% confidence interval:
mean, low, high for each entity in
sliding windows.
meanci99
returns a 99% confidence interval:
mean, low, high for each entity in
sliding windows.
midhinge
This will determine the average
of the first and third quartiles
for each entity in sliding windows
min
This will determine the minimum
value for each entity in the sliding
time windows
outliers
This will find the outliers of the
numeric points in the sliding time
windows for each entity
outliersx-y
where X and Y are numbers or “n”,
if “n” means examine all outliers for
recurring patterns.
This will find the outliers in the data
ignoring set patterns. They allow you to check
if the outlier
in the streams are truly outliers and not
some pattern. For example, if a IoT device
shuts off and turns on again routinely,
this may be picked up as an outlier when
in fact it is normal behaviour. So, to
ignore these cases, if OUTLIER2-5, tells Viper,
check outliers with patterns of 2-5 peaks.
If the stream has two classes and these two
classes are like 0 and 1000, and show a pattern,
then they should not be considered an outlier.
Meaning, class=0, is the device shutting down,
class=1000 is the device turning back on.
If OUTLIER3-10, Viper will check for patterns
of classes 3 to 10 to see if they recur routinely.
Ensuring high data quality is critical for machine learning.
Users can autoclean the data using three methods:
Data Cleaning Preprocessing Type
Description
datacleanstd#_#
This is a powerful function for data cleaning.
It uses a Standard Deviation Filter (often referred to as Z-Score filtering).
In data science and AI, this is a standard technique used to
automatically remove “outliers” or “noise” from a dataset to ensure
your model is looking at reliable trends rather than anomalies.
It also allows users to eliminate extreme values before the analysis
begins.
The code defines an “envelope” or a safe zone as:
upperLimit: Mean + (Tolerance * StdDev)
lowerLimit: Mean - (Tolerance * StdDev)
where Tolerance = #, Mean=mean of all data in the sliding time window,
StdDev=standard deviation of all data in the sliding time window.
For example, if you specify ddatacleanstd3:
then TML defines the envelope as:
upperLimit: Mean + (3 * StdDev)
lowerLimit: Mean - (3 * StdDev)
any data point inside this envelope (inclusive)
is considered “safe” - any point outside this envelope
is consider an outlier or noise and will be removed from analysis.
You can specify any reasonable number:
datacleanstd5,
upperLimit: Mean + (5 * StdDev)
lowerLimit: Mean - (5 * StdDev)
datacleanstd10,
upperLimit: Mean + (10 * StdDev)
lowerLimit: Mean - (10 * StdDev)
etc.
Or, to delete extreme values first you can specify:
datacleanstd5_10000, this will delete any value
less than -10000 or greater 10000, it will then perform
the Z-score filtering.
This function ensures you have clean data in your analysis
and machine learning/AI.
datacleanmad_#
This is another powerful function for data cleaning.
It uses Mean Absolute Deviation (MAD) to clean the data.
You can choose to delete extreme values first: i.e.
datacleanmad_10000
datacleaniqr_#
This is another powerful function for data cleaning.
It uses Inter Quartile Range (IQR) to clean the data.
You can choose to delete extreme values first: i.e.
datacleaniqr_10000
Note
Deleting extreme values could be important because with sensor data one may have very extreme values that may seem normal if the above algorithms have nothing to compare those values against. These extreme values may be due to a sensor malfunction. In this case, deleting extreme values like 999999999 are sensible.
8.5.8. STEP 4: Preprocesing Data Dag: tml-system-step-4-kafka-preprocess-dag
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimportmaadstmlimporttssloggingimportosimportsubprocessimporttimeimportrandomsys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< *** leave blank'producerid':'iotsolution',# <<< *** Change as needed'raw_data_topic':'iot-raw-data',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'preprocess_data_topic':'iot-preprocess',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'maxrows':'800',# <<< ********** Number of offsets to rollback the data stream -i.e. rollback stream by 500 offsets'offset':'-1',# <<< Rollback from the end of the data streams'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'preprocessconditions':'',## <<< Leave blank'delay':'70',# Add a 70 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'array':'0',# do not modify'saveasarray':'1',# do not modify'topicid':'-999',# do not modify'rawdataoutput':'1',# <<< 1 to output raw data used in the preprocessing, 0 do not output'asynctimeout':'120',# <<< 120 seconds for connection timeout'timedelay':'0',# <<< connection delay'tmlfilepath':'',# leave blank'usemysql':'1',# do not modify'streamstojoin':'',# leave blank'identifier':'IoT device performance and failures',# <<< ** Change as needed'preprocesstypes':'anomprob,trend,avg',# <<< **** MAIN PREPROCESS TYPES CHNAGE AS NEEDED refer to https://tml-readthedocs.readthedocs.io/en/latest/'pathtotmlattrs':'oem=n/a,lat=n/a,long=n/a,location=n/a,identifier=n/a',# Change as needed'jsoncriteria':'uid=metadata.dsn,filter:allrecords~\ subtopics=metadata.property_name~\ values=datapoint.value~\ identifiers=metadata.display_name~\ datetime=datapoint.updated_at~\ msgid=datapoint.id~\ latlong=lat:long'# <<< **** Specify your json criteria. Here is an example of a multiline json -- refer to https://tml-readthedocs.readthedocs.io/en/latest/}######################################## DO NOT MODIFY BELOW #############################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""defprocesstransactiondata():globalVIPERTOKENglobalVIPERHOSTglobalVIPERPORTglobalHTTPADDRpreprocesstopic=default_args['preprocess_data_topic']maintopic=default_args['raw_data_topic']mainproducerid=default_args['producerid']############################################################################################################## PREPROCESS DATA STREAMS# Roll back each data stream by 10 percent - change this to a larger number if you want more data# For supervised machine learning you need a minimum of 30 data points in each streammaxrows=int(default_args['maxrows'])# Go to the last offset of each stream: If lastoffset=500, then this function will rollback the# streams to offset=500-50=450offset=int(default_args['offset'])# Max wait time for Kafka to response on milliseconds - you can increase this number if#maintopic to produce the preprocess data totopic=maintopic# producerid of the topicproducerid=mainproducerid# use the host in Viper.env filebrokerhost=default_args['brokerhost']# use the port in Viper.env filebrokerport=int(default_args['brokerport'])#if load balancing enter the microsericeid to route the HTTP to a specific machinemicroserviceid=default_args['microserviceid']# You can preprocess with the following functions: MAX, MIN, SUM, AVG, COUNT, DIFF,OUTLIERS# here we will take max values of the arcturus-humidity, we will Diff arcturus-temperature, and average arcturus-Light_Intensity# NOTE: The number of process logic functions MUST match the streams - the operations will be applied in the same order#preprocessconditions=default_args['preprocessconditions']# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=int(default_args['delay'])# USE TLS encryption when sending to Kafka Cloud (GCP/AWS/Azure)enabletls=int(default_args['enabletls'])array=int(default_args['array'])saveasarray=int(default_args['saveasarray'])topicid=int(default_args['topicid'])rawdataoutput=int(default_args['rawdataoutput'])asynctimeout=int(default_args['asynctimeout'])timedelay=int(default_args['timedelay'])jsoncriteria=default_args['jsoncriteria']tmlfilepath=default_args['tmlfilepath']usemysql=int(default_args['usemysql'])streamstojoin=default_args['streamstojoin']identifier=default_args['identifier']# if dataage - use:dataage_utcoffset_timetypepreprocesstypes=default_args['preprocesstypes']pathtotmlattrs=default_args['pathtotmlattrs']try:result=maadstml.viperpreprocesscustomjson(VIPERTOKEN,VIPERHOST,VIPERPORT,topic,producerid,offset,jsoncriteria,rawdataoutput,maxrows,enabletls,delay,brokerhost,brokerport,microserviceid,topicid,streamstojoin,preprocesstypes,preprocessconditions,identifier,preprocesstopic,array,saveasarray,timedelay,asynctimeout,usemysql,tmlfilepath,pathtotmlattrs)#print(result)returnresultexceptExceptionase:print(e)returnedefwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefdopreprocessing(**context):tsslogging.locallogs("INFO","STEP 4: Preprocessing started")sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))if'step4raw_data_topic'inos.environ:default_args['raw_data_topic']=os.environ['step4raw_data_topic']if'step4preprocesstypes'inos.environ:default_args['preprocesstypes']=os.environ['step4preprocesstypes']if'step4jsoncriteria'inos.environ:default_args['jsoncriteria']=os.environ['step4jsoncriteria']if'step4preprocess_data_topic'inos.environ:default_args['preprocess_data_topic']=os.environ['step4preprocess_data_topic']ti=context['task_instance']ti.xcom_push(key="{}_raw_data_topic".format(sname),value=default_args['raw_data_topic'])ti.xcom_push(key="{}_preprocess_data_topic".format(sname),value=default_args['preprocess_data_topic'])ti.xcom_push(key="{}_preprocessconditions".format(sname),value=default_args['preprocessconditions'])ti.xcom_push(key="{}_delay".format(sname),value="_{}".format(default_args['delay']))ti.xcom_push(key="{}_array".format(sname),value="_{}".format(default_args['array']))ti.xcom_push(key="{}_saveasarray".format(sname),value="_{}".format(default_args['saveasarray']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_rawdataoutput".format(sname),value="_{}".format(default_args['rawdataoutput']))ti.xcom_push(key="{}_asynctimeout".format(sname),value="_{}".format(default_args['asynctimeout']))ti.xcom_push(key="{}_timedelay".format(sname),value="_{}".format(default_args['timedelay']))ti.xcom_push(key="{}_usemysql".format(sname),value="_{}".format(default_args['usemysql']))ti.xcom_push(key="{}_preprocesstypes".format(sname),value=default_args['preprocesstypes'])ti.xcom_push(key="{}_pathtotmlattrs".format(sname),value=default_args['pathtotmlattrs'])ti.xcom_push(key="{}_identifier".format(sname),value=default_args['identifier'])ti.xcom_push(key="{}_jsoncriteria".format(sname),value=default_args['jsoncriteria'])maxrows=default_args['maxrows']if'step4maxrows'inos.environ:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(os.environ['step4maxrows']))maxrows=os.environ['step4maxrows']else:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(default_args['maxrows']))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('preprocess',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-preprocess","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}{}\"{}\"\"{}\"\"{}\"\"{}\"".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],maxrows,default_args['raw_data_topic'],default_args['preprocesstypes'],default_args['jsoncriteria'],default_args['preprocess_data_topic']),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()try:tsslogging.tsslogit("Preprocessing DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")exceptExceptionase:#git push -f origin mainos.chdir("/{}".format(repo))subprocess.call("git push -f origin main",shell=True)VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]maxrows=sys.argv[5]default_args['maxrows']=maxrowsdefault_args['raw_data_topic']=sys.argv[6]default_args['preprocesstypes']=sys.argv[7]default_args['jsoncriteria']=sys.argv[8]default_args['preprocess_data_topic']=sys.argv[9]tsslogging.locallogs("INFO","STEP 4: Preprocessing started")whileTrue:try:processtransactiondata()time.sleep(1)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 4: Preprocessing DAG in {}{}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Preprocessing DAG in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")break
This Step 4a is similar to Step 4b, only difference is it allows for jsoncriteria.
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimportmaadstmlimporttssloggingimportosimportsubprocessimporttimeimportrandomsys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< *** leave blank'producerid':'iotsolution',# <<< *** Change as needed'raw_data_topic':'rtms-pgpt-ai',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'preprocess_data_topic':'rtms-pgpt-ai-mitre',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'maxrows':'50',# <<< ********** Number of offsets to rollback the data stream -i.e. rollback stream by 500 offsets'offset':'-1',# <<< Rollback from the end of the data streams'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'preprocessconditions':'',## <<< Leave blank'delay':'70',# Add a 70 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'array':'0',# do not modify'saveasarray':'1',# do not modify'topicid':'-999',# do not modify'rawdataoutput':'1',# <<< 1 to output raw data used in the preprocessing, 0 do not output'asynctimeout':'120',# <<< 120 seconds for connection timeout'timedelay':'0',# <<< connection delay'tmlfilepath':'',# leave blank'usemysql':'1',# do not modify'streamstojoin':'',# Change as needed - THESE VARIABLES ARE CREATED BY TML IN tml_system_step_4_kafka_preprocess2_dag.py'identifier':'Mitre ATTCK',# <<< ** Change as needed'preprocesstypes':'avg',# <<< **** MAIN PREPROCESS TYPES CHNAGE AS NEEDED refer to https://tml-readthedocs.readthedocs.io/en/latest/'pathtotmlattrs':'oem=n/a,lat=n/a,long=n/a,location=n/a,identifier=n/a',# Change as needed'jsoncriteria':'uid=tactic,filter:allrecords~\subtopics=technique,technique,technique~\values=FinalAttackScore,FinalPatternScore,RTMSSCORE~\identifiers=FinalAttackScore,FinalPatternScore,RTMSSCORE~\datetime=TimeStamp~\msgid=Entity,PartitionOffsetFound,NumAttackWindowsFound,NumPatternWindowsFound,SearchEntity,rtmsfolder,CurrentRTMSMAXWINDOW~\latlong='# <<< **** Specify your json criteria. Here is an example of a multiline json -- refer to https://tml-readthedocs.readthedocs.io/en/latest/}######################################## DO NOT MODIFY BELOW #############################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""defprocesstransactiondata():globalVIPERTOKENglobalVIPERHOSTglobalVIPERPORTglobalHTTPADDRpreprocesstopic=default_args['preprocess_data_topic']maintopic=default_args['raw_data_topic']mainproducerid=default_args['producerid']############################################################################################################## PREPROCESS DATA STREAMS# Roll back each data stream by 10 percent - change this to a larger number if you want more data# For supervised machine learning you need a minimum of 30 data points in each streammaxrows=int(default_args['maxrows'])# Go to the last offset of each stream: If lastoffset=500, then this function will rollback the# streams to offset=500-50=450offset=int(default_args['offset'])# Max wait time for Kafka to response on milliseconds - you can increase this number if#maintopic to produce the preprocess data totopic=maintopic# producerid of the topicproducerid=mainproducerid# use the host in Viper.env filebrokerhost=default_args['brokerhost']# use the port in Viper.env filebrokerport=int(default_args['brokerport'])#if load balancing enter the microsericeid to route the HTTP to a specific machinemicroserviceid=default_args['microserviceid']# You can preprocess with the following functions: MAX, MIN, SUM, AVG, COUNT, DIFF,OUTLIERS# here we will take max values of the arcturus-humidity, we will Diff arcturus-temperature, and average arcturus-Light_Intensity# NOTE: The number of process logic functions MUST match the streams - the operations will be applied in the same order#preprocessconditions=default_args['preprocessconditions']# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=int(default_args['delay'])# USE TLS encryption when sending to Kafka Cloud (GCP/AWS/Azure)enabletls=int(default_args['enabletls'])array=int(default_args['array'])saveasarray=int(default_args['saveasarray'])topicid=int(default_args['topicid'])rawdataoutput=int(default_args['rawdataoutput'])asynctimeout=int(default_args['asynctimeout'])timedelay=int(default_args['timedelay'])jsoncriteria=default_args['jsoncriteria']tmlfilepath=default_args['tmlfilepath']usemysql=int(default_args['usemysql'])streamstojoin=default_args['streamstojoin']identifier=default_args['identifier']# if dataage - use:dataage_utcoffset_timetypepreprocesstypes=default_args['preprocesstypes']try:result=maadstml.viperpreprocessproducetotopicstream(VIPERTOKEN,VIPERHOST,VIPERPORT,topic,producerid,offset,maxrows,enabletls,delay,brokerhost,brokerport,microserviceid,topicid,streamstojoin,preprocesstypes,preprocessconditions,identifier,preprocesstopic,jsoncriteria)#print(result)exceptExceptionase:print("ERROR:",e)defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefdopreprocessing(**context):tsslogging.locallogs("INFO","STEP 4a: Preprocessing started")sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS1".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS1".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))if'step4ajsoncriteria'inos.environ:default_args['jsoncriteria']=os.environ['step4ajsoncriteria']if'step4apreprocesstypes'inos.environ:default_args['preprocesstypes']=os.environ['step4apreprocesstypes']if'step4araw_data_topic'inos.environ:default_args['raw_data_topic']=os.environ['step4araw_data_topic']if'step4apreprocess_data_topic'inos.environ:default_args['preprocess_data_topic']=os.environ['step4apreprocess_data_topic']ti=context['task_instance']ti.xcom_push(key="{}_raw_data_topic".format(sname),value=default_args['raw_data_topic'])ti.xcom_push(key="{}_preprocess_data_topic".format(sname),value=default_args['preprocess_data_topic'])ti.xcom_push(key="{}_preprocessconditions".format(sname),value=default_args['preprocessconditions'])ti.xcom_push(key="{}_delay".format(sname),value="_{}".format(default_args['delay']))ti.xcom_push(key="{}_array".format(sname),value="_{}".format(default_args['array']))ti.xcom_push(key="{}_saveasarray".format(sname),value="_{}".format(default_args['saveasarray']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_rawdataoutput".format(sname),value="_{}".format(default_args['rawdataoutput']))ti.xcom_push(key="{}_asynctimeout".format(sname),value="_{}".format(default_args['asynctimeout']))ti.xcom_push(key="{}_timedelay".format(sname),value="_{}".format(default_args['timedelay']))ti.xcom_push(key="{}_usemysql".format(sname),value="_{}".format(default_args['usemysql']))ti.xcom_push(key="{}_preprocesstypes".format(sname),value=default_args['preprocesstypes'])ti.xcom_push(key="{}_pathtotmlattrs".format(sname),value=default_args['pathtotmlattrs'])ti.xcom_push(key="{}_identifier".format(sname),value=default_args['identifier'])ti.xcom_push(key="{}_jsoncriteria".format(sname),value=default_args['jsoncriteria'])maxrows=default_args['maxrows']if'step4amaxrows'inos.environ:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(os.environ['step4amaxrows']))maxrows=os.environ['step4amaxrows']else:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(default_args['maxrows']))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('preprocess1',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-preprocess1","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}{}\"{}\"\"{}\"\"{}\"\"{}\"".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],maxrows,default_args['jsoncriteria'],default_args['preprocesstypes'],default_args['raw_data_topic'],default_args['preprocess_data_topic']),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()try:tsslogging.tsslogit("Preprocessing DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")exceptExceptionase:#git push -f origin mainos.chdir("/{}".format(repo))subprocess.call("git push -f origin main",shell=True)VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]maxrows=sys.argv[5]default_args['maxrows']=maxrowsdefault_args['jsoncriteria']=sys.argv[6]default_args['preprocesstypes']=sys.argv[7]default_args['raw_data_topic']=sys.argv[8]default_args['preprocess_data_topic']=sys.argv[9]tsslogging.locallogs("INFO","STEP 4a: Preprocessing started")whileTrue:try:processtransactiondata()time.sleep(1)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 4a: Preprocessing DAG in {}{}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Preprocessing DAG in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")break
Watch the YouTube that discussed how to configure this Dag, used to process preprocessed variables in Step 4. YouTube Video
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimportmaadstmlimporttssloggingimportosimportsubprocessimporttimeimportrandomsys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< *** leave blank'producerid':'iotsolution',# <<< *** Change as needed'raw_data_topic':'iot-preprocess',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'preprocess_data_topic':'iot-preprocess2',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'maxrows':'350',# <<< ********** Number of offsets to rollback the data stream -i.e. rollback stream by 500 offsets'offset':'-1',# <<< Rollback from the end of the data streams'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'preprocessconditions':'',## <<< Leave blank'delay':'70',# Add a 70 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'array':'0',# do not modify'saveasarray':'1',# do not modify'topicid':'-1',# do not modify'rawdataoutput':'1',# <<< 1 to output raw data used in the preprocessing, 0 do not output'asynctimeout':'120',# <<< 120 seconds for connection timeout'timedelay':'0',# <<< connection delay'tmlfilepath':'',# leave blank'usemysql':'1',# do not modify'streamstojoin':'Voltage_preprocessed_AnomProb,Current_preprocessed_AnomProb',# Change as needed - THESE VARIABLES ARE CREATED BY TML IN tml_system_step_4_kafka_preprocess2_dag.py'identifier':'IoT device performance and failures',# <<< ** Change as needed'preprocesstypes':'avg,avg',# <<< **** MAIN PREPROCESS TYPES CHNAGE AS NEEDED refer to https://tml-readthedocs.readthedocs.io/en/latest/'pathtotmlattrs':'oem=n/a,lat=n/a,long=n/a,location=n/a,identifier=n/a',# Change as needed'jsoncriteria':'',# <<< **** Specify your json criteria. Here is an example of a multiline json -- refer to https://tml-readthedocs.readthedocs.io/en/latest/}######################################## DO NOT MODIFY BELOW #############################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""defprocesstransactiondata():globalVIPERTOKENglobalVIPERHOSTglobalVIPERPORTglobalHTTPADDRpreprocesstopic=default_args['preprocess_data_topic']maintopic=default_args['raw_data_topic']mainproducerid=default_args['producerid']############################################################################################################## PREPROCESS DATA STREAMS# Roll back each data stream by 10 percent - change this to a larger number if you want more data# For supervised machine learning you need a minimum of 30 data points in each streammaxrows=int(default_args['maxrows'])# Go to the last offset of each stream: If lastoffset=500, then this function will rollback the# streams to offset=500-50=450offset=int(default_args['offset'])# Max wait time for Kafka to response on milliseconds - you can increase this number if#maintopic to produce the preprocess data totopic=maintopic# producerid of the topicproducerid=mainproducerid# use the host in Viper.env filebrokerhost=default_args['brokerhost']# use the port in Viper.env filebrokerport=int(default_args['brokerport'])#if load balancing enter the microsericeid to route the HTTP to a specific machinemicroserviceid=default_args['microserviceid']# You can preprocess with the following functions: MAX, MIN, SUM, AVG, COUNT, DIFF,OUTLIERS# here we will take max values of the arcturus-humidity, we will Diff arcturus-temperature, and average arcturus-Light_Intensity# NOTE: The number of process logic functions MUST match the streams - the operations will be applied in the same order#preprocessconditions=default_args['preprocessconditions']# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=int(default_args['delay'])# USE TLS encryption when sending to Kafka Cloud (GCP/AWS/Azure)enabletls=int(default_args['enabletls'])array=int(default_args['array'])saveasarray=int(default_args['saveasarray'])topicid=int(default_args['topicid'])rawdataoutput=int(default_args['rawdataoutput'])asynctimeout=int(default_args['asynctimeout'])timedelay=int(default_args['timedelay'])jsoncriteria=default_args['jsoncriteria']tmlfilepath=default_args['tmlfilepath']usemysql=int(default_args['usemysql'])streamstojoin=default_args['streamstojoin']identifier=default_args['identifier']# if dataage - use:dataage_utcoffset_timetypepreprocesstypes=default_args['preprocesstypes']pathtotmlattrs=default_args['pathtotmlattrs']try:result=maadstml.viperpreprocessproducetotopicstream(VIPERTOKEN,VIPERHOST,VIPERPORT,topic,producerid,offset,maxrows,enabletls,delay,brokerhost,brokerport,microserviceid,topicid,streamstojoin,preprocesstypes,preprocessconditions,identifier,preprocesstopic)#print(result)exceptExceptionase:print("ERROR:",e)defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefdopreprocessing(**context):sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS2".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS2".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))if'step4bpreprocesstypes'inos.environ:default_args['preprocesstypes']=os.environ['step4bpreprocesstypes']if'step4bjsoncriteria'inos.environ:default_args['jsoncriteria']=os.environ['step4bjsoncriteria']if'step4braw_data_topic'inos.environ:default_args['raw_data_topic']=os.environ['step4braw_data_topic']if'step4bpreprocess_data_topic'inos.environ:default_args['preprocess_data_topic']=os.environ['step4bpreprocess_data_topic']ti=context['task_instance']ti.xcom_push(key="{}_raw_data_topic".format(sname),value=default_args['raw_data_topic'])ti.xcom_push(key="{}_preprocess_data_topic".format(sname),value=default_args['preprocess_data_topic'])ti.xcom_push(key="{}_preprocessconditions".format(sname),value=default_args['preprocessconditions'])ti.xcom_push(key="{}_delay".format(sname),value="_{}".format(default_args['delay']))ti.xcom_push(key="{}_array".format(sname),value="_{}".format(default_args['array']))ti.xcom_push(key="{}_saveasarray".format(sname),value="_{}".format(default_args['saveasarray']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_rawdataoutput".format(sname),value="_{}".format(default_args['rawdataoutput']))ti.xcom_push(key="{}_asynctimeout".format(sname),value="_{}".format(default_args['asynctimeout']))ti.xcom_push(key="{}_timedelay".format(sname),value="_{}".format(default_args['timedelay']))ti.xcom_push(key="{}_usemysql".format(sname),value="_{}".format(default_args['usemysql']))ti.xcom_push(key="{}_preprocesstypes".format(sname),value=default_args['preprocesstypes'])ti.xcom_push(key="{}_pathtotmlattrs".format(sname),value=default_args['pathtotmlattrs'])ti.xcom_push(key="{}_identifier".format(sname),value=default_args['identifier'])ti.xcom_push(key="{}_jsoncriteria".format(sname),value=default_args['jsoncriteria'])maxrows=default_args['maxrows']if'step4bmaxrows'inos.environ:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(os.environ['step4bmaxrows']))maxrows=os.environ['step4bmaxrows']else:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(default_args['maxrows']))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('preprocess2',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-preprocess2","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}{}\"{}\"\"{}\"\"{}\"\"{}\"".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],maxrows,default_args['preprocesstypes'],default_args['jsoncriteria'],default_args['raw_data_topic'],default_args['preprocess_data_topic']),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()try:tsslogging.tsslogit("Preprocessing2 DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")exceptExceptionase:#git push -f origin mainos.chdir("/{}".format(repo))subprocess.call("git push -f origin main",shell=True)VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]maxrows=sys.argv[5]default_args['maxrows']=maxrowsdefault_args['preprocesstypes']=sys.argv[6]default_args['jsoncriteria']=sys.argv[7]default_args['raw_data_topic']=sys.argv[8]default_args['preprocess_data_topic']=sys.argv[9]tsslogging.locallogs("INFO","STEP 4b: Preprocessing 2 started")whileTrue:try:processtransactiondata()time.sleep(1)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 4b: Preprocessing2 DAG in {}{}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Preprocessing2 DAG in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")break
This Step 4c is a very powerful task that will incorporate real-time memory using sliding time windows: for details see
How TML Maintains Past Memory of Events Using Sliding Time Windows.
Users can cross-reference entities with TXT files. The advantage of this is now you can incorporate machine learning outputs
with TXT files to mesh data together to get a deeper understanding of each entity. This could be important to analyse log files
for any search terms that could be unusual like: authentication failures, unknow users, etc.
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimportmaadstmlimporttssloggingimportosimportsubprocessimporttimeimportrandomimportbase64importthreadingimportshutilsys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< *** leave blank'producerid':'rtmssolution',# <<< *** Change as needed'raw_data_topic':'iot-preprocess',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'preprocess_data_topic':'rtms-preprocess',# *************** INCLUDE ONLY ONE TOPIC - This is one of the topic you created in SYSTEM STEP 2'maxrows':'200',# <<< ********** Number of offsets to rollback the data stream -i.e. rollback stream by 500 offsets'offset':'-1',# <<< Rollback from the end of the data streams'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'delay':'70',# Add a 70 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topic'array':'0',# do not modify'saveasarray':'1',# do not modify'topicid':'-999',# do not modify'rawdataoutput':'1',# <<< 1 to output raw data used in the preprocessing, 0 do not output'asynctimeout':'120',# <<< 120 seconds for connection timeout'timedelay':'0',# <<< connection delay'tmlfilepath':'',# leave blank'usemysql':'1',# do not modify'rtmsstream':'rtms-stream-mylogs',# Change as needed - STREAM containing log file data (or other data) for RTMS# If entitystream is empty, TML uses the preprocess type only.'identifier':'RTMS Past Memory of Events',# <<< ** Change as needed'searchterms':'rgx:p([a-z]+)ch ~~~ |authentication failure,--entity-- password failure ~~~ |unknown--entity--',# main Search terms, if AND add @, if OR use | s first characters, default OR# Must include --entity-- if correlating with entity - this will be replaced# dynamically with the entities found in raw_data_topic'localsearchtermfolder':'|mysearchfile1,|mysearchfile2',# Specify a folder of files containing search terms - each term must be on a new line - use comma# to apply each folder to the rtmstream topic# Use @ =AND, |=OR to specify whether the terms in the file should be AND, OR# For example, @mysearchfolder1,|mysearchfolder2, means all terms in mysearchfolder1 should be AND# |mysearchfolder2, means all search terms should be OR'ed'localsearchtermfolderinterval':'60',# This is the number of seconds between reading the localsearchtermfolder. For example, if 60,# The files will be read every 60 seconds - and searchterms will be updated'rememberpastwindows':'500',# Past windows to remember'patternwindowthreshold':'30',# check for the number of patterns for the items in searchterms'rtmsscorethreshold':'0.6',# RTMS score threshold i.e. '0.8''rtmsscorethresholdtopic':'rtmstopic',# All rtms score greater than rtmsscorethreshold will be streamed to this topic'attackscorethreshold':'0.6',# Attack score threshold i.e. '0.8''attackscorethresholdtopic':'attacktopic',# All attack score greater than attackscorethreshold will be streamed to this topic'patternscorethreshold':'0.6',# Pattern score threshold i.e. '0.8''patternscorethresholdtopic':'patterntopic',# All pattern score greater thn patternscorethreshold will be streamed to this topic'rtmsfoldername':'rtms','rtmsmaxwindows':'10000'}######################################## DO NOT MODIFY BELOW #############################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""defprocesstransactiondata():globalVIPERTOKENglobalVIPERHOSTglobalVIPERPORTglobalHTTPADDRpreprocesstopic=default_args['preprocess_data_topic']maintopic=default_args['raw_data_topic']mainproducerid=default_args['producerid']############################################################################################################## PREPROCESS DATA STREAMS# Roll back each data stream by 10 percent - change this to a larger number if you want more data# For supervised machine learning you need a minimum of 30 data points in each streammaxrows=int(default_args['maxrows'])# Go to the last offset of each stream: If lastoffset=500, then this function will rollback the# streams to offset=500-50=450offset=int(default_args['offset'])# Max wait time for Kafka to response on milliseconds - you can increase this number if#maintopic to produce the preprocess data totopic=maintopic# producerid of the topicproducerid=mainproducerid# use the host in Viper.env filebrokerhost=default_args['brokerhost']# use the port in Viper.env filebrokerport=int(default_args['brokerport'])#if load balancing enter the microsericeid to route the HTTP to a specific machinemicroserviceid=default_args['microserviceid']# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=int(default_args['delay'])# USE TLS encryption when sending to Kafka Cloud (GCP/AWS/Azure)enabletls=int(default_args['enabletls'])array=int(default_args['array'])saveasarray=int(default_args['saveasarray'])topicid=int(default_args['topicid'])rawdataoutput=int(default_args['rawdataoutput'])asynctimeout=int(default_args['asynctimeout'])timedelay=int(default_args['timedelay'])tmlfilepath=default_args['tmlfilepath']usemysql=int(default_args['usemysql'])rtmsstream=default_args['rtmsstream']identifier=default_args['identifier']searchterms=default_args['searchterms']rememberpastwindows=default_args['rememberpastwindows']patternwindowthreshold=default_args['patternwindowthreshold']rtmsscorethreshold=default_args['rtmsscorethreshold']rtmsscorethresholdtopic=default_args['rtmsscorethresholdtopic']attackscorethreshold=default_args['attackscorethreshold']attackscorethresholdtopic=default_args['attackscorethresholdtopic']patternscorethreshold=default_args['patternscorethreshold']patternscorethresholdtopic=default_args['patternscorethresholdtopic']rtmsmaxwindows=default_args['rtmsmaxwindows']searchterms=str(base64.b64encode(searchterms.encode('utf-8')))try:result=maadstml.viperpreprocessrtms(VIPERTOKEN,VIPERHOST,VIPERPORT,topic,producerid,offset,maxrows,enabletls,delay,brokerhost,brokerport,microserviceid,topicid,rtmsstream,searchterms,rememberpastwindows,identifier,preprocesstopic,patternwindowthreshold,array,saveasarray,rawdataoutput,rtmsscorethreshold,rtmsscorethresholdtopic,attackscorethreshold,attackscorethresholdtopic,patternscorethreshold,patternscorethresholdtopic,rtmsmaxwindows)# print(result)exceptExceptionase:print("ERROR:",e)defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwn# add any non-fle search terms to the file search termsdefupdatesearchterms(searchtermsfile,regx):# check if search terms existstcurr=default_args['searchterms']stcurrfile=searchtermsfilemainsearchterms=""iflen(regx)>0:forrinregx:mainsearchterms=mainsearchterms+r+"~~~"ifstcurr!="":stcurrarr=stcurr.split("~~~")stcurrarrfile=stcurrfile.split("~~~")forainstcurrarr:stcurrarrfile.append(a)stcurrarrfile=set(stcurrarrfile)mainsearchterms=mainsearchterms+'~~~'.join(stcurrarrfile)#mainsearchterms = mainsearchterms[:-1]else:stcurrarrfile=stcurrfile.split("~~~")stcurrarrfile=set(stcurrarrfile)mainsearchterms=mainsearchterms+'~~~'.join(stcurrarrfile)#mainsearchterms = mainsearchterms[:-1]returnmainsearchtermsdefingestfiles():buf=default_args['localsearchtermfolder']interval=int(default_args['localsearchtermfolderinterval'])searchtermsfile=""dirbuf=buf.split(",")iflen(dirbuf)==0:returnwhileTrue:try:lg=""buf=default_args['localsearchtermfolder']interval=int(default_args['localsearchtermfolderinterval'])searchtermsfile=""dirbuf=buf.split(",")rgx=[]fordrindirbuf:filenames=[]linebuf=""ibx=[]ifdr!="":ifdr[0]=='@':dr=dr[1:]lg="@"elifdr[0]=='|':dr=dr[1:]lg="|"else:lg="|"ifos.path.isdir("/rawdata/{}".format(dr)):a=[os.path.join("/rawdata/{}".format(dr),f)forfinos.listdir("/rawdata/{}".format(dr))ifos.path.isfile(os.path.join("/rawdata/{}".format(dr),f))]filenames.extend(a)iflen(filenames)>0:filenames=set(filenames)forfdrinfilenames:withopen(fdr)asf:lines=[line.rstrip('\n').strip()forlineinf]lines=set(lines)# check regexforminlines:iflen(m)>0:if'rgx:'inmandm[:4]=="rgx:":rgx.append(m)elif'~~~'inmandm[:3]=="~~~":ibx.append(m)else:m=m.replace(","," ")ifm[0]!="~":linebuf=linebuf+m+","iflinebuf!="":linebuf=linebuf[:-1]searchtermsfile=searchtermsfile+lg+linebuf+"~~~"iflen(ibx)>0:ibxs=''.join(ibx)ibxs=ibxs[3:]searchtermsfile=searchtermsfile+ibxs+"~~~"ifsearchtermsfile!="":searchtermsfile=searchtermsfile[:-3]searchtermsfile=updatesearchterms(searchtermsfile,rgx)default_args['searchterms']=searchtermsfileprint("INFO:",searchtermsfile)ifinterval==0:breakelse:time.sleep(interval)exceptExceptionase:print("ERROR: ingesting files:",e)continuedefstartdirread():if'localsearchtermfolder'notindefault_args:returnifdefault_args['localsearchtermfolder']!=''anddefault_args['localsearchtermfolderinterval']!='':print("INFO startdirread")try:t=threading.Thread(name='child procs',target=ingestfiles)t.start()exceptExceptionase:print(e)defdopreprocessing(**context):sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS3".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS3".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))ti=context['task_instance']ti.xcom_push(key="{}_raw_data_topic".format(sname),value=default_args['raw_data_topic'])ti.xcom_push(key="{}_preprocess_data_topic".format(sname),value=default_args['preprocess_data_topic'])ti.xcom_push(key="{}_delay".format(sname),value="_{}".format(default_args['delay']))ti.xcom_push(key="{}_array".format(sname),value="_{}".format(default_args['array']))ti.xcom_push(key="{}_saveasarray".format(sname),value="_{}".format(default_args['saveasarray']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_rawdataoutput".format(sname),value="_{}".format(default_args['rawdataoutput']))ti.xcom_push(key="{}_asynctimeout".format(sname),value="_{}".format(default_args['asynctimeout']))ti.xcom_push(key="{}_timedelay".format(sname),value="_{}".format(default_args['timedelay']))ti.xcom_push(key="{}_usemysql".format(sname),value="_{}".format(default_args['usemysql']))ti.xcom_push(key="{}_identifier".format(sname),value=default_args['identifier'])ti.xcom_push(key="{}_rtmsscorethresholdtopic".format(sname),value=default_args['rtmsscorethresholdtopic'])ti.xcom_push(key="{}_attackscorethresholdtopic".format(sname),value=default_args['attackscorethresholdtopic'])ti.xcom_push(key="{}_patternscorethresholdtopic".format(sname),value=default_args['patternscorethresholdtopic'])localsearchtermfolder=default_args['localsearchtermfolder']if'step4clocalsearchtermfolder'inos.environ:ti.xcom_push(key="{}_localsearchtermfolder".format(sname),value=os.environ['step4clocalsearchtermfolder'])localsearchtermfolder=os.environ['step4clocalsearchtermfolder']else:ti.xcom_push(key="{}_localsearchtermfolder".format(sname),value=default_args['localsearchtermfolder'])localsearchtermfolderinterval=default_args['localsearchtermfolderinterval']if'step4clocalsearchtermfolderinterval'inos.environ:ti.xcom_push(key="{}_localsearchtermfolderinterval".format(sname),value=os.environ['step4clocalsearchtermfolderinterval'])localsearchtermfolderinterval=os.environ['step4clocalsearchtermfolderinterval']else:ti.xcom_push(key="{}_localsearchtermfolderinterval".format(sname),value="_{}".format(default_args['localsearchtermfolderinterval']))rtmsstream=default_args['rtmsstream']if'step4crtmsstream'inos.environ:ti.xcom_push(key="{}_rtmsstream".format(sname),value=os.environ['step4crtmsstream'])rtmsstream=os.environ['step4crtmsstream']else:ti.xcom_push(key="{}_rtmsstream".format(sname),value=default_args['rtmsstream'])maxrows=default_args['maxrows']if'step4cmaxrows'inos.environ:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(os.environ['step4cmaxrows']))maxrows=os.environ['step4cmaxrows']else:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(default_args['maxrows']))searchterms=default_args['searchterms']if'step4csearchterms'inos.environ:ti.xcom_push(key="{}_searchterms".format(sname),value="{}".format(os.environ['step4csearchterms']))searchterms=os.environ['step4csearchterms']else:ti.xcom_push(key="{}_searchterms".format(sname),value=default_args['searchterms'])raw_data_topic=default_args['raw_data_topic']if'step4crawdatatopic'inos.environ:ti.xcom_push(key="{}_raw_data_topic".format(sname),value="{}".format(os.environ['step4crawdatatopic']))raw_data_topic=os.environ['step4crawdatatopic']else:ti.xcom_push(key="{}_raw_data_topic".format(sname),value=default_args['raw_data_topic'])rememberpastwindows=default_args['rememberpastwindows']if'step4crememberpastwindows'inos.environ:ti.xcom_push(key="{}_rememberpastwindows".format(sname),value="_{}".format(os.environ['step4crememberpastwindows']))rememberpastwindows=os.environ['step4crememberpastwindows']else:ti.xcom_push(key="{}_rememberpastwindows".format(sname),value="_{}".format(default_args['rememberpastwindows']))patternwindowthreshold=default_args['patternwindowthreshold']if'step4cpatternwindowthreshold'inos.environ:ti.xcom_push(key="{}_patternwindowthreshold".format(sname),value="_{}".format(os.environ['step4cpatternwindowthreshold']))patternwindowthreshold=os.environ['step4cpatternwindowthreshold']else:ti.xcom_push(key="{}_patternwindowthreshold".format(sname),value="_{}".format(default_args['patternwindowthreshold']))rtmsscorethreshold=default_args['rtmsscorethreshold']if'step4crtmsscorethreshold'inos.environ:ti.xcom_push(key="{}_rtmsscorethreshold".format(sname),value="_{}".format(os.environ['step4crtmsscorethreshold']))rtmsscorethreshold=os.environ['step4crtmsscorethreshold']else:ti.xcom_push(key="{}_rtmsscorethreshold".format(sname),value="_{}".format(default_args['rtmsscorethreshold']))attackscorethreshold=default_args['attackscorethreshold']if'step4cattackscorethreshold'inos.environ:ti.xcom_push(key="{}_attackscorethreshold".format(sname),value="_{}".format(os.environ['step4cattackscorethreshold']))attackscorethreshold=os.environ['step4cattackscorethreshold']else:ti.xcom_push(key="{}_attackscorethreshold".format(sname),value="_{}".format(default_args['attackscorethreshold']))patternscorethreshold=default_args['patternscorethreshold']if'step4cpatternscorethreshold'inos.environ:ti.xcom_push(key="{}_patternscorethreshold".format(sname),value="_{}".format(os.environ['step4cpatternscorethreshold']))patternscorethreshold=os.environ['step4cpatternscorethreshold']else:ti.xcom_push(key="{}_patternscorethreshold".format(sname),value="_{}".format(default_args['patternscorethreshold']))rtmsfoldername=default_args['rtmsfoldername']if'step4crtmsfoldername'inos.environ:ti.xcom_push(key="{}_rtmsfoldername".format(sname),value="{}".format(os.environ['step4crtmsfoldername']))rtmsfoldername=os.environ['step4crtmsfoldername']else:ti.xcom_push(key="{}_rtmsfoldername".format(sname),value="{}".format(default_args['rtmsfoldername']))os.environ["step4crtmsfoldername"]=rtmsfoldernametry:f=open("/tmux/rtmsfoldername.txt","w")f.write(rtmsfoldername)f.close()exceptExceptionase:passrepo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))if'step4crtmsmaxwindows'inos.environ:rtmsmaxwindows=os.environ['step4crtmsmaxwindows']default_args['rtmsmaxwindows']=rtmsmaxwindowselse:rtmsmaxwindows=default_args['rtmsmaxwindows']ti.xcom_push(key="{}_rtmsmaxwindows".format(sname),value="_{}".format(rtmsmaxwindows))try:f=open("/tmux/rtmsmax.txt","w")f.write(rtmsmaxwindows)f.close()exceptExceptionase:passwn=windowname('preprocess3',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-preprocess3","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}{}\"{}\"{}{}\"{}\"\"{}\"{}{}{}\"{}\"{}\"{}\"{}".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],maxrows,searchterms,rememberpastwindows,patternwindowthreshold,raw_data_topic,rtmsstream,rtmsscorethreshold,attackscorethreshold,patternscorethreshold,localsearchtermfolder,localsearchtermfolderinterval,rtmsfoldername,rtmsmaxwindows),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()try:tsslogging.tsslogit("Preprocessing3 DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")exceptExceptionase:#git push -f origin mainos.chdir("/{}".format(repo))subprocess.call("git push -f origin main",shell=True)VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]maxrows=sys.argv[5]default_args['maxrows']=maxrowssubprocess.Popen("/tmux/rtmstrunc.sh",shell=True)searchterms=sys.argv[6]default_args['searchterms']=searchtermsrememberpastwindows=sys.argv[7]default_args['rememberpastwindows']=rememberpastwindowspatternwindowthreshold=sys.argv[8]default_args['patternwindowthreshold']=patternwindowthresholdrawdatatopic=sys.argv[9]default_args['raw_data_topic']=rawdatatopicrtmsstream=sys.argv[10]default_args['rtmsstream']=rtmsstreamrtmsscorethreshold=sys.argv[11]default_args['rtmsscorethreshold']=rtmsscorethresholdattackscorethreshold=sys.argv[12]default_args['attackscorethreshold']=attackscorethresholdpatternscorethreshold=sys.argv[13]default_args['patternscorethreshold']=patternscorethresholdlocalsearchtermfolder=sys.argv[14]default_args['localsearchtermfolder']=localsearchtermfolderlocalsearchtermfolderinterval=sys.argv[15]default_args['localsearchtermfolderinterval']=localsearchtermfolderintervalrtmsfoldername=sys.argv[16]default_args['rtmsfoldername']=rtmsfoldernamertmsmaxwindows=sys.argv[17]default_args['rtmsmaxwindows']=rtmsmaxwindowstsslogging.locallogs("INFO","STEP 4c: Preprocessing 3 started")try:shutil.rmtree("/rawdata/{}".format(rtmsfoldername),ignore_errors=True)exceptExceptionase:passtry:directory="/rawdata/{}".format(rtmsfoldername)ifnotos.path.exists(directory):os.makedirs(directory)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 4c: Cannot make directory /rawdata/{} in {}{}".format(rtmsfoldername,os.path.basename(__file__),e))startdirread()whileTrue:try:processtransactiondata()time.sleep(1)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 4c: Preprocessing3 DAG in {}{}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Preprocessing3 DAG in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")break
Another powerful feature of TML is performing machine learning at the entity level. See TML Performs Entity Level Machine Learning and Processing for refresher. For example, if TML is processing real-time data from 1 million IoT devices, it can create 1 million individual machine learnig models for each device. TML uses the following ML algorithms:
Note
All ML data are also written to “/rawdata/ml” folder in the container.
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimportmaadstmlimporttssloggingimportosimportsubprocessimporttimeimportrandomsys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'myname':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< *** leave blank'producerid':'iotsolution',# <<< *** Change as needed'preprocess_data_topic':'iot-preprocess',# << *** topic/data to use for training datasets - You created this in STEP 2'ml_data_topic':'ml-data',# topic to store the trained algorithms - You created this in STEP 2'identifier':'TML solution',# <<< *** Change as needed'companyname':'Your company',# <<< *** Change as needed'myemail':'Your email',# <<< *** Change as needed'mylocation':'Your location',# <<< *** Change as needed'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'deploy':'1',# <<< *** do not modofy'modelruns':'100',# <<< *** Change as needed'offset':'-1',# <<< *** Do not modify'islogistic':'1',# <<< *** Change as needed, 1=logistic, 0=not logistic'networktimeout':'600',# <<< *** Change as needed'modelsearchtuner':'90',# <<< *This parameter will attempt to fine tune the model search space - A number close to 100 means you will have fewer models but their predictive quality will be higher.'dependentvariable':'failure',# <<< *** Change as needed,'independentvariables':'Power_preprocessed_AnomProb',# <<< *** Change as needed,'rollbackoffsets':'1000',# <<< *** Change as needed,'consumeridtrainingdata2':'',# leave blank'partition_training':'',# leave blank'consumefrom':'',# leave blank'topicid':'-1',# leave as is'fullpathtotrainingdata':'/Viper-ml/viperlogs/iotlogistic',# # <<< *** Change as needed - add name for foldername that stores the training datasets'processlogic':'classification_name=failure_prob:Power_preprocessed_AnomProb=55,n',# <<< *** Change as needed, i.e. classification_name=failure_prob:Voltage_preprocessed_AnomProb=55,n:Current_preprocessed_AnomProb=55,n'array':'0',# leave as is'transformtype':'',# Sets the model to: log-lin,lin-log,log-log'sendcoefto':'',# you can send coefficients to another topic for further processing -- MUST BE SET IN STEP 2'coeftoprocess':'',# indicate the index of the coefficients to process i.e. 0,1,2 For example, for a 3 estimated parameters 0=constant, 1,2 are the other estmated paramters'coefsubtopicnames':'',# Give the coefficients a name: constant,elasticity,elasticity2'viperconfigfile':'/Viper-ml/viper.env',# Do not modify'HPDEADDR':'http://'}######################################## DO NOT MODIFY BELOW ############################################## This sets the lat/longs for the IoT devices so it can be mapVIPERTOKEN=""VIPERHOST=""VIPERPORT=""HPDEHOST=''HPDEPORT=''HTTPADDR=""maintopic=default_args['preprocess_data_topic']mainproducerid=default_args['producerid']defperformSupervisedMachineLearning():viperconfigfile=default_args['viperconfigfile']# Set personal datacompanyname=default_args['companyname']myname=default_args['myname']myemail=default_args['myemail']mylocation=default_args['mylocation']# Enable SSL/TLS communication with Kafkaenabletls=int(default_args['enabletls'])# If brokerhost is empty then this function will use the brokerhost address in your# VIPER.ENV in the field 'KAFKA_CONNECT_BOOTSTRAP_SERVERS'brokerhost=default_args['brokerhost']# If this is -999 then this function uses the port address for Kafka in VIPER.ENV in the# field 'KAFKA_CONNECT_BOOTSTRAP_SERVERS'brokerport=int(default_args['brokerport'])# If you are using a reverse proxy to reach VIPER then you can put it here - otherwise if# empty then no reverse proxy is being usedmicroserviceid=default_args['microserviceid']############################################################################################################## VIPER CALLS HPDE TO PERFORM REAL_TIME MACHINE LEARNING ON TRAINING DATA# deploy the algorithm to ./deploy folder - otherwise it will be in ./models folderdeploy=int(default_args['deploy'])# number of models runs to find the best algorithmmodelruns=int(default_args['modelruns'])# Go to the last offset of the partition in partition_training variableoffset=int(default_args['offset'])# If 0, this is not a logistic model where dependent variable is discreetislogistic=int(default_args['islogistic'])# set network timeout for communication between VIPER and HPDE in seconds# increase this number if you timeoutnetworktimeout=int(default_args['networktimeout'])# This parameter will attempt to fine tune the model search space - a number close to 0 means you will have lots of# models but their quality may be low. A number close to 100 means you will have fewer models but their predictive# quality will be higher.modelsearchtuner=int(default_args['modelsearchtuner'])#this is the dependent variabledependentvariable=default_args['dependentvariable']# Assign the independentvariable streamsindependentvariables=default_args['independentvariables']#"Voltage_preprocessed_AnomProb,Current_preprocessed_AnomProb"rollbackoffsets=int(default_args['rollbackoffsets'])consumeridtrainingdata2=default_args['consumeridtrainingdata2']partition_training=default_args['partition_training']producerid=default_args['producerid']consumefrom=default_args['consumefrom']topicid=int(default_args['topicid'])fullpathtotrainingdata=default_args['fullpathtotrainingdata']# These are the conditions that sets the dependent variable to a 1 - if condition not met it will be 0processlogic=default_args['processlogic']#'classification_name=failure_prob:Voltage_preprocessed_AnomProb=55,n:Current_preprocessed_AnomProb=55,n'identifier=default_args['identifier']producetotopic=default_args['ml_data_topic']array=int(default_args['array'])transformtype=default_args['transformtype']# Sets the model to: log-lin,lin-log,log-logsendcoefto=default_args['sendcoefto']# you can send coefficients to another topic for further processingcoeftoprocess=default_args['coeftoprocess']# indicate the index of the coefficients to process i.e. 0,1,2coefsubtopicnames=default_args['coefsubtopicnames']# Give the coefficients a name: constant,elasticity,elasticity2# Call HPDE to train the modelresult=maadstml.viperhpdetraining(VIPERTOKEN,VIPERHOST,VIPERPORT,consumefrom,producetotopic,companyname,consumeridtrainingdata2,producerid,HPDEHOST,viperconfigfile,enabletls,partition_training,deploy,modelruns,modelsearchtuner,HPDEPORT,offset,islogistic,brokerhost,brokerport,networktimeout,microserviceid,topicid,maintopic,independentvariables,dependentvariable,rollbackoffsets,fullpathtotrainingdata,processlogic,identifier)defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefstartml(**context):sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTML".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTML".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))HPDEADDR=default_args['HPDEADDR']HPDEHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEHOST".format(sname))HPDEPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEPORT".format(sname))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))ti=context['task_instance']ti.xcom_push(key="{}_preprocess_data_topic".format(sname),value=default_args['preprocess_data_topic'])ti.xcom_push(key="{}_ml_data_topic".format(sname),value=default_args['ml_data_topic'])ti.xcom_push(key="{}_modelruns".format(sname),value="_{}".format(default_args['modelruns']))ti.xcom_push(key="{}_offset".format(sname),value="_{}".format(default_args['offset']))ti.xcom_push(key="{}_islogistic".format(sname),value="_{}".format(default_args['islogistic']))ti.xcom_push(key="{}_networktimeout".format(sname),value="_{}".format(default_args['networktimeout']))ti.xcom_push(key="{}_modelsearchtuner".format(sname),value="_{}".format(default_args['modelsearchtuner']))ti.xcom_push(key="{}_dependentvariable".format(sname),value=default_args['dependentvariable'])ti.xcom_push(key="{}_independentvariables".format(sname),value=default_args['independentvariables'])rollback=default_args['rollbackoffsets']if'step5rollbackoffsets'inos.environ:ti.xcom_push(key="{}_rollbackoffsets".format(sname),value="_{}".format(os.environ['step5rollbackoffsets']))rollback=os.environ['step5rollbackoffsets']else:ti.xcom_push(key="{}_rollbackoffsets".format(sname),value="_{}".format(default_args['rollbackoffsets']))processlogic=default_args['processlogic']if'step5processlogic'inos.environ:ti.xcom_push(key="{}_processlogic".format(sname),value="{}".format(os.environ['step5processlogic']))processlogic=os.environ['step5processlogic']else:ti.xcom_push(key="{}_processlogic".format(sname),value="{}".format(default_args['processlogic']))independentvariables=default_args['independentvariables']if'step5independentvariables'inos.environ:ti.xcom_push(key="{}_independentvariables".format(sname),value="{}".format(os.environ['step5independentvariables']))independentvariables=os.environ['step5independentvariables']else:ti.xcom_push(key="{}_independentvariables".format(sname),value="{}".format(default_args['independentvariables']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_consumefrom".format(sname),value=default_args['consumefrom'])ti.xcom_push(key="{}_fullpathtotrainingdata".format(sname),value=default_args['fullpathtotrainingdata'])ti.xcom_push(key="{}_transformtype".format(sname),value=default_args['transformtype'])ti.xcom_push(key="{}_sendcoefto".format(sname),value=default_args['sendcoefto'])ti.xcom_push(key="{}_coeftoprocess".format(sname),value=default_args['coeftoprocess'])ti.xcom_push(key="{}_coefsubtopicnames".format(sname),value=default_args['coefsubtopicnames'])ti.xcom_push(key="{}_HPDEADDR".format(sname),value=HPDEADDR)repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('ml',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-ml","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}{}{}{}{}\"{}\"\"{}\"".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],HPDEADDR,HPDEHOST,HPDEPORT[1:],rollback,processlogic,independentvariables),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()try:tsslogging.tsslogit("Machine Learning DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")exceptExceptionase:#git push -f origin mainos.chdir("/{}".format(repo))subprocess.call("git push -f origin main",shell=True)VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]HPDEHOST=sys.argv[5]HPDEPORT=sys.argv[6]rollbackoffsets=sys.argv[7]default_args['rollbackoffsets']=rollbackoffsetsprocesslogic=sys.argv[8]default_args['processlogic']=processlogicindependentvariables=sys.argv[9]default_args['independentvariables']=independentvariablessubprocess.run("rm -rf {}".format(default_args['fullpathtotrainingdata']),shell=True)tsslogging.locallogs("INFO","STEP 5: Machine learning started")whileTrue:try:performSupervisedMachineLearning()# time.sleep(10)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 5: Machine Learning DAG in {}{}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Machine Learning DAG in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")break
Entity based machine learning is a core function of TML. This section discusses some of key defaul_args in the tml-system-step-5-kafka-machine-learning-dag. These are as follows.
Important
TML generates training algorithms and stores them on disk in the ./models or ./deploy folder, and in the Kafka topic specified in the
ml_data_topic default_args json key. TML accesses these trained algorithms, for predictions, automatically for each entity specified by topicid.
Everything is managed by the TML binary: Viper (see 1. TML Components: Three Binaries)
TML manages the topicid, which represents individual entities in MariaDB. Note, a topicid is uniquely associated with a primary identifier for the device
or entity like its Device Serial Number (DSN). So as data streams from all devices, there must be a json key that indicates a DSN from these devices. TML
binary Viper, aggregates data for each DSN and process the data for each device in every sliding time window.
TML generates trained algorithms for each sliding time window. This means, as new real-time data is captured in the sliding time windows, TML re-runs
algorithms for this sliding time window to see if there is a better algorithm using the MAPE measure.
- If the MAPE in the previous sliding time window is
higher than the MAPE on the next windows, the older algorithm will be used in the next window, otherwise TML overwrites the older algorithm with the newer,
better, algorithm. NOTE: TML is generating brand new algorithms for sliding windows, it is NOT simply updating the estimated parameters for ONE algorithm, as
is common in convetional approaches.
All algorithm are Json serialized files that are less than 1K in size. This makes it very efficient to store millions of algorithms on disk without consuming
much storage.
All training and predictions happen in parallel using different instances of the Viper binary.
You should refer to Preprocessed Variable Naming Standard to properly specify the names of the processed variables: Voltage and Current If Voltage and Current are processed
with anomaly probability processing type (i.e. AnomProb), then the new processed variables for Voltage and Current will be named:
Voltage_preprocessed_AnomProb
Current_preprocessed_AnomProb
Similarly, if processing any variable, this naming standard will apply.
For example, lets breakdown the following rule for prepcoccesed variables Voltage and Current - this rule would be the value of the processlogic field in Dag 5 above:
NOTE: Separate multiple rules by a colon (:). The colon acts as an “AND”. Specifically, if Voltage_preprocessed_AnomProb AND Current_preprocessed_AnomProb both satisfy
their rules, then failure_prob is set to 1, otherwise, 0.
Variable/Rule
Upper Bound
Lower Bound
Explanation
classification_name
n/a
n/a
This simply tells TML that
this is a classification model
failure_prob
n/a
n/a
This is simply the name for
your generated classified variable.
You can put any name you want.
Voltage_preprocessed_AnomProb=55,n
n
55
This sets the rule for the
Voltage_preprocessed_AnomProb
and sets the failure_prob
to 1 IF the values of the variable
Voltage_preprocessed_AnomProb are
between 55 and n, where n
signifies no upper bound.
If rule was
Voltage_preprocessed_AnomProb=55,95,
then failure_prob will
be 1, if it is between 55 and 95,
inclusive.
Current_preprocessed_AnomProb=55,n
n
55
This sets the rule for the
Current_preprocessed_AnomProb
and sets the failure_prob
to 1 IF the values of the variable
Current_preprocessed_AnomProb
are between 55 and n, where n
signifies no upper bound.
If rule was
Current_preprocessed_AnomProb=55,95,
then failure_prob will
be 1, if it is between 55 and 95,
inclusive.
Important
The 1 and 0’s are then compared between the variables to see if they match. For example, if
Voltage_preprocessed_AnomProb AND Current_preprocessed_AnomProb both are 1, then the failure_prob
variable is 1, otherwise 0.
Tip
If Current_preprocessed_AnomProb=-n,55, then this rule is if Current_preprocessed_AnomProb is less then 55, then set failure_prob to 1, otherwise 0.
Both -n and n indicate that the variable has NO lower bound or upper bound, respectively. If you want a specific lower and upper bound, just replace -n, and n with exact
numbers.
8.5.12.4. Machine Learning Trained Model Sample JSON Output
Below is the JSON output after TML binary: HPDE has performed machine learning using the eal-time data streams.
8.5.13. TML Physical Location of Machine Learning Models
All entity level machine learning models are stored in the container folder specified in fullpathtotrainingdata in Step 5.
Important
Step 6 task uses the trained models in this folder for entity level predictions.
Therefore, in Step 6 below, the pathtoalgos must be the same as fullpathtotrainingdata in Step 5.
There are 5 file outputs from STEP 5 stored in the folder fullpathtotrainingdata. For example, for Entity 53 associated wth DSN:AC000W020485383 here are the output files:
8.5.14.1. How TML Optimizes ML Models and Acheives High Forecast Accuracy
TML uses the binaries Viper and HPDE to optimize ML models for high forecast accuracy. All ML models estimated by Viper and HPDE are applied to data in each sliding time window.
Below describes how TML (Viper/HPDE) optimizes ML models for each sliding time window:
TML processes each sliding time window which can be expanded to increase the model training data sets for ML models
More training data allows TML to learn the patterns effectively, BUT because TML does ALL of this processing IN-MEMORY having too large of a training dataset will slow down TML processing/ML
TML applies several different algorithms to the streaming data:
Algorithm
Description
Logistic Regression
Performs classification regression and predicts probabilities
Linear Regression
Performs linear regression using OLS algorithm
Gradient Boosting
Gradient boosting for non-linear real-time data
Ridge Regression
Ridge Regression for non-linear real-time data
Neural networks
Neural networks non-linear real-time data
TML performs real-time data normalization: All data are put on the same scale, between 0-1 – this prevents large variables (with large numbers) from dominating small variables (with small numbers, like decimals)
TML performs real-time hyper parameter tuning in the algorithms in 2 above. This is IMPORTANT to ensure algorithms are properly calibrated for the best prediction accuracy (algorithm MAPE)
TML performs constant machine learning of the streamed data by constantly trying different algorithms for EVERY sliding time window. This is how TML is able to learn highly complex, NON-LINEAR, data in real-Time. So if the underlying pattern changes in the subsequent sliding time windows, these new patterns will be learned by TML immediately.
8.5.15. STEP 6: Entity Based Predictions: tml-system-step-6-kafka-predictions-dag
Tip
Watch the YouTube video to see how this dag is configured. YouTube Video
Note
All Prediction data are also written to “/rawdata/ml” folder in the container.
importmaadstmlfromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimporttssloggingimportosimportsubprocessimportrandomimporttimesys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'myname':'Sebastian Maurice',# <<< *** Change as needed'enabletls':'1',# <<< *** 1=connection is encrypted, 0=no encryption'microserviceid':'',# <<< *** leave blank'producerid':'iotsolution',# <<< *** Change as needed'preprocess_data_topic':'iot-preprocess',# << *** data for the independent variables - You created this in STEP 2'ml_prediction_topic':'iot-ml-prediction-results-output',# topic to store the predictions - You created this in STEP 2'description':'TML solution',# <<< *** Change as needed'companyname':'Otics',# <<< *** Change as needed'myemail':'Your email',# <<< *** Change as needed'mylocation':'Your location',# <<< *** Change as needed'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'streamstojoin':'Power_preprocessed_AnomProb',# << ** These are the streams in the preprocess_data_topic for these independent variables'inputdata':'',# << ** You can specify independent variables manually - rather than consuming from the preprocess_data_topic stream'consumefrom':'ml-data',# << This is ml_data_topic in STEP 5 that contains the estimated parameters'mainalgokey':'',# leave blank'offset':'-1',# << ** input data will start from the end of the preprocess_data_topic and rollback maxrows'delay':'60',# << network delay parameter'usedeploy':'1',# << 1=use algorithms in ./deploy folder, 0=use ./models folder'networktimeout':'6000',# << additional network parameter'maxrows':'50',# << ** the number of offsets to rollback - For example, if 50, you will get 50 predictions continuously'produceridhyperprediction':'',# << leave blank'consumeridtraininedparams':'',# << leave blank'groupid':'',# << leave blank'topicid':'-1',# << leave as is'pathtoalgos':'/Viper-ml/viperlogs/iotlogistic',# << this is specified in fullpathtotrainingdata in STEP 5'array':'0',# 0=do not save as array, 1=save as array'HPDEADDR':'http://'# Do not modify}######################################## DO NOT MODIFY BELOW #############################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HPDEHOSTPREDICT=''HPDEPORTPREDICT=''HTTPADDR=""# that is a change 2# Set Global variable for Viper confifuration file - change the folder path for your computerviperconfigfile="/Viper-predict/viper.env"mainproducerid=default_args['producerid']maintopic=default_args['preprocess_data_topic']predictiontopic=default_args['ml_prediction_topic']defperformPrediction():# Set personal datacompanyname=default_args['companyname']myname=default_args['myname']myemail=default_args['myemail']mylocation=default_args['mylocation']# Enable SSL/TLS communication with Kafkaenabletls=int(default_args['enabletls'])# If brokerhost is empty then this function will use the brokerhost address in your# VIPER.ENV in the field 'KAFKA_CONNECT_BOOTSTRAP_SERVERS'brokerhost=default_args['brokerhost']# If this is -999 then this function uses the port address for Kafka in VIPER.ENV in the# field 'KAFKA_CONNECT_BOOTSTRAP_SERVERS'brokerport=int(default_args['brokerport'])# If you are using a reverse proxy to reach VIPER then you can put it here - otherwise if# empty then no reverse proxy is being usedmicroserviceid=default_args['microserviceid']description=default_args['description']# Note these are the same streams or independent variables that are in the machine learning python filestreamstojoin=default_args['streamstojoin']#"Voltage_preprocessed_AnomProb,Current_preprocessed_AnomProb"############################################################################################################## START HYPER-PREDICTIONS FROM ESTIMATED PARAMETERS# Use the topic created from function viperproducetotopicstream for new data for# independent variablesinputdata=default_args['inputdata']# Consume from holds the algorithmsconsumefrom=default_args['consumefrom']#"iot-trained-params-input"# if you know the algorithm key put it here - this will speed up the predictionmainalgokey=default_args['mainalgokey']# Offset=-1 means go to the last offset of hpdetraining_partitionoffset=int(default_args['offset'])#-1# wait 60 seconds for Kafka - if exceeded then VIPER will backoutdelay=int(default_args['delay'])# use the deployed algorithm - must exist in ./deploy folderusedeploy=int(default_args['usedeploy'])# Network timeoutnetworktimeout=int(default_args['networktimeout'])# maxrows - this is percentage to rollback streamif'step6maxrows'inos.environ:maxrows=int(os.environ['step6maxrows'])else:maxrows=int(default_args['maxrows'])#Start predicting with new data streamsproduceridhyperprediction=default_args['produceridhyperprediction']consumeridtraininedparams=default_args['consumeridtraininedparams']groupid=default_args['groupid']topicid=int(default_args['topicid'])# -1 to predict for current topicids in the stream# Path where the trained algorithms are stored in the machine learning python filepathtoalgos=default_args['pathtoalgos']#'/Viper-tml/viperlogs/iotlogistic'array=int(default_args['array'])ml_prediction_topic=default_args['ml_prediction_topic']result6=maadstml.viperhpdepredict(VIPERTOKEN,VIPERHOST,VIPERPORT,consumefrom,ml_prediction_topic,companyname,consumeridtraininedparams,produceridhyperprediction,HPDEHOSTPREDICT,inputdata,maxrows,mainalgokey,-1,offset,enabletls,delay,HPDEPORTPREDICT,brokerhost,brokerport,networktimeout,usedeploy,microserviceid,topicid,maintopic,streamstojoin,array,pathtoalgos)defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefstartpredictions(**context):sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREDICT".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREDICT".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))HPDEADDR=default_args['HPDEADDR']HPDEHOSTPREDICT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEHOSTPREDICT".format(sname))HPDEPORTPREDICT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEPORTPREDICT".format(sname))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))ti=context['task_instance']ti.xcom_push(key="{}_preprocess_data_topic".format(sname),value=default_args['preprocess_data_topic'])ti.xcom_push(key="{}_ml_prediction_topic".format(sname),value=default_args['ml_prediction_topic'])ti.xcom_push(key="{}_streamstojoin".format(sname),value=default_args['streamstojoin'])ti.xcom_push(key="{}_inputdata".format(sname),value=default_args['inputdata'])ti.xcom_push(key="{}_consumefrom".format(sname),value=default_args['consumefrom'])ti.xcom_push(key="{}_offset".format(sname),value="_{}".format(default_args['offset']))ti.xcom_push(key="{}_delay".format(sname),value="_{}".format(default_args['delay']))ti.xcom_push(key="{}_usedeploy".format(sname),value="_{}".format(default_args['usedeploy']))ti.xcom_push(key="{}_networktimeout".format(sname),value="_{}".format(default_args['networktimeout']))maxrows=default_args['maxrows']if'step6maxrows'inos.environ:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(os.environ['step6maxrows']))maxrows=os.environ['step6maxrows']else:ti.xcom_push(key="{}_maxrows".format(sname),value="_{}".format(default_args['maxrows']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_pathtoalgos".format(sname),value=default_args['pathtoalgos'])ti.xcom_push(key="{}_HPDEADDR".format(sname),value=HPDEADDR)repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('predict',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-predict","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}{}{}{}{}".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],HPDEADDR,HPDEHOSTPREDICT,HPDEPORTPREDICT[1:],maxrows),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()try:tsslogging.tsslogit("Predictions DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")exceptExceptionase:#git push -f origin mainos.chdir("/{}".format(repo))subprocess.call("git push -f origin main",shell=True)VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]HPDEHOSTPREDICT=sys.argv[5]HPDEPORTPREDICT=sys.argv[6]maxrows=sys.argv[7]default_args['maxrows']=maxrowstsslogging.locallogs("INFO","STEP 6: Predictions started")whileTrue:try:performPrediction()time.sleep(1)exceptExceptionase:tsslogging.locallogs("ERROR","STEP 6: Predictions DAG in {}{}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Predictions DAG in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")break
Here are the core parameters in the above dag 6:
Step 6 DAG parameter
Explanation
preprocess_data_topic
This is the topic that contain the data
for the independent variables. Note: this
is NOT different from conventional BATCH machine
learning, where you
train a model on batch data, and then you use
new values for the independent variables
for prediction of the dependent variable.
In the real-time case,
we are streaming values for the
independent variables contained in this topic.
ml_prediction_topic
This topic will contain the predictions.
The predictions can then be used for
visualization in STEP 7.
description
You can provide a description for your
solution here.
streamstojoin
This is where you specify the independent
variables for your predctions. Specifically,
if you are preprocessing, the “new”
preprocessed variables will be
given a standard naming convention -
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportsysimportsubprocessimporttssloggingimportosimporttimeimportrandomsys.dont_write_bytecode=True######################################## USER CHOOSEN PARAMETERS ########################################default_args={'topic':'iot-preprocess,iot-preprocess2',# <<< *** Separate multiple topics by a comma - Viperviz will stream data from these topics to your browser'dashboardhtml':'dashboard.html',# <<< *** name of your dashboard file: This one is ONLY for preprocessing'dashboardhtml-ml':'dashboard-ml.html',# <<< *** This one is IF you include ML dag'topic-ml':'iot-preprocess,iot-preprocess2',# <<< *** Separate multiple topics by a comma'dashboardhtml-ai':'dashboard-ai.html',# <<< *** This one is you include AI dag'topic-ai':'iot-preprocess,iot-preprocess2',# <<< *** Separate multiple topics by a comma'dashboardhtml-ml-ai':'dashboard-ml-ai.html',# <<< *** This one is you include ML-AI dag'topic-ml-ai':'iot-preprocess,iot-preprocess2',# <<< *** Separate multiple topics by a comma'secure':'1',# <<< *** 1=connection is encrypted, 0=no encryption'offset':'-1',# <<< *** -1 indicates to read from the last offset always'append':'0',# << ** Do not append new data in the browser'rollbackoffset':'400',# *************** Rollback the data stream by rollbackoffset. For example, if 500, then Viperviz wll grab all of the data from the last offset - 500}######################################## DO NOT MODIFY BELOW #############################################defwindowname(wtype,vipervizport,sname,dagname):randomNumber=random.randrange(10,9999)wn="viperviz-{}-{}-{}={}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/vipervizwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{},{}\n".format(wn,vipervizport))returnwndefstartstreamingengine(**context):repo=tsslogging.getrepo()tsslogging.locallogs("INFO","STEP 7: Visualization started")try:tsslogging.tsslogit("Visualization DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")exceptExceptionase:#git push -f origin mainos.chdir("/{}".format(repo))subprocess.call("git push -f origin main",shell=True)sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))vipervizport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERVIZPORT".format(sname))solutionvipervizport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_SOLUTIONVIPERVIZPORT".format(sname))tss=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_TSS".format(sname))if'_ml_ai_'insd:topic=default_args['topic-ml-ai']dashboardhtml=default_args['dashboardhtml-ml-ai']elif'_ai_'insd:topic=default_args['topic-ai']dashboardhtml=default_args['dashboardhtml-ai']elif'_ml_'insd:topic=default_args['topic-ml']dashboardhtml=default_args['dashboardhtml-ml']else:topic=default_args['topic']dashboardhtml=default_args['dashboardhtml']secure=default_args['secure']offset=default_args['offset']append=default_args['append']rollbackoffset=default_args['rollbackoffset']ti=context['task_instance']ti.xcom_push(key="{}_topic".format(sname),value="{}".format(topic))ti.xcom_push(key="{}_dashboardhtml".format(sname),value="{}".format(dashboardhtml))ti.xcom_push(key="{}_secure".format(sname),value="_{}".format(secure))ti.xcom_push(key="{}_offset".format(sname),value="_{}".format(offset))ti.xcom_push(key="{}_append".format(sname),value="_{}".format(append))ti.xcom_push(key="{}_chip".format(sname),value=chip)ti.xcom_push(key="{}_rollbackoffset".format(sname),value="_{}".format(rollbackoffset))# start the viperviz on Vipervizport# STEP 5: START Visualization Vipervizvizgood=0foriinrange(5):wn=windowname('visual',vipervizport,sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viperviz","ENTER"])mainport=0iftss[1:]=="1":subprocess.run(["tmux","send-keys","-t","{}".format(wn),"/Viperviz/viperviz-linux-{} 0.0.0.0 {}".format(chip,vipervizport[1:]),"ENTER"])mainport=int(vipervizport[1:])else:subprocess.run(["tmux","send-keys","-t","{}".format(wn),"/Viperviz/viperviz-linux-{} 0.0.0.0 {}".format(chip,solutionvipervizport[1:]),"ENTER"])mainport=int(solutionvipervizport[1:])time.sleep(5)iftsslogging.testvizconnection(mainport)==1:tsslogging.locallogs("INFO","STEP 7: /Viperviz/viperviz-linux-{} 0.0.0.0 {}".format(chip,mainport))vizgood=1breakelse:ifi<4:subprocess.call(["tmux","kill-window","-t","{}".format(wn)])subprocess.call(["kill","-9","$(lsof -i:{} -t)".format(mainport)])tsslogging.locallogs("WARN","STEP 7: Cannot make a connection to Viperviz on port {}. Going to try again...".format(mainport))ifvizgood==0:tsslogging.locallogs("ERROR","STEP 7: Network issue. Cannot make a connection to Viperviz on port {}".format(mainport))
you can specify different topics for the appropriate
solution. So, topic-ml-ai, is for any solution template
that is AI related or has “_ml_ai_” in the solution name.
dashboardhtml
This dashboard will use the topics in the topic field.
dashboardhtml-ml
This dashboard will use the topics in the topic-ml field.
dashboardhtml-ai
This dashboard will use the topics in the topic-ai field.
dashboardhtml-ml-ai
This is dashboard will use the topics in the topic-ml-ai field.
secure
If set to 1, then connection is
TLS secure, if 0 it is not.
vipervizport
This is the port you want the Viperviz
binary to listen on. For example, if 9005,
Viperviz will listen on Port 9005
offset
Indicate where in the stream to consume from.
If -1, latest data is consumed.
append
If 0, data will not accumulate in your
dashboard, if 1 it will accumulate.
chip
Viperviz can run on Windows/Mac/Linux.
Use ‘amd64’ for Windows/Linux,
use ‘arm64’ for Mac/Linux
rollbackoffset
This indicates the number of offsets to
rollack from the latest (or end of the stream).
If 500, then Viperviz wll grab all of the
data from the last
offset - 500
8.7.1. STEP 8: Deploy TML Solution to Docker : tml-system-step-8-deploy-solution-to-docker-dag
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportosimportsubprocessimporttssloggingimportgitimporttimeimportsyssys.dont_write_bytecode=True############################################################### DO NOT MODIFY BELOW ####################################################defdoparse(fname,farr):data=''withopen(fname,'r',encoding='utf-8')asfile:data=file.readlines()r=0fordindata:forfinfarr:fs=f.split(";")iffs[0]ind:data[r]=d.replace(fs[0],fs[1])r+=1withopen(fname,'w',encoding='utf-8')asfile:file.writelines(data)defdockerit(**context):if'tssbuild'inos.environ:ifos.environ['tssbuild']=="1":returntry:sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))repo=tsslogging.getrepo()tsslogging.tsslogit("Docker DAG in {}".format(os.path.basename(__file__)),"INFO")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")chip=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))cname=os.environ['DOCKERUSERNAME']+"/{}-{}".format(sname,chip)print("Containername=",cname)tsslogging.locallogs("INFO","STEP 8: Starting docker push for: {}".format(cname))ifos.environ['TSS']=="1":try:f=open("/tmux/cname.txt","w")f.write(cname)f.close()exceptExceptionase:passti=context['task_instance']ti.xcom_push(key="{}_containername".format(sname),value=cname)ti.xcom_push(key="{}_solution_dag_to_trigger".format(sname),value=sd)scid=tsslogging.getrepo('/tmux/cidname.txt')cid=scid# cid addedkey="trigger-{}".format(sname)os.environ[key]=sdifos.environ['TSS']=="1"andlen(cid)>1:print("[INFO] docker commit {}{}".format(cid,cname))subprocess.call("docker rmi -f $(docker images --filter 'dangling=true' -q --no-trunc)",shell=True)cbuf="docker commit {}{}".format(cid,cname)v=subprocess.call("docker commit {}{}".format(cid,cname),shell=True)status=tsslogging.optimizecontainer(cname,sname,sd)ifstatus=="":tsslogging.locallogs("WARN","STEP 8: There seems to be an issue optimizing the container. Here is the commit command: {} - message={}. Container may NOT pushed.".format(cbuf,v))else:tsslogging.locallogs("INFO","STEP 8: Docker Container created and optimized. Will push it now. Here is the commit command: {} - message={}".format(cbuf,v))#v=subprocess.call("docker push {}".format(cname), shell=True)proc=subprocess.Popen("docker push {}".format(cname),shell=True)time.sleep(3)proc.terminate()proc.wait()eliflen(cid)<=1:tsslogging.locallogs("ERROR","STEP 8: There seems to be an issue with docker commit. Here is the command: docker commit {}{}".format(cid,cname))tsslogging.tsslogit("Deploying to Docker in {}".format(os.path.basename(__file__)),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")os.environ['tssbuild']="1"doparse("/{}/tml-airflow/dags/tml-solutions/{}/docker_run_stop-{}.py".format(repo,pname,pname),["--solution-name--;{}".format(sname)])doparse("/{}/tml-airflow/dags/tml-solutions/{}/docker_run_stop-{}.py".format(repo,pname,pname),["--solution-dag--;{}".format(sd)])exceptExceptionase:print("[ERROR] Step 8: ",e)tsslogging.locallogs("ERROR","STEP 8: Deploying to Docker in {}: {}".format(os.path.basename(__file__),e))tsslogging.tsslogit("Deploying to Docker in {}: {}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")
8.7.2. STEP 9: PrivateGPT and Qdrant Integration: tml-system-step-9-privategpt_qdrant-dag
Tip
Watch the YouTube video to learn how to configure the key paramaters in the Step 9 dag.
Also, it would be advised to pull the PrivateGPT containers before running this step 9.
fromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportosimporttssloggingimportsysimporttimeimportmaadstmlimportsubprocessimportrandomimportjsonimportthreadingimportrefrombinaryornot.checkimportis_binarydocidstrarr=[]sys.dont_write_bytecode=True######################################################USER CHOSEN PARAMETERS ###########################################################default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'pgptcontainername':'maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-v2',#'maadsdocker/tml-privategpt-no-gpu-amd64', # enter a valid container https://hub.docker.com/r/maadsdocker/tml-privategpt-no-gpu-amd64'rollbackoffset':'5',# <<< *** Change as needed'offset':'-1',# leave as is'enabletls':'1',# change as needed'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'microserviceid':'',# change as needed'topicid':'-999',# leave as is'delay':'100',# change as needed'companyname':'otics',# <<< *** Change as needed'consumerid':'streamtopic',# <<< *** Leave as is'consumefrom':'cisco-network-preprocess',# <<< *** Change as needed'pgpt_data_topic':'cisco-network-privategpt','producerid':'private-gpt',# <<< *** Leave as is'identifier':'This is analysing TML output with privategpt','pgpthost':'http://127.0.0.1',# PrivateGPT container listening on this host'pgptport':'8001',# PrivateGPT listening on this port'preprocesstype':'',# Leave as is'partition':'-1',# Leave as is'prompt':'[INST] Are there any errors in the logs? Give s detailed response including IP addresses and host machines.[/INST]',# Enter your prompt here'context':'This is network data from inbound and outbound packets. The data are \ anomaly probabilities for cyber threats from analysis of inbound and outbound packets. If inbound or outbound \ anomaly probabilities are less than 0.60, it is likely the risk of a cyber attack is also low. If its above 0.60, then risk is mid to high.',# what is this data about? Provide context to PrivateGPT'jsonkeytogather':'hyperprediction',# enter key you want to gather data from to analyse with PrivateGpt i.e. Identifier or hyperprediction'keyattribute':'inboundpackets,outboundpackets',# change as needed'keyprocesstype':'anomprob',# change as needed'hyperbatch':'0',# Set to 1 if you want to batch all of the hyperpredictions and sent to chatgpt, set to 0, if you want to send it one by one'vectordbcollectionname':'tml-llm-model-v2',# change as needed'concurrency':'2',# change as needed Leave at 1'CUDA_VISIBLE_DEVICES':'0',# change as needed'docfolder':'mylogs,mylogs2',# You can specify the sub-folder that contains TEXT or PDF files..this is a subfolder in the MAIN folder mapped to /rawdata# if this field in NON-EMPTY, privateGPT will query these documents as the CONTEXT to answer your prompt# separate multiple folders with a comma'docfolderingestinterval':'900',# how often you want TML to RE-LOAD the files in docfolder - enter the number of SECONDS, if 0 they are read ONCE'useidentifierinprompt':'1',# If 1, this uses the identifier in the TML json output and appends it to prompt, If 0, it uses the prompt only'searchterms':'192.168.--identifier--,authentication failure','temperature':'0.1',# This value ranges between 0 and 1, it controls how conservative LLM model will be, if 0 very very, if 1 it will hallucinate'vectorsearchtype':'Manhattan',# this is for the Qdrant Search algorithm. it can be: Cosine, Euclid, Dot, or Manhattan'streamall':'1','contextwindowsize':'8192',# Size of the context window. This controls the number of tokens to process by LLM model'vectordimension':'768','mitrejson':'/rawdata/mitre.json'}############################################################### DO NOT MODIFY BELOW ####################################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""maintopic=default_args['consumefrom']mainproducerid=default_args['producerid']GPTONLINE=0defcheckresponse(response,ident):globalGPTONLINEst="false"if"ERROR:"inresponse:returnresponse,st,""GPTONLINE=1response=response.replace("null","-1").replace("\\n","").replace("\n","")r1=json.loads(response)c1=r1['choices'][0]['message']['content']c1=c1.replace('"','\\"').replace("'","\'").replace("\\n"," ").replace("&","and")c1=re.sub(' +',' ',c1)if'='inc1and('Answer:'inc1or'A:'inc1):r1['choices'][0]['message']['content']="The analysis of the document(s) did not find a proper result."response=json.dumps(r1)returnresponse,st,c1.strip()ifdefault_args['searchterms']!='':starr=default_args['searchterms'].split(",")fortinstarr:if'--identifier--'int:t=t.replace("--identifier--",ident)iftinc1:st="true"breakreturnresponse,st,c1.strip()defstopcontainers():pgptcontainername=default_args['pgptcontainername']cfound=0subprocess.call("docker image ls > gptfiles.txt",shell=True)withopen('gptfiles.txt','r',encoding='utf-8')asfile:data=file.readlines()r=0fordindata:darr=d.split(" ")if'-privategpt-'indarr[0]:buf="docker stop $(docker ps -q --filter ancestor={} )".format(darr[0])ifpgptcontainernameindarr[0]:cfound=1print(buf)subprocess.call(buf,shell=True)ifcfound==0:print("INFO STEP 9: PrivateGPT container {} not found. It may need to be pulled.".format(pgptcontainername))tsslogging.locallogs("WARN","STEP 9: PrivateGPT container not found. It may need to be pulled if it does not start: docker pull {}".format(pgptcontainername))defllmattrs(pgptcontainername):if'-deepseek-medium'inpgptcontainername:return"DeepSeek-R1-Distill-Llama-8B-Q5_K_M.gguf","BAAI/bge-base-en-v1.5"elifpgptcontainername=='maadsdocker/tml-privategpt-with-gpu-nvidia-amd64':return"TheBloke/Mistral-7B-Instruct-v0.1-GGUF","BAAI/bge-small-en-v1.5"elif'maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-v2'==pgptcontainername:return"mistralai/Mistral-7B-Instruct-v0.2","BAAI/bge-small-en-v1.5"elif'maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-v3'==pgptcontainername:return"mistralai/Mistral-7B-Instruct-v0.3","BAAI/bge-base-en-v1.5"elif'maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-v3-large'==pgptcontainername:return"mistralai/Mistral-7B-Instruct-v0.3","BAAI/bge-m3"return"",""defstartpgptcontainer():print("Starting PGPT container: {}".format(default_args['pgptcontainername']))collection=default_args['vectordbcollectionname']concurrency=default_args['concurrency']pgptcontainername=default_args['pgptcontainername']pgptport=int(default_args['pgptport'])cuda=int(default_args['CUDA_VISIBLE_DEVICES'])temp=default_args['temperature']vectorsearchtype=default_args['vectorsearchtype']cw=default_args['contextwindowsize']vectordimension=default_args['vectordimension']stopcontainers()time.sleep(10)if'-no-gpu-'inpgptcontainername:buf="docker run -d -p {}:{} --net=host --env PORT={} --env GPU=0 --env COLLECTION={} --env WEB_CONCURRENCY={} --env CUDA_VISIBLE_DEVICES={} --env temperature={} --env vectorsearchtype=\"{}\"{}".format(pgptport,pgptport,pgptport,collection,concurrency,cuda,temperature,vectorsearchtype,pgptcontainername)else:mainmodel,mainembedding=llmattrs(pgptcontainername)ifos.environ['TSS']=="1":buf="docker run -d -p {}:{} --net=host --gpus all -v /var/run/docker.sock:/var/run/docker.sock:z --env PORT={} --env TSS=1 --env GPU=1 --env COLLECTION={} --env WEB_CONCURRENCY={} --env CUDA_VISIBLE_DEVICES={} --env TOKENIZERS_PARALLELISM=false --env temperature={} --env vectorsearchtype=\"{}\" --env contextwindowsize={} --env vectordimension={} --env mainmodel=\"{}\" --env mainembedding=\"{}\"{}".format(pgptport,pgptport,pgptport,collection,concurrency,cuda,temperature,vectorsearchtype,cw,vectordimension,mainmodel,mainembedding,pgptcontainername)else:buf="docker run -d -p {}:{} --net=host --gpus all -v /var/run/docker.sock:/var/run/docker.sock:z --env PORT={} --env TSS=0 --env GPU=1 --env COLLECTION={} --env WEB_CONCURRENCY={} --env CUDA_VISIBLE_DEVICES={} --env TOKENIZERS_PARALLELISM=false --env temperature={} --env vectorsearchtype=\"{}\" --env contextwindowsize={} --env vectordimension={} --env mainmodel=\"{}\" --env mainembedding=\"{}\"{}".format(pgptport,pgptport,pgptport,collection,concurrency,cuda,temperature,vectorsearchtype,cw,vectordimension,mainmodel,mainembedding,pgptcontainername)v=subprocess.call(buf,shell=True)print("INFO STEP 9: PrivateGPT container. Here is the run command: {}, v={}".format(buf,v))tsslogging.locallogs("INFO","STEP 9: PrivateGPT container. Here is the run command: {}, v={}".format(buf,v))returnv,buf,mainmodel,mainembeddingdefqdrantcontainer():v=0buf=""buf="docker stop $(docker ps -q --filter ancestor=qdrant/qdrant )"subprocess.call(buf,shell=True)time.sleep(4)ifos.environ['TSS']=="1":buf="docker run -d -p 6333:6333 -v $(pwd)/qdrant_storage:/qdrant/storage:z qdrant/qdrant"else:buf="docker run -d --network=bridge -v /var/run/docker.sock:/var/run/docker.sock:z -p 6333:6333 -v $(pwd)/qdrant_storage:/qdrant/storage:z qdrant/qdrant"v=subprocess.call(buf,shell=True)print("INFO STEP 9: Qdrant container. Here is the run command: {}, v={}".format(buf,v))tsslogging.locallogs("INFO","STEP 9: Qdrant container. Here is the run command: {}, v={}".format(buf,v))returnv,bufdefpgptchat(prompt,context,docfilter,port,includesources,ip,endpoint):prompt=prompt.replace("&","and")print("Pgptchat=",prompt)response=maadstml.pgptchat(prompt,context,docfilter,port,includesources,ip,endpoint)returnresponsedefproducegpttokafka(value,maintopic):inputbuf=valuetopicid=int(default_args['topicid'])producerid=default_args['producerid']identifier=default_args['identifier']# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=default_args['delay']enabletls=default_args['enabletls']try:result=maadstml.viperproducetotopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,producerid,enabletls,delay,'','','',0,inputbuf,'',topicid,identifier)print(result)exceptExceptionase:print("ERROR:",e)defconsumetopicdata():maintopic=default_args['consumefrom']rollbackoffsets=int(default_args['rollbackoffset'])enabletls=int(default_args['enabletls'])consumerid=default_args['consumerid']companyname=default_args['companyname']offset=int(default_args['offset'])brokerhost=default_args['brokerhost']brokerport=int(default_args['brokerport'])microserviceid=default_args['microserviceid']topicid=default_args['topicid']preprocesstype=default_args['preprocesstype']delay=int(default_args['delay'])partition=int(default_args['partition'])result=maadstml.viperconsumefromtopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,consumerid,companyname,partition,enabletls,delay,offset,brokerhost,brokerport,microserviceid,topicid,rollbackoffsets,preprocesstype)returnresultdefwritetortmslogfile(fname,jsonbuf):print("fname=",fname)print("jsonbuf=",jsonbuf)try:f=open(fname,"w")f.write(jsonbuf+"\n")f.close()exceptExceptionase:passdefgetsearchtext(res,context,prompt):privategptmessage=[]messages=""mainmessages=""cw=int(default_args['contextwindowsize'])forrinres['StreamTopicDetails']['TopicReads']:fname=r['Filename']messages=""fordinr['SearchTextFound']:messages=messages+str(d[15:].strip())+". "iflen(messages)>cw:messages=messages[0:cw-1]breakmainmessages="{}. Here are the messages: {}. {}".format(context,messages,prompt)privategptmessage.append([mainmessages,"SearchTextFound",fname,json.dumps(r)])returnprivategptmessagedefgatherdataforprivategpt(result):privategptmessage=[]if'step9prompt'inos.environ:ifos.environ['step9prompt']!='':prompt=os.environ['step9prompt']prompt=prompt.replace("&","and")default_args['prompt']=promptelse:prompt=default_args['prompt']prompt=prompt.replace("&","and")else:prompt=default_args['prompt']prompt=prompt.replace("&","and")if'step9context'inos.environ:ifos.environ['step9context']!='':context=os.environ['step9context']context=context.replace("&","and")default_args['context']=contextelse:context=default_args['context']context=context.replace("&","and")else:context=default_args['context']context=context.replace("&","and")jsonkeytogather=default_args['jsonkeytogather']ifdefault_args['docfolder']!='':context=''ifdefault_args['useidentifierinprompt']=="1":jsonkeytogather="Identifier"if'step9keyattribute'inos.environ:ifos.environ['step9keyattribute']!='':attribute=os.environ['step9keyattribute']default_args['keyattribute']=attributeelse:attribute=default_args['keyattribute']else:attribute=default_args['keyattribute']if'step9keyprocesstype'inos.environ:ifos.environ['step9keyprocesstype']!='':processtype=os.environ['step9keyprocesstype']default_args['keyprocesstype']=processtypeelse:processtype=default_args['keyprocesstype']else:processtype=default_args['keyprocesstype']if'step9hyperbatch'inos.environ:ifos.environ['step9hyperbatch']!='':hyperbatch=os.environ['step9hyperbatch']default_args['hyperbatch']=hyperbatchelse:hyperbatch=default_args['hyperbatch']else:hyperbatch=default_args['hyperbatch']try:res=json.loads(result,strict='False')exceptExceptionase:print("Error=",e)tsslogging.tsslogit("PrivateGPT DAG jsonkeytogather is empty in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")returnmessage=""found=0ifjsonkeytogather=='':tsslogging.tsslogit("PrivateGPT DAG jsonkeytogather is empty in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")returnifjsonkeytogather.lower()=="searchtextfound":privategptmessage=getsearchtext(res,context,prompt)returnprivategptmessageforrinres['StreamTopicDetails']['TopicReads']:ifjsonkeytogather=='Identifier'orjsonkeytogather=='identifier':identarr=r['Identifier'].split("~")try:attribute=attribute.lower()aar=attribute.split(",")isin=any(xinr['Identifier'].lower()forxinaar)ifisin:found=0fordinr['RawData']:found=1message=message+str(d)+', 'iffound:ifcontext!='':message="{}. Data: {}. {}".format(context,message,prompt)elif'--identifier--'inprompt:prompt2=prompt.replace('--identifier--',identarr[0])message="{}".format(prompt2)else:message="{}".format(prompt)privategptmessage.append([message,identarr[0]])message=""exceptExcepptionase:tsslogging.tsslogit("PrivateGPT DAG in {}{}".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")else:isin1=Falseisin2=Falsefound=0message=""identarr=r['Identifier'].split("~")ifprocesstype!=''andattribute!='':processtype=processtype.lower()ptypearr=processtype.split(",")isin1=any(xinr['Preprocesstype'].lower()forxinptypearr)attribute=attribute.lower()aar=attribute.split(",")isin2=any(xinr['Identifier'].lower()forxinaar)ifisin1andisin2:buf=r[jsonkeytogather]ifbuf!='':found=1message=message+"{} (Identifier={})".format(buf,identarr[0])+', 'elifprocesstype!=''andattribute=='':processtype=processtype.lower()ptypearr=processtype.split(",")isin1=any(xinr['Preprocesstype'].lower()forxinptypearr)ifisin1:buf=r[jsonkeytogather]ifbuf!='':found=1message=message+"{} (Identifier={})".format(buf,identarr[0])+', 'elifprocesstype==''andattribute!='':attribute=attribute.lower()aar=attribute.split(",")isin2=any(xinr['Identifier'].lower()forxinaar)ifisin2:buf=r[jsonkeytogather]ifbuf!='':found=1message=message+"{} (Identifier={})".format(buf,identarr[0])+', 'else:buf=r[jsonkeytogather]ifbuf!='':found=1message=message+"{} (Identifier={})".format(buf,identarr[0])+', 'iffoundandhyperbatch=="0":if'--identifier--'inprompt:prompt2=prompt.replace('--identifier--',identarr[0])message="{}. Data: {}. {}".format(context,message,prompt2)else:message="{}. Data: {}. {}".format(context,message,prompt)privategptmessage.append([message,identarr[0]])ifjsonkeytogather!='Identifier'andfoundandhyperbatch=="1":message="{}. Data: {}. {}".format(context,message,prompt)privategptmessage.append(message)returnprivategptmessagedefstartdirread():globalGPTONLINEprint("INFO startdirread")try:t=threading.Thread(name='child procs',target=ingestfiles)t.start()exceptExceptionase:print(e)defdeleteembeddings(docids):pgptendpoint="/v1/ingest/"pgptip=default_args['pgpthost']pgptport=default_args['pgptport']maadstml.pgptdeleteembeddings(docids,pgptip,pgptport,pgptendpoint)defgetingested(docname):pgptendpoint="/v1/ingest/list"pgptip=default_args['pgpthost']pgptport=default_args['pgptport']docids,docstr,docidsstr=maadstml.pgptgetingestedembeddings(docname,pgptip,pgptport,pgptendpoint)returndocids,docstr,docidsstrdefingestfiles():globaldocidstrarr,GPTONLINEpgptendpoint="/v1/ingest"docidstrarr=[]basefolder='/rawdata/'pgptip=default_args['pgpthost']pgptport=default_args['pgptport']buf=default_args['docfolder']bufarr=buf.split(",")whileTrue:ifGPTONLINE:docidstrarr=[]fordirpinbufarr:# lock the directorydirp=basefolder+dirpifos.path.exists(dirp):withtsslogging.LockDirectory(dirp)aslock:newfd=os.dup(lock.dir_fd)files=[os.path.join(dirp,f)forfinos.listdir(dirp)ifos.path.isfile(os.path.join(dirp,f))]formfinfiles:docids,docstr,docidstr=getingested(mf)deleteembeddings(docids)print("INFO Ingestfiles:",mf)ifis_binary(mf):maadstml.pgptingestdocs(mf,'binary',pgptip,pgptport,pgptendpoint)else:try:maadstml.pgptingestdocs(mf,'text',pgptip,pgptport,pgptendpoint)exceptExceptionase:print("ERROR:",e)docids,docstr,docidstr=getingested(mf)iflen(docidstr)>=1:docidstrarr.append(docidstr[0])else:print("WARN Directory Path: {} does not exist".format(dirp))ifint(default_args['docfolderingestinterval'])==0:breaktime.sleep(int(default_args['docfolderingestinterval']))print("docidsstr=",docidstrarr)time.sleep(1)defsendtoprivategpt(maindata,docfolder):globaldocidstrarrcounter=0maxc=300pgptendpoint="/v1/completions"prompt=default_args['prompt']prompt=prompt.replace("&","and")context=default_args['context']context=context.replace("&","and")mcontext=Falseusingqdrant=''ifdocfolder!='':mcontext=Trueusingqdrant='Using documents in Qdrant VectorDB for context.'maintopic=default_args['pgpt_data_topic']ifos.environ['TSS']=="1":mainip=default_args['pgpthost']else:mainip="http://"+os.environ['qip']ifos.environ['qip']=="":mainip=default_args['pgpthost']mainport=default_args['pgptport']if'step9keyattribute'inos.environ:ifos.environ['step9keyattribute']!='':attribute=os.environ['step9keyattribute']default_args['keyattribute']=attributeelse:attribute=default_args['keyattribute']else:attribute=default_args['keyattribute']if'step9hyperbatch'inos.environ:ifos.environ['step9hyperbatch']!='':hyperbatch=os.environ['step9hyperbatch']default_args['hyperbatch']=hyperbatchelse:hyperbatch=default_args['hyperbatch']else:hyperbatch=default_args['hyperbatch']formessinmaindata:ifdefault_args['jsonkeytogather']=='Identifier'orhyperbatch=="0"ordefault_args['jsonkeytogather'].lower()=="searchtextfound":m=mess[0]m1=mess[1]else:m=messm1=attribute#default_args['keyattribute']m=m.replace("&","and")response=pgptchat(m,mcontext,docidstrarr,mainport,False,mainip,pgptendpoint)response=response.strip()# Produce data to Kafkasf="false"response,sf,contentmessage=checkresponse(response,m1)tactic,technique,jbm=tsslogging.getmitre(response,default_args['mitrejson'])ifusingqdrant!='':ifdefault_args['streamall']=="0":# Only stream if search terms found in responseifsf=="false":response="ERROR:"m=m+' ('+usingqdrant+')'if'ERROR:'notinresponseandcontentmessage!="":ifdefault_args['jsonkeytogather'].lower()=="searchtextfound":jmess=mess[3]response1=jmess[:-1]+",\"privateGPT_AI_response\":\""+contentmessage.strip().rstrip().lstrip()+ \
"\","+"\"prompt\":\""+prompt+"\",\"context\":\""+context+ \
"\",\"pgptcontainer\":\""+default_args['pgptcontainername']+"\",\"pgpt_consumefrom\":\""+ \
default_args['consumefrom']+"\", \"pgpt_data_topic\":\""+default_args['pgpt_data_topic']+ \
"\",\"contextwindowsize\":"+default_args['contextwindowsize']+",\"temperature\":\""+default_args['temperature']+ \
"\",\"pgptrollbackoffset\":"+default_args['rollbackoffset']+jbm+"}"writetortmslogfile(mess[2],response1)else:response1=response[:-1]+","+"\"prompt\":\""+m.strip()+"\",\"identifier\":\""+m1.strip()+"\",\"searchfound\":\""+sf.strip()+"\"}"response1=response1.replace(";",":")producegpttokafka(response1,maintopic)else:counter+=1time.sleep(1)ifcounter>maxc:startpgptcontainer()qdrantcontainer()counter=0tsslogging.tsslogit("PrivateGPT Step 9 DAG PrivateGPT Container restarting in {}{}".format(os.path.basename(__file__),response),"WARN")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")defwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwndefstartprivategpt(**context):sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))if'step9rollbackoffset'inos.environ:ifos.environ['step9rollbackoffset']!='':default_args['rollbackoffset']=os.environ['step9rollbackoffset']if'step9prompt'inos.environ:ifos.environ['step9prompt']!='':default_args['prompt']=os.environ['step9prompt']if'step9context'inos.environ:ifos.environ['step9context']!='':default_args['context']=os.environ['step9context']if'step9contextwindowsize'inos.environ:ifos.environ['step9contextwindowsize']!='':default_args['contextwindowsize']=os.environ['step9contextwindowsize']if'step9pgptcontainername'inos.environ:ifos.environ['step9pgptcontainername']!='':default_args['pgptcontainername']=os.environ['step9pgptcontainername']if'step9keyattribute'inos.environ:ifos.environ['step9keyattribute']!='':default_args['keyattribute']=os.environ['step9keyattribute']if'step9keyprocesstype'inos.environ:ifos.environ['step9keyprocesstype']!='':default_args['keyprocesstype']=os.environ['step9keyprocesstype']if'step9hyperbatch'inos.environ:ifos.environ['step9hyperbatch']!='':default_args['hyperbatch']=os.environ['step9hyperbatch']if'step9vectordbcollectionname'inos.environ:ifos.environ['step9vectordbcollectionname']!='':default_args['vectordbcollectionname']=os.environ['step9vectordbcollectionname']if'step9concurrency'inos.environ:ifos.environ['step9concurrency']!='':default_args['concurrency']=os.environ['step9concurrency']if'CUDA_VISIBLE_DEVICES'inos.environ:ifos.environ['CUDA_VISIBLE_DEVICES']!='':default_args['CUDA_VISIBLE_DEVICES']=os.environ['CUDA_VISIBLE_DEVICES']if'step9docfolder'inos.environ:ifos.environ['step9docfolder']!='':default_args['docfolder']=os.environ['step9docfolder']if'step9docfolderingestinterval'inos.environ:ifos.environ['step9docfolderingestinterval']!='':default_args['docfolderingestinterval']=os.environ['step9docfolderingestinterval']if'step9useidentifierinprompt'inos.environ:ifos.environ['step9useidentifierinprompt']!='':default_args['useidentifierinprompt']=os.environ['step9useidentifierinprompt']if'step9searchterms'inos.environ:ifos.environ['step9searchterms']!='':default_args['searchterms']=os.environ['step9searchterms']if'step9temperature'inos.environ:ifos.environ['step9temperature']!='':default_args['temperature']=os.environ['step9temperature']if'step9vectorsearchtype'inos.environ:ifos.environ['step9vectorsearchtype']!='':default_args['vectorsearchtype']=os.environ['step9vectorsearchtype']if'step9pgpthost'inos.environ:ifos.environ['step9pgpthost']!='':default_args['pgpthost']=os.environ['step9pgpthost']if'step9pgptport'inos.environ:ifos.environ['step9pgptport']!='':default_args['pgptport']=os.environ['step9pgptport']if'step9vectordimension'inos.environ:ifos.environ['step9vectordimension']!='':default_args['vectordimension']=os.environ['step9vectordimension']VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESSPGPT".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESSPGPT".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))ti=context['task_instance']ti.xcom_push(key="{}_consumefrom".format(sname),value=default_args['consumefrom'])ti.xcom_push(key="{}_pgpt_data_topic".format(sname),value=default_args['pgpt_data_topic'])ti.xcom_push(key="{}_pgptcontainername".format(sname),value=default_args['pgptcontainername'])ti.xcom_push(key="{}_offset".format(sname),value="_{}".format(default_args['offset']))ti.xcom_push(key="{}_rollbackoffset".format(sname),value="_{}".format(default_args['rollbackoffset']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_enabletls".format(sname),value="_{}".format(default_args['enabletls']))ti.xcom_push(key="{}_partition".format(sname),value="_{}".format(default_args['partition']))ti.xcom_push(key="{}_prompt".format(sname),value=default_args['prompt'])ti.xcom_push(key="{}_context".format(sname),value=default_args['context'])ti.xcom_push(key="{}_jsonkeytogather".format(sname),value=default_args['jsonkeytogather'])ti.xcom_push(key="{}_keyattribute".format(sname),value=default_args['keyattribute'])ti.xcom_push(key="{}_keyprocesstype".format(sname),value=default_args['keyprocesstype'])ti.xcom_push(key="{}_vectordbcollectionname".format(sname),value=default_args['vectordbcollectionname'])ti.xcom_push(key="{}_concurrency".format(sname),value="_{}".format(default_args['concurrency']))ti.xcom_push(key="{}_cuda".format(sname),value="_{}".format(default_args['CUDA_VISIBLE_DEVICES']))ti.xcom_push(key="{}_pgpthost".format(sname),value=default_args['pgpthost'])ti.xcom_push(key="{}_pgptport".format(sname),value="_{}".format(default_args['pgptport']))ti.xcom_push(key="{}_hyperbatch".format(sname),value="_{}".format(default_args['hyperbatch']))ti.xcom_push(key="{}_docfolder".format(sname),value="{}".format(default_args['docfolder']))ti.xcom_push(key="{}_docfolderingestinterval".format(sname),value="_{}".format(default_args['docfolderingestinterval']))ti.xcom_push(key="{}_useidentifierinprompt".format(sname),value="_{}".format(default_args['useidentifierinprompt']))ti.xcom_push(key="{}_searchterms".format(sname),value="{}".format(default_args['searchterms']))ti.xcom_push(key="{}_streamall".format(sname),value="_{}".format(default_args['streamall']))ti.xcom_push(key="{}_temperature".format(sname),value="_{}".format(default_args['temperature']))ti.xcom_push(key="{}_vectorsearchtype".format(sname),value="{}".format(default_args['vectorsearchtype']))ti.xcom_push(key="{}_contextwindowsize".format(sname),value="_{}".format(default_args['contextwindowsize']))ti.xcom_push(key="{}_vectordimension".format(sname),value="_{}".format(default_args['vectordimension']))ti.xcom_push(key="{}_mitrejson".format(sname),value="{}".format(default_args['mitrejson']))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))mainmodel,mainembedding=llmattrs(default_args['pgptcontainername'])ti.xcom_push(key="{}_mainmodel".format(sname),value="{}".format(mainmodel))ti.xcom_push(key="{}_mainembedding".format(sname),value="{}".format(mainembedding))wn=windowname('ai',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-preprocess-pgpt","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"{}{}{}{}\"{}\"\"{}\"{}{}".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],default_args['vectordbcollectionname'],default_args['concurrency'],default_args['CUDA_VISIBLE_DEVICES'],default_args['rollbackoffset'],default_args['prompt'],default_args['context'],default_args['keyattribute'],default_args['keyprocesstype'],default_args['hyperbatch'],default_args['docfolder'],default_args['docfolderingestinterval'],default_args['useidentifierinprompt'],default_args['searchterms'],default_args['streamall'],default_args['temperature'],default_args['vectorsearchtype'],default_args['contextwindowsize'],default_args['pgptcontainername'],default_args['pgpthost'],default_args['pgptport'],default_args['vectordimension']),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]vectordbcollectionname=sys.argv[5]concurrency=sys.argv[6]cuda=sys.argv[7]rollbackoffset=sys.argv[8]prompt=sys.argv[9]context=sys.argv[10]keyattribute=sys.argv[11]keyprocesstype=sys.argv[12]hyperbatch=sys.argv[13]docfolder=sys.argv[14]docfolderingestinterval=sys.argv[15]useidentifierinprompt=sys.argv[16]searchterms=sys.argv[17]streamall=sys.argv[18]temperature=sys.argv[19]vectorsearchtype=sys.argv[20]contextwindowsize=sys.argv[21]pgptcontainername=sys.argv[22]pgpthost=sys.argv[23]pgptport=sys.argv[24]vectordimension=sys.argv[25]default_args['vectordimension']=vectordimensiondefault_args['rollbackoffset']=rollbackoffsetdefault_args['prompt']=promptdefault_args['context']=contextdefault_args['keyattribute']=keyattributedefault_args['keyprocesstype']=keyprocesstypedefault_args['hyperbatch']=hyperbatchdefault_args['vectordbcollectionname']=vectordbcollectionnamedefault_args['concurrency']=concurrencydefault_args['CUDA_VISIBLE_DEVICES']=cudadefault_args['docfolder']=docfolderdefault_args['docfolderingestinterval']=docfolderingestintervaldefault_args['useidentifierinprompt']=useidentifierinpromptdefault_args['searchterms']=searchtermsdefault_args['streamall']=streamalldefault_args['temperature']=temperaturedefault_args['vectorsearchtype']=vectorsearchtypedefault_args['contextwindowsize']=contextwindowsizedefault_args['pgptcontainername']=pgptcontainernamedefault_args['pgpthost']=pgpthostdefault_args['pgptport']=pgptportif"KUBE"notinos.environ:v,buf=qdrantcontainer()ifbuf!="":ifv==1:tsslogging.locallogs("WARN","STEP 9: There seems to be an issue starting the Qdrant container. Here is the run command - try to run it nanually for testing: {}".format(buf))else:tsslogging.locallogs("INFO","STEP 9: Success starting Qdrant. Here is the run command: {}".format(buf))time.sleep(5)# wait for containers to starttsslogging.locallogs("INFO","STEP 9: Starting privateGPT")v,buf,mainmodel,mainembedding=startpgptcontainer()ifv==1:tsslogging.locallogs("WARN","STEP 9: There seems to be an issue starting the privateGPT container. Here is the run command - try to run it nanually for testing: {}".format(buf))else:tsslogging.locallogs("INFO","STEP 9: Success starting privateGPT. Here is the run command: {}".format(buf))time.sleep(10)# wait for containers to starttsslogging.getqip()elifos.environ["KUBE"]=="0":v,buf=qdrantcontainer()ifbuf!="":ifv==1:tsslogging.locallogs("WARN","STEP 9: There seems to be an issue starting the Qdrant container. Here is the run command - try to run it nanually for testing: {}".format(buf))else:tsslogging.locallogs("INFO","STEP 9: Success starting Qdrant. Here is the run command: {}".format(buf))time.sleep(5)# wait for containers to starttsslogging.locallogs("INFO","STEP 9: Starting privateGPT")v,buf,mainmodel,mainembedding=startpgptcontainer()ifv==1:tsslogging.locallogs("WARN","STEP 9: There seems to be an issue starting the privateGPT container. Here is the run command - try to run it nanually for testing: {}".format(buf))else:tsslogging.locallogs("INFO","STEP 9: Success starting privateGPT. Here is the run command: {}".format(buf))time.sleep(10)# wait for containers to starttsslogging.getqip()else:tsslogging.locallogs("INFO","STEP 9: [KUBERNETES] Starting privateGPT - LOOKS LIKE THIS IS RUNNING IN KUBERNETES")tsslogging.locallogs("INFO","STEP 9: [KUBERNETES] Make sure you have applied the private GPT YAML files and have the privateGPT Pod running")ifdocfolder!='':startdirread()count=0whileTrue:try:# Get preprocessed data from Kafkaresult=consumetopicdata()# print("Result=",result)ifresult!=""andresultisnotNone:# Format the preprocessed data for PrivateGPTmaindata=gatherdataforprivategpt(result)# Send the data to PrivateGPT and produce to Kafkaiflen(maindata)>0:sendtoprivategpt(maindata,docfolder)# time.sleep(2)count=0exceptExceptionase:print("Error=",e)tsslogging.locallogs("ERROR","STEP 9: PrivateGPT Step 9 DAG in {}{} Aborting after 10 consecutive errors.".format(os.path.basename(__file__),e))tsslogging.tsslogit("PrivateGPT Step 9 DAG in {}{} Aborting after 10 consecutive errors.".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")time.sleep(5)count=count+1ifcount>10:break
It is important to note the format of this JSON as follows.
hyperprediction - all TML output is stored in this variable. This could be the name of the value of jsonkeytogather. The Step 9 DAG, will gather all the data from this key and ask privateGPT the question in your prompt.
Identifier - Additional details are put in this key. Specifically, the data used in the analysis is stored in the RawData JSON array, that can also be gathered and presented to privateGPT for prompting.
Now,
keyattribute is the variable you are processing. This is seen in the “Topic”: “topicid155_Voltage_preprocessed_Avg”, here TML is taking Average of voltage from the devices. Clearly, you can specify any name for key attribute you are processing.
keyprocesstype is the type of processing you are doing, as listed in Preprocessing Types. This is seen in the “Preprocesstype”: “Avg”,, here TML is taking Average of voltage from the devices. Clearly, you can specify any name for key processing type from the processing types table.
Tip
You can separate multiple keyattribute, and keyprocesstype with a comma.
This way of using processed data with privateGPT for further analysis, offers a tremendously powerful way to leverage GenAI technology with real-time data streams at no cost: since all API calls are done to the privateGPT container that is running locally. Also, no data are sent outside your environment, this further makes this solution very secure giving you 100% data control.
8.11. Using Qdrant VectorDB for Local Document Analysis
8.12. TML, PrivateGPT and Qdrant Example Scenarios
You can map local folders to the /rawdata folder and store your files (TEXT or PDF) as subfolders.
For example: docfolder=’mylog1,mylog2’, these two folders would be subfolders in the local folder mapped to /rawdata
The contents of these folders would be ingested into Qdrant Vector DB
These folder will automatically rel-loaded every docfolderingestinterval seconds.
For example, if you want to analyse log files, then if docfolderingestinterval=60, these folders will be ingested every 60 seconds
If useidentifierinprompt is 1, then TML will add the Identifier as part of the prompt. For example, if you are analysing IP addresses
for anomalies, and compute an anomaly score, you can further complement this score by looking in to log files, to see if this IP address has
authentication failures, which may indicate this IP address is a HACKING attempt.
You can even add a placeholder for identifier in the prompt by adding --identifier--. For example, prompt=Does the following
**--identifier-- have any errors in the logs?** TML will replace --identifier-- is the real-time IP address or value in the Identifier JSON
field.
This way, you can use TML, privateGPT and Qdrant for powerful analysis of documents, by cross-referencing and meshing information together to get greater real-time insights from your real-time data.
This DAG implements multi-agentic AI to real-time data processing. Take a look at ref:TML and Agentic AI for more information.
fromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetime,timezonefromairflow.decoratorsimportdag,taskfromlanggraph_supervisorimportcreate_supervisorfromllama_index.core.indices.vector_store.baseimportVectorStoreIndexfromllama_index.core.schemaimportDocument# Document is often found herefromlanggraph.prebuiltimportcreate_react_agentfromllama_index.embeddings.ollamaimportOllamaEmbeddingfromlangchain_ollamaimportChatOllamaimportimportlibimportjsonimportpprintfromllama_index.core.settingsimportSettingsfromdatetimeimportdatetime,timezoneimportosimporttssloggingimportsysimporttimeimportmaadstmlimportsubprocessimportrandomimportjsonimportthreadingimportrefrombinaryornot.checkimportis_binaryimportbase64importrequestsfromjson_repairimportrepair_jsonsys.dont_write_bytecode=True######################################################USER CHOSEN PARAMETERS ###########################################################SMTP_SERVER=''SMTP_PORT=0SMTP_USERNAME=''SMTP_PASSWORD=''# this should be base64 encodedrecipient=''if'SMTP_SERVER'inos.environ:SMTP_SERVER=os.environ['SMTP_SERVER']if'SMTP_PORT'inos.environ:SMTP_PORT=int(os.environ['SMTP_PORT'])if'SMTP_USERNAME'inos.environ:SMTP_USERNAME=os.environ['SMTP_USERNAME']if'SMTP_PASSWORD'inos.environ:SMTP_PASSWORD=os.environ['SMTP_PASSWORD']SMTP_PASSWORD=base64.b64decode(SMTP_PASSWORD)SMTP_PASSWORD=SMTP_PASSWORD.decode('utf-8')if'recipient'inos.environ:recipient=os.environ['recipient']default_args={'owner':'Sebastian Maurice',# <<< *** Change as needed'ollamacontainername':'maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-llama3-tools',#'maadsdocker/tml-privategpt-no-gpu-amd64', # enter a valid container https://hub.docker.com/r/maadsdocker/tml-privategpt-no-gpu-amd64'rollbackoffset':'5',# <<< *** Change as needed'offset':'-1',# leave as is'enabletls':'1',# change as needed'brokerhost':'',# <<< *** Leave as is'brokerport':'-999',# <<< *** Leave as is'microserviceid':'',# change as needed'topicid':'-999',# leave as is'delay':'100',# change as needed'companyname':'otics',# <<< *** Change as needed'consumerid':'streamtopic',# <<< *** Leave as is'agenttopic':'',# this topic contains the individual agent responses'agents_topic_prompt':""" <consumefrom - topic agent will monitor:prompt you want for the agent to answer->>consumefrom - topic2 agent will monitor<<-prompt you want for the agent to answer> """,# <topic agent will monitor:prompt you want for the agent>, separate multiple topic agents with ->>'teamlead_topic':'',# Enter the team lead topic - all team lead responses will be written to this topic'teamleadprompt':""" Enter the prompt for the Team lead agent """,# Enter the team lead prompt'supervisor_topic':'',# Enter the supervisor topic - all supervisor responses will be written to this topic'supervisorprompt':'',# Enter the supervisor prompt'agenttoolfunctions':""" tool_function:agent_name:system_prompt;tool_function2:agent_name2:sysemt_prompt2;.... """,# enter the tools : tool_function is the name of the funtions in the agenttools python file'agent_team_supervisor_topic':'',# this topic will hold the responses from agents, team lead and supervisor'producerid':'agentic-ai',# <<< *** Leave as is'identifier':'This is analysing TML output with Agentic AI','mainip':'http://127.0.0.1',# Ollama server container listening on this host'mainport':'11434',# Ollama listening on this port'embedding':'nomic-embed-text',# Embedding model'preprocesstype':'',# Leave as is'partition':'-1',# Leave as is'vectordbcollectionname':'tml-llm-model-v2',# change as needed'concurrency':'2',# change as needed Leave at 1'CUDA_VISIBLE_DEVICES':'0',# change as needed'temperature':'0.1',# This value ranges between 0 and 1, it controls how conservative LLM model will be, if 0 very very, if 1 it will hallucinate#--------------------'ollama-model':'llama3.1','deletevectordbcount':'10','vectordbpath':'/rawdata/vectordb','contextwindow':'10000','localmodelsfolder':'/mnt/c/maads/tml-airflow/rawdata/ollama'}############################################################### DO NOT MODIFY BELOW ####################################################VIPERTOKEN=""VIPERHOST=""VIPERPORT=""HTTPADDR=""mainproducerid=default_args['producerid']defsetollama(model):############### Ollama Model ################################## model=default_args['ollama-model']temperature=float(default_args['temperature'])embeddingmodel=default_args['embedding']#"nomic-embed-text"mainip=default_args['mainip']mainport=int(default_args['mainport'])contextwindow=default_args['contextwindow']# mainmodels = model.split(",") # agent,teamlead,supervisorif'KUBE'inos.environ:ifos.environ['KUBE']=="1":default_args['mainip']="ollama-service"mainip=default_args['mainip']print("model====",model)gotllm=0foriinrange(30):print("Checking if LLM loaded..wait")try:llm=ChatOllama(model=model,base_url=mainip+":"+str(mainport),temperature=temperature,num_ctx=int(contextwindow))gotllm=1print("LLM loaded")breakexceptExceptionase:print("Error=",e)time.sleep(5)ifgotllm==0:print("ERROR STEP 9b: Cannot load Ollama LLM model '{}' not found.".format(model))tsslogging.locallogs("ERROR","STEP 9b: Cannot load Ollama LLM model '{}' not found.".format(model))return"",""try:ollama_emb=OllamaEmbedding(base_url=mainip+":"+str(mainport),model_name=embeddingmodel)exceptExceptionase:print("ERROR STEP 9b: Cannot load Ollama embedding '{}' not found.".format(embeddingmodel))tsslogging.locallogs("ERROR","STEP 9b: Cannot load Ollama embedding '{}' not found.".format(embeddingmodel))return"",""Settings.embed_model=ollama_embSettings.llm=llmreturnllm,ollama_embdefcheckforloadedmodels(mainmodel):if'KUBE'inos.environ:ifos.environ['KUBE']=="1":default_args['mainip']="ollama-service"mainip=default_args['mainip']mainip=default_args['mainip']mainport=int(default_args['mainport'])OLLAMA_URL=f"{mainip}:{mainport}/api/tags"count=0whileTrue:try:response=requests.get(OLLAMA_URL)response.raise_for_status()data=response.json()# Assume 'models' key contains the list of available/loaded modelsloaded_models=[modelformodelindata.get("models",[])]print("loaded_models=",loaded_models)ifmainmodelinjson.dumps(loaded_models)ormainmodel+":latest"injson.dumps(loaded_models):print(f"Model {mainmodel} found")return1else:pull_ollama_model(mainmodel)# pull the modeltime.sleep(5)count+=1ifcount>600:breakelse:continueexceptExceptionase:print(f"Error querying Ollama server: {e} Will keep trying")time.sleep(5)count+=1ifcount>20:breakcontinuereturn0defget_loaded_models():if'KUBE'inos.environ:ifos.environ['KUBE']=="1":default_args['mainip']="ollama-service"mainip=default_args['mainip']mainip=default_args['mainip']mainport=int(default_args['mainport'])mainmodel=default_args['ollama-model']mainmodel=mainmodel.split(",")[0]#check if one model is thereOLLAMA_URL=f"{mainip}:{mainport}/api/tags"count=0whileTrue:try:response=requests.get(OLLAMA_URL)response.raise_for_status()data=response.json()# Assume 'models' key contains the list of available/loaded modelsloaded_models=[modelformodelindata.get("models",[])]print("loaded_models=",loaded_models)ifmainmodelinjson.dumps(loaded_models)ormainmodel+":latest"injson.dumps(loaded_models):print(f"Model {mainmodel} found")return1else:time.sleep(5)count+=1ifcount>600:breakelse:continueexceptExceptionase:print(f"Error querying Ollama server: {e} Will keep trying")time.sleep(5)count+=1ifcount>20:breakcontinuereturn0defremove_escape_sequences(string):returnstring.encode('utf-8').decode('unicode_escape')defcleanstringjson(mainstr):mainstr=mainstr.replace("'","").replace('`',"").replace("\n","").replace("\\n","").replace("\t","").replace("\\t","").replace("\r","").replace("\\r","").replace("\\*","").replace("\\ ","").replace("\\\\","\\")a=list(mainstr.lower())b="abcdefghijklmnopqrstuvwxyz-*123456789'{}`"i=0forcharina:ifchar=="\\"anda[i+1]inb:a[i]=''ifchar=="\\"anda[i+1]=="\\"anda[i+2]=='"':a[i]=''i=i+1mainstr=''.join(a)mainstr=re.sub(r'[\n\r]+','',mainstr)mainstr=mainstr.translate({ord('\n'):None,ord('\r'):None})mainstr=" ".join(mainstr.splitlines())returnmainstrdefcleanstring(mainstr):mainstr=mainstr.replace('"',"").replace("'","").replace('`',"").replace("\n","").replace("\\n","").replace("\t","").replace("\\t","").replace("\r","").replace("\\r","").replace("\\*","").replace("\\ ","").replace("\\\\","\\").replace("\\1","1").replace("\\2","2").replace("\\3","3").replace("\\4","4").replace("\\5","5").replace("\\6","6").replace("\\7","7").replace("\\8","8").replace("\\9","9")mainstr=mainstr.splitlines()mainstr=" ".join(mainstr)a=list(mainstr.lower())b="abcdefghijklmnopqrstuvwxyz-*123456789'{}`"i=0forcharina:ifchar=="\\"anda[i+1]inb:a[i]=''ifchar=="\\"anda[i+1]=="\\"anda[i+2]=='"':a[i]=''i=i+1mainstr=''.join(a)mainstr=re.sub(r'[\n\r]+','',mainstr)mainstr=mainstr.translate({ord('\n'):None,ord('\r'):None})returnmainstr############## Delete folder content ########################defdeletefoldercontents(dirpath,deletevectordbcnt):ifdeletevectordbcnt<int(default_args['deletevectordbcount']):deletevectordbcnt+=1returndeletevectordbcntelse:deletevectordbcn=0folder=dirpathforfilenameinos.listdir(folder):file_path=os.path.join(folder,filename)try:ifos.path.isfile(file_path)oros.path.islink(file_path):os.unlink(file_path)elifos.path.isdir(file_path):shutil.rmtree(file_path)exceptExceptionase:print('Failed to delete %s. Reason: %s'%(file_path,e))returndeletevectordbcnt########################### Vector DB for Team Lead: Agent Responses ################ this is for the team lead agent to consolidate information from individual agents###################################################################################defloadtextdataintovectordb(responses,deletevectordbcnt,llm):vectordbpath=default_args['vectordbpath']directory_path="{}/tmlvectortextindex".format(vectordbpath)ifnotos.path.exists(directory_path):os.makedirs(directory_path)# delete previous folder contentdeletevectordbcnt=deletefoldercontents(directory_path,deletevectordbcnt)documents=[Document(text=t)fortinresponses]#build indextml_index=VectorStoreIndex.from_documents(documents,embedding="local")#persist index# persist indextml_index.storage_context.persist(persist_dir=directory_path)tml_text_engine=tml_index.as_query_engine(llm=llm,similarity_top_k=3)returntml_text_engine,deletevectordbcntdefpull_ollama_model(model_name):""" Initiates an Ollama model pull using the Ollama API. Args: model_name (str): The name of the model to pull (e.g., "llama3"). """mainip=default_args['mainip']mainport=int(default_args['mainport'])url=f"{mainip}:{mainport}/api/pull"# Default Ollama API endpointheaders={"Content-Type":"application/json"}payload={"name":model_name}try:response=requests.post(url,headers=headers,data=json.dumps(payload),stream=True)response.raise_for_status()# Raise an exception for HTTP errorsprint(f"Initiating pull for model: {model_name}")forchunkinresponse.iter_content(chunk_size=None):ifchunk:# Process the streaming response, e.g., print progresstry:data=json.loads(chunk.decode('utf-8'))if'status'indata:print(f"Status: {data['status']}",end='\r')exceptjson.JSONDecodeError:pass# Handle incomplete JSON chunks if necessaryprint(f"\nPull for model '{model_name}' completed.")exceptrequests.exceptions.RequestExceptionase:print(f"Error pulling model '{model_name}': {e}")defstopcontainers():ollamacontainername=default_args['ollamacontainername']cfound=0subprocess.call("docker image ls > gptfiles.txt",shell=True)withopen('gptfiles.txt','r',encoding='utf-8')asfile:data=file.readlines()r=0fordindata:darr=d.split(" ")if'-privategpt-'indarr[0]:buf="docker stop $(docker ps -q --filter ancestor={} )".format(darr[0])ifollamacontainernameindarr[0]:cfound=1# if ollama container found check if model is already loaded - if not stop containerifget_loaded_models()==0:print(buf)subprocess.call(buf,shell=True)return0breakifcfound==0:print("INFO STEP 9b: Ollama container {} not found. It may need to be pulled.".format(ollamacontainername))tsslogging.locallogs("WARN","STEP 9b: Ollama container not found. It may need to be pulled if it does not start: docker pull {}".format(ollamacontainername))return0return1defstartpgptcontainer():print("Starting Ollama container: {}".format(default_args['ollamacontainername']))collection=default_args['vectordbcollectionname']concurrency=default_args['concurrency']ollamacontainername=default_args['ollamacontainername']mainport=int(default_args['mainport'])cuda=int(default_args['CUDA_VISIBLE_DEVICES'])temp=default_args['temperature']mainmodel=default_args['ollama-model']mainembedding=default_args['embedding']mainhost=default_args['mainip']mainmodels=mainmodel.split(",")mainmodel=" && ".join(mainmodels)ollamaserver=mainhost+":"+str(mainport)localmodels=''ifdefault_args['localmodelsfolder']!='':localmodels="-v "+default_args['localmodelsfolder']+":/root/.ollama:z"time.sleep(10)ifos.environ['TSS']=="1":buf="docker run -d -p {}:{} --net=host --gpus all -v /var/run/docker.sock:/var/run/docker.sock:z {} --env OLLAMA_LOAD_TIMEOUT=30m0s --env PORT={} --env TSS=1 --env GPU=1 --env COLLECTION={} --env WEB_CONCURRENCY={} --env CUDA_VISIBLE_DEVICES={} --env TOKENIZERS_PARALLELISM=false --env temperature={} --env LLAMAMODEL=\"{}\" --env mainembedding=\"{}\" --env OLLAMASERVERPORT=\"{}\"{}".format(mainport,mainport,localmodels,mainport,collection,concurrency,cuda,temperature,mainmodel,mainembedding,ollamaserver,ollamacontainername)else:buf="docker run -d -p {}:{} --net=host --gpus all -v /var/run/docker.sock:/var/run/docker.sock:z {} --env OLLAMA_LOAD_TIMEOUT=30m0s --env PORT={} --env TSS=0 --env GPU=1 --env COLLECTION={} --env WEB_CONCURRENCY={} --env CUDA_VISIBLE_DEVICES={} --env TOKENIZERS_PARALLELISM=false --env temperature={} --env LLAMAMODEL=\"{}\" --env mainembedding=\"{}\" --env OLLAMASERVERPORT=\"{}\"{}".format(mainport,mainport,localmodels,mainport,collection,concurrency,cuda,temperature,mainmodel,mainembedding,ollamaserver,ollamacontainername)ifstopcontainers()==1:return1,buf,mainmodel,mainembeddingv=subprocess.call(buf,shell=True)print("INFO STEP 9b: Ollama container. Here is the run command: {}, v={}".format(buf,v))tsslogging.locallogs("INFO","STEP 9b: Ollama container. Here is the run command: {}, v={}".format(buf,v))returnv,buf,mainmodel,mainembeddingdefproducegpttokafka(value,maintopic):inputbuf=value.strip()topicid=int(default_args['topicid'])producerid=default_args['producerid']identifier=default_args['identifier']# Add a 7000 millisecond maximum delay for VIPER to wait for Kafka to return confirmation message is received and written to topicdelay=default_args['delay']enabletls=default_args['enabletls']inputbuf=cleanstringjson(inputbuf)try:result=maadstml.viperproducetotopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,producerid,enabletls,delay,'','','',0,inputbuf,'',topicid,identifier)print(result)exceptExceptionase:print("ERROR:",e)defconsumefromtopic(maintopic):rollbackoffsets=int(default_args['rollbackoffset'])enabletls=int(default_args['enabletls'])consumerid=default_args['consumerid']companyname=default_args['companyname']offset=int(default_args['offset'])brokerhost=default_args['brokerhost']brokerport=int(default_args['brokerport'])microserviceid=default_args['microserviceid']topicid=default_args['topicid']preprocesstype=default_args['preprocesstype']delay=int(default_args['delay'])partition=int(default_args['partition'])print("before viperconsume",VIPERHOST,VIPERPORT,maintopic)result=maadstml.viperconsumefromtopic(VIPERTOKEN,VIPERHOST,VIPERPORT,maintopic,consumerid,companyname,partition,enabletls,delay,offset,brokerhost,brokerport,microserviceid,topicid,rollbackoffsets,preprocesstype)returnresultdefwindowname(wtype,sname,dagname):randomNumber=random.randrange(10,9999)wn="python-{}-{}-{},{}".format(wtype,randomNumber,sname,dagname)withopen("/tmux/pythonwindows_{}.txt".format(sname),'a',encoding='utf-8')asfile:file.writelines("{}\n".format(wn))returnwn############# Get the real-time data from the data streams #########################defgetjsonsfromtopics(topics):print("in getjsonsfromtopics==",topics)topicsarr=topics.split("->>")topicjsons=[]fortintopicsarr:t=t.strip()t2=t.split("<<-")[0].strip()try:jsonvalue=consumefromtopic(t2)exceptExceptionase:print("error=",e)topicjsons.append(jsonvalue)returntopicjsonsdefextract_hyperpredictiondata(hjson):print("in extract")hyper_json=json.loads(hjson)hnum=0pt=""pv=""mainuid=""jbufs=""iflen(hyper_json['streamtopicdetails']['topicreads'])==0:return""foriteminhyper_json['streamtopicdetails']['topicreads']:jbuf=""if"preprocesstype"initem:ptypes=item['preprocesstype']pt=ptypesiden=item['identifier']idenarr=iden.split("~")pv=idenarr[0]hyperprediction=str(item['hyperprediction'])hnum=round(float(hyperprediction))if"islogistic"initem:pv="machine learning"ifitem['islogistic']=="1":pt="probability prediction"hyperprediction=str(item['hyperprediction'])hnum=round(float(hyperprediction)*100)else:hyperprediction=str(item['hyperprediction'])hnum=round(float(hyperprediction))pt="prediction"if"identifier"initem:iden=item['identifier']idenarr=iden.split("~")mainuid=idenarr[-1]mainuid=mainuid.split("=")[1]jbuf='{"hp":'+str(hnum)+',"pt":"'+pt+'", "pv":"'+pv+'", "uid":"'+mainuid+'"}'jbufs=jbufs+jbuf+","hliststr="["+jbufs[:-1]+"]"hliststr=re.sub(r'[\n\r]+','',hliststr)hliststr=hliststr.translate({ord('\n'):None,ord('\r'):None})print("hliststr==",hliststr)returnhliststrdefcheckjson(cjson):model=default_args['ollama-model']temperature=float(default_args['temperature'])embeddingmodel=default_args['embedding']cjson=cjson.strip()try:checkedjson=json.loads(cjson)# check to see if json loads - if not its badexceptExceptionase:print("Json error=",e)ifcjson[-1]!='}':if"Model"notincjsonand"Embedding"notincjsonand"Temperature"notincjson:cjson=cjson+'","Model": "'+model+'","Embedding":"'+embeddingmodel+'", "Temperature":"'+str(temperature)+'"}'else:cjson=cjson+'"}'elifcjson[-2]!='"':if"Model"notincjsonand"Embedding"notincjsonand"Temperature"notincjson:cjson=cjson[:-1]+'","Model": "'+model+'","Embedding":"'+embeddingmodel+'", "Temperature":"'+str(temperature)+'"}'else:cjson=cjson[:-1]+'"}'cjson=repair_json(cjson,skip_json_loads=True)pass# bad jsonreturncjsondefagentquerytopics(usertopics,topicjsons,llm):topicsarr=usertopics.split("->>")bufresponse=""bufarr=[]agenttopic=default_args['agenttopic']model=default_args['ollama-model']temperature=float(default_args['temperature'])embeddingmodel=default_args['embedding']md=model.split(",")model=md[0]iflen(topicsarr)==0:print("No topics data")return"",""responses=[]fort,mainjsoninzip(topicsarr,topicjsons):t=t.strip()t2=t.split("<<-")mainjson=mainjson.lower()if"hyperprediction"inmainjson:mainjson=extract_hyperpredictiondata(mainjson)ifmainjson=="":continueif"<<data>>"int2[1]:query_str=t2[1]query_str=query_str.replace("<<data>>",f"{mainjson}")print("query_string====",query_str)# Invoking with a stringprint("------before llm invoke===")response=llm.invoke(query_str)response=str(response.content)prompt=cleanstring(t2[1].strip())response=cleanstring(response)response=response.replace(";",",").replace(":","").replace("'","").replace('"',"")bufresponse='{"Date": "'+str(datetime.now(timezone.utc))+'","Agent_Name": "Topic_Agent", "Topic": "'+t2[0].strip()+'","Prompt":"'+prompt+'","Response": "'+response.strip()+'","Model": "'+model+'","Embedding":"'+embeddingmodel+'", "Temperature":"'+str(temperature)+'"}'bufresponse=checkjson(bufresponse)print("======bufresponse====",bufresponse)bufarr.append(bufresponse)producegpttokafka(bufresponse,agenttopic)responses.append(response)returnresponses,bufarrdefteamleadqueryengine(tml_text_engine):bufresponse=""model=default_args['ollama-model']md=model.split(",")iflen(md)>1:model=md[1]temperature=float(default_args['temperature'])embeddingmodel=default_args['embedding']teamleadprompt=teamleadprompt.replace(";"," ")response=tml_text_engine.query(teamleadprompt)response=str(response)# print("team repsose = ", response)prompt=cleanstring(teamleadprompt.strip())response=cleanstring(response.strip())response=response.replace(";",",").replace(":","").replace('"',"").replace("'","")bufresponse='{"Date": "'+str(datetime.now(timezone.utc))+'","Agent_Name": "Team_Lead_Agent", "Topic": "'+default_args['teamlead_topic']+'","Prompt":"'+prompt+'","Response": "'+response.strip()+'","Model": "'+model+'","Embedding":"'+embeddingmodel+'", "Temperature":"'+str(temperature)+'"}'bufresponse=checkjson(bufresponse)producegpttokafka(bufresponse,default_args['teamlead_topic'])returnresponse,bufresponse################ Create Supervisordefcreateactionagents(llm,sname):print("in createactionagents")repo=tsslogging.getrepo()agents=[]filepath=f"/{repo}/tml-airflow/dags/tml-solutions/{sname}/agenttools.py"print("filepath===",filepath)module_name="agenttools"spec=importlib.util.spec_from_file_location(module_name,filepath)dynamic_module=importlib.util.module_from_spec(spec)spec.loader.exec_module(dynamic_module)maintools=default_args['agenttoolfunctions'].strip()funcname=maintools.split("->>")forfinfuncname:iflen(f)>2:f=f.strip()fname=f.split("<<-")[0]print(fname)func_objects=[]func_object=getattr(dynamic_module,fname)func_objects.append(func_object)aname=f.split("<<-")[1]aprompt=f.split("<<-")[2]agent=create_react_agent(model=llm,tools=func_objects,name=aname,prompt=aprompt)agents.append(agent)returnagentsdefcreateasupervisor(agents,supervisorprompt,llm):print("in createasupervisor==",supervisorprompt)supervisorprompt=supervisorprompt.replace(";"," ")workflow=create_supervisor(agents,model=llm,prompt=supervisorprompt)# Compile and runapp=workflow.compile()returnappdefinvokesupervisor(app,maincontent):model=default_args['ollama-model']md=model.split(",")iflen(md)>2:model=md[2]temperature=float(default_args['temperature'])embeddingmodel=default_args['embedding']funcname=default_args['agenttoolfunctions']funcname=funcname.replace(";","==")maincontent=maincontent.replace(";",",")try:supervisormaincontent=""" Here is the team lead's assessment: {}. Based on the Team Lead's assessment what is the appropriate action. """.format(maincontent)result=app.invoke({"messages":[{"role":"user","content":supervisormaincontent}]})exceptExceptionase:print("WARN STEP 9b: Agentic AI: unable to create supervisor agent")tsslogging.locallogs("WARN","STEP 9b: Agentic AI: unable to create supervisor agent")return"error","error"lastmessage=""forchunkinapp.stream(input=result,stream_mode="values",):ifchunk["messages"][-1].content!="":lastmessage=chunk["messages"][-1].contentlastmessage=str(lastmessage)lastmessage=cleanstring(lastmessage.strip())lastmessage=lastmessage.replace(";",",").replace("'","").replace('"',"").replace(":","")bufresponse='{"Date": "'+str(datetime.now(timezone.utc))+'","Agent_Name": "Supervisor_Agent", "Topic": "'+default_args['supervisor_topic']+'","Prompt":"'+supervisormaincontent+'","Response": "'+lastmessage.strip()+'","Model": "'+model+'","Embedding":"'+embeddingmodel+'", "Temperature":"'+str(temperature)+'"}'mainjson=[]mainstr=""forminresult["messages"]:mainjson.append(pprint.pformat(m))# mainstr = mainstr + json.dumps(str(m.json)) + ","mainjson=json.dumps({"supervisor_workflow_invocation":mainjson})mainjson=mainjson[:-1]+",\"funcname\":"+json.dumps(funcname)+",\"supervisorprompt\":\""+supervisormaincontent+"\"}"mainjson=cleanstring(mainjson)mainjson=checkjson(mainjson)try:#print(mainjson)producegpttokafka(mainjson,default_args['supervisor_topic'])returnmainjson,bufresponseexceptExceptionase:print("ERROR: invalid json")return"error","error"defformatcompletejson(bufresponses,teamlead_response,lastmessage):bufresponses=" ".join(str(bufresponses).splitlines())teamlead_response=" ".join(str(teamlead_response).splitlines())lastmessage=" ".join(str(lastmessage).splitlines())bufresponses=" ".join(bufresponses.split(" "))teamlead_response=" ".join(teamlead_response.split(" "))lastmessage=" ".join(lastmessage.split(" "))bufresponses=bufresponses.replace("'","").replace("\n"," ").replace("\\n"," ").replace("\t"," ").replace("\r"," ").replace("#","").strip()teamlead_response=teamlead_response.replace("'","").replace("\n"," ").replace("\\n"," ").replace("\t"," ").replace("\r"," ").replace("#","").strip()lastmessage=lastmessage.replace("'","").replace("\n"," ").replace("\t"," ").replace("\\n"," ").replace("\r"," ").replace("#","").strip()print("bufresponses===",bufresponses)print("teambuf===",teambuf)print("supbuf===",supbuf)# check if validtry:jvalid=json.loads(bufresponses)exceptExceptionase:bufresponses='[{"Status": "no data found", "Model": "na", "Embedding": "na", "Temperature": "na", "Prompt": "na", "Response": "no data found", "Date": "'+str(datetime.now(timezone.utc))+'", "Agent_Name": "", "Topic": "na"}]'try:jvalid=json.loads(teamlead_response)exceptExceptionase:teamlead_response='{"Status": "no data found", "Model": "na", "Embedding": "na", "Temperature": "na", "Prompt": "na", "Response": "no data found", "Date": "'+str(datetime.now(timezone.utc))+'", "Agent_Name": "Team Lead agent", "Topic": "na"}'try:jvalid=json.loads(lastmessage)exceptExceptionase:lastmessage='{"Status": "no data found", "Model": "na", "Embedding": "na", "Temperature": "na", "Prompt": "na", "Response": "Error - likely a Tool could not be run. Check your tools.", "Date": "'+str(datetime.now(timezone.utc))+'", "Agent_Name": "Supervisor agent", "Topic": "na"}'mainjson=bufresponses[:-1]+","+teamlead_response+","+lastmessage+"]"mainjson=" ".join(mainjson.split())mainjson=" ".join(mainjson.splitlines())mainjson=re.sub(r'[\n\r]+','',mainjson)mainjson=mainjson.replace("'","").replace("\n"," ").replace("\\n"," ").replace("\t"," ").replace("\r"," ").replace("\\r"," ").strip()mainjson=mainjson.translate({ord('\n'):None,ord('\r'):None})print("mainjson======",mainjson)returnmainjsondefstartagenticai(**context):sd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))pname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))if'step9brollbackoffset'inos.environ:ifos.environ['step9brollbackoffset']!='':default_args['rollbackoffset']=os.environ['step9brollbackoffset']if'step9bollama-model'inos.environ:ifos.environ['step9bollama-model']!='':default_args['ollama-model']=os.environ['step9bollama-model']if'step9bdeletevectordbcount'inos.environ:ifos.environ['step9bdeletevectordbcount']!='':default_args['deletevectordbcount']=os.environ['step9bdeletevectordbcount']if'step9bvectordbpath'inos.environ:ifos.environ['step9bvectordbpath']!='':default_args['vectordbpath']=os.environ['step9bvectordbpath']if'step9btemperature'inos.environ:ifos.environ['step9btemperature']!='':default_args['temperature']=os.environ['step9btemperature']if'step9bvectordbcollectionname'inos.environ:ifos.environ['step9bvectordbcollectionname']!='':default_args['vectordbcollectionname']=os.environ['step9bvectordbcollectionname']if'step9bollamacontainername'inos.environ:ifos.environ['step9bollamacontainername']!='':default_args['ollamacontainername']=os.environ['step9bollamacontainername']if'step9bCUDA_VISIBLE_DEVICES'inos.environ:ifos.environ['step9bCUDA_VISIBLE_DEVICES']!='':default_args['CUDA_VISIBLE_DEVICES']=os.environ['step9bCUDA_VISIBLE_DEVICES']if'step9bmainip'inos.environ:ifos.environ['step9bmainip']!='':default_args['mainip']=os.environ['step9bmainip']if'step9bmainport'inos.environ:ifos.environ['step9bmainport']!='':default_args['mainport']=os.environ['step9bmainport']if'step9bembedding'inos.environ:ifos.environ['step9bembedding']!='':default_args['embedding']=os.environ['step9bembedding']if'step9bagents_topic_prompt'inos.environ:ifos.environ['step9bagents_topic_prompt']!='':default_args['agents_topic_prompt']=os.environ['step9bagents_topic_prompt']if'step9bagenttopic'inos.environ:ifos.environ['step9bagenttopic']!='':default_args['agenttopic']=os.environ['step9bagenttopic']if'step9bteamlead_topic'inos.environ:ifos.environ['step9bteamlead_topic']!='':default_args['teamlead_topic']=os.environ['step9bteamlead_topic']if'step9bteamleadprompt'inos.environ:ifos.environ['step9bteamleadprompt']!='':default_args['teamleadprompt']=os.environ['step9bteamleadprompt']if'step9bsupervisor_topic'inos.environ:ifos.environ['step9bsupervisor_topic']!='':default_args['supervisor_topic']=os.environ['step9bsupervisor_topic']if'step9bagenttoolfunctions'inos.environ:ifos.environ['step9bagenttoolfunctions']!='':default_args['agenttoolfunctions']=os.environ['step9bagenttoolfunctions']if'step9bagent_team_supervisor_topic'inos.environ:ifos.environ['step9bagent_team_supervisor_topic']!='':default_args['agent_team_supervisor_topic']=os.environ['step9bagent_team_supervisor_topic']if'step9bcontextwindow'inos.environ:ifos.environ['step9bcontextwindow']!='':default_args['contextwindow']=os.environ['step9bcontextwindow']if'step9blocalmodelsfolder'inos.environ:ifos.environ['step9blocalmodelsfolder']!='':default_args['localmodelsfolder']=os.environ['step9blocalmodelsfolder']VIPERTOKEN=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERTOKEN".format(sname))VIPERHOST=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESSAGENTICAI".format(sname))VIPERPORT=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESSAGENTICAI".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HTTPADDR".format(sname))ti=context['task_instance']ti.xcom_push(key="{}_rollbackoffset".format(sname),value="_{}".format(default_args['rollbackoffset']))ti.xcom_push(key="{}_ollama-model".format(sname),value=default_args['ollama-model'])ti.xcom_push(key="{}_deletevectordbcount".format(sname),value="_{}".format(default_args['deletevectordbcount']))ti.xcom_push(key="{}_vectordbpath".format(sname),value="{}".format(default_args['vectordbpath']))ti.xcom_push(key="{}_temperature".format(sname),value="_{}".format(default_args['temperature']))ti.xcom_push(key="{}_topicid".format(sname),value="_{}".format(default_args['topicid']))ti.xcom_push(key="{}_enabletls".format(sname),value="_{}".format(default_args['enabletls']))ti.xcom_push(key="{}_partition".format(sname),value="_{}".format(default_args['partition']))ti.xcom_push(key="{}_vectordbcollectionname".format(sname),value=default_args['vectordbcollectionname'])ti.xcom_push(key="{}_ollamacontainername".format(sname),value=default_args['ollamacontainername'])ti.xcom_push(key="{}_mainip".format(sname),value=default_args['mainip'])ti.xcom_push(key="{}_mainport".format(sname),value="_{}".format(default_args['mainport']))ti.xcom_push(key="{}_embedding".format(sname),value=default_args['embedding'])ti.xcom_push(key="{}_agents_topic_prompt".format(sname),value=default_args['agents_topic_prompt'])ti.xcom_push(key="{}_teamlead_topic".format(sname),value=default_args['teamlead_topic'])ti.xcom_push(key="{}_teamleadprompt".format(sname),value=default_args['teamleadprompt'])ti.xcom_push(key="{}_supervisor_topic".format(sname),value=default_args['supervisor_topic'])ti.xcom_push(key="{}_supervisorprompt".format(sname),value=default_args['supervisorprompt'])at=default_args['agenttoolfunctions']at=at.replace(SMTP_PASSWORD,'')ti.xcom_push(key="{}_agenttoolfunctions".format(sname),value=at)ti.xcom_push(key="{}_agent_team_supervisor_topic".format(sname),value=default_args['agent_team_supervisor_topic'])ti.xcom_push(key="{}_concurrency".format(sname),value="_{}".format(default_args['concurrency']))ti.xcom_push(key="{}_cuda".format(sname),value="_{}".format(default_args['CUDA_VISIBLE_DEVICES']))ti.xcom_push(key="{}_agenttopic".format(sname),value="{}".format(default_args['agenttopic']))ti.xcom_push(key="{}_contextwindow".format(sname),value="_{}".format(default_args['contextwindow']))ti.xcom_push(key="{}_localmodelsfolder".format(sname),value="{}".format(default_args['localmodelsfolder']))repo=tsslogging.getrepo()ifsname!='_mysolution_':fullpath="/{}/tml-airflow/dags/tml-solutions/{}/{}".format(repo,pname,os.path.basename(__file__))else:fullpath="/{}/tml-airflow/dags/{}".format(repo,os.path.basename(__file__))wn=windowname('agenticai',sname,sd)subprocess.run(["tmux","new","-d","-s","{}".format(wn)])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"cd /Viper-preprocess-agenticai","ENTER"])subprocess.run(["tmux","send-keys","-t","{}".format(wn),"python {} 1 {}{}{}{}\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"{}{}{}{}\"{}\"\"{}\"{}{}\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"\"{}\"{}\"{}\"\"{}\"".format(fullpath,VIPERTOKEN,HTTPADDR,VIPERHOST,VIPERPORT[1:],default_args['rollbackoffset'],default_args['ollama-model'],default_args['deletevectordbcount'],default_args['vectordbpath'],default_args['temperature'],default_args['topicid'],default_args['enabletls'],default_args['partition'],default_args['vectordbcollectionname'],default_args['ollamacontainername'],default_args['mainip'],default_args['mainport'],default_args['embedding'],default_args['agents_topic_prompt'],default_args['teamlead_topic'],default_args['teamleadprompt'],default_args['supervisor_topic'],default_args['supervisorprompt'],default_args['agenttoolfunctions'],default_args['agent_team_supervisor_topic'],default_args['concurrency'],default_args['CUDA_VISIBLE_DEVICES'],pname,default_args['contextwindow'],default_args['localmodelsfolder'],default_args['agenttopic']),"ENTER"])if__name__=='__main__':iflen(sys.argv)>1:ifsys.argv[1]=="1":repo=tsslogging.getrepo()VIPERTOKEN=sys.argv[2]VIPERHOST=sys.argv[3]VIPERPORT=sys.argv[4]rollbackoffset=sys.argv[5]ollamamodel=sys.argv[6]deletevectordb=sys.argv[7]vectordbpath=sys.argv[8]temperature=sys.argv[9]topicid=sys.argv[10]enabletls=sys.argv[11]partition=sys.argv[12]vectordbcollectionname=sys.argv[13]ollamacontainername=sys.argv[14]mainip=sys.argv[15]mainport=sys.argv[16]embedding=sys.argv[17]agents_topic_prompt=sys.argv[18]teamlead_topic=sys.argv[19]teamleadprompt=sys.argv[20]supervisor_topic=sys.argv[21]supervisorprompt=sys.argv[22]agenttoolfunctions=sys.argv[23]agent_team_supervisor_topic=sys.argv[24]concurrency=sys.argv[25]cuda=sys.argv[26]pname=sys.argv[27]contextwindow=sys.argv[28]localmodelsfolder=sys.argv[29]agenttopic=sys.argv[30]default_args['rollbackoffset']=rollbackoffsetdefault_args['ollama-model']=ollamamodeldefault_args['deletevectordbcount']=deletevectordbdefault_args['vectordbpath']=vectordbpathdefault_args['temperature']=temperaturedefault_args['topicid']=topiciddefault_args['enabletls']=enabletlsdefault_args['partition']=partitiondefault_args['vectordbcollectionname']=vectordbcollectionnamedefault_args['ollamacontainername']=ollamacontainernamedefault_args['mainip']=mainipdefault_args['mainport']=mainportdefault_args['embedding']=embeddingdefault_args['agents_topic_prompt']=agents_topic_promptdefault_args['teamlead_topic']=teamlead_topicdefault_args['teamleadprompt']=teamleadpromptdefault_args['supervisor_topic']=supervisor_topicdefault_args['supervisorprompt']=supervisorpromptdefault_args['agenttoolfunctions']=agenttoolfunctionsdefault_args['agent_team_supervisor_topic']=agent_team_supervisor_topicdefault_args['concurrency']=concurrencydefault_args['CUDA_VISIBLE_DEVICES']=cudadefault_args['contextwindow']=contextwindowdefault_args['localmodelsfolder']=localmodelsfolderdefault_args['agenttopic']=agenttopicif"KUBE"notinos.environ:tsslogging.locallogs("INFO","STEP 9b: Starting Ollama container")v,buf,mainmodel,mainembedding=startpgptcontainer()ifv==1:tsslogging.locallogs("WARN","STEP 9b: There seems to be an issue starting the Ollama container. Here is the run command - try to run it nanually for testing: {}".format(buf))else:tsslogging.locallogs("INFO","STEP 9b: Success starting Ollama container. Here is the run command: {}".format(buf))time.sleep(10)# wait for containers to startelifos.environ["KUBE"]=="0":tsslogging.locallogs("INFO","STEP 9b: Starting ollama server")v,buf,mainmodel,mainembedding=startpgptcontainer()ifv==1:tsslogging.locallogs("WARN","STEP 9b: There seems to be an issue starting the Ollama container. Here is the run command - try to run it nanually for testing: {}".format(buf))else:tsslogging.locallogs("INFO","STEP 9b: Success starting Agentic AI. Here is the run command: {}".format(buf))time.sleep(10)# wait for containers to startelse:tsslogging.locallogs("INFO","STEP 9b: [KUBERNETES] Starting Agentic AI - LOOKS LIKE THIS IS RUNNING IN KUBERNETES")tsslogging.locallogs("INFO","STEP 9b: [KUBERNETES] Make sure you have applied the Agentic AI YAML files and have the agentic AI Pod running")count=0# create the Supervisor and kick off action# llmstatus = get_loaded_models()# print("llmstatus==",llmstatus,pname)mainmodels=default_args['ollama-model']models=mainmodels.split(",")#models must be agent,teamlead,supervisorembedding=Nonemodelsarr=[]forminmodels:llmstatus=get_loaded_models()checkforloadedmodels(m)print("llmstatus==",llmstatus,pname)llm,embedding=setollama(m.strip())modelsarr.append(llm)iflen(modelsarr)>2:#try:actionagents=createactionagents(modelsarr[2],pname)supervisorprompt=default_args['supervisorprompt']try:app=createasupervisor(actionagents,supervisorprompt,modelsarr[2])exceptExceptionase:print("Error=",e)tsslogging.locallogs("WARN","STEP 9b unable to create agents {}".format(e))else:tsslogging.locallogs("WARN","STEP 9b unable to load LLM - Aborting")print("WARN","STEP 9b unable to load LLM - Aborting")exit(0)deletevectordbcnt=0whileTrue:deletevectordbcnt+=1try:agent_topics=default_args['agents_topic_prompt']topicjsons=getjsonsfromtopics(agent_topics)responses,bufresponses=agentquerytopics(agent_topics,topicjsons,modelsarr[0])#try:tml_text_engine,deletevectordbcnt=loadtextdataintovectordb(responses,deletevectordbcnt,modelsarr[1])teamlead_response,teambuf=teamleadqueryengine(tml_text_engine)mainjson,supbuf=invokesupervisor(app,teamlead_response)complete=formatcompletejson(bufresponses,teambuf,supbuf)ifdefault_args['agent_team_supervisor_topic']!='':producegpttokafka(complete,default_args['agent_team_supervisor_topic'])time.sleep(1)exceptExceptionase:print("Error=",e)ifcount==0:tsslogging.locallogs("ERROR","STEP 9b: Agentic AI Step 9b DAG in {}{} Aborting after 10 consecutive errors.".format(os.path.basename(__file__),e))tsslogging.tsslogit("PrivateGPT Step 9b DAG in {}{} Aborting after 10 consecutive errors.".format(os.path.basename(__file__),e),"ERROR")tsslogging.git_push("/{}".format(repo),"Entry from {}".format(os.path.basename(__file__)),"origin")time.sleep(5)count=count+1ifcount>600:break
Below is an example of the configurations of Dag 9b above. In this example, we connect the send_email function in the Agenttools.py file to the supervisor agent. Note, that the SMTP parameters are environmental variables that are set when the solution container or TSS container is started.
default_args = {
'owner': 'Sebastian Maurice', # <<< *** Change as needed
'ollamacontainername' : 'maadsdocker/tml-privategpt-with-gpu-nvidia-amd64-llama3-tools', #'maadsdocker/tml-privategpt-no-gpu-amd64', # enter a valid container https://hub.docker.com/r/maadsdocker/tml-privategpt-no-gpu-amd64
'rollbackoffset' : '15', # <<< *** Change as needed
'offset' : '-1', # leave as is
'enabletls' : '1', # change as needed
'brokerhost' : '', # <<< *** Leave as is
'brokerport' : '-999', # <<< *** Leave as is
'microserviceid' : '', # change as needed
'topicid' : '-999', # leave as is
'delay' : '100', # change as needed
'companyname' : 'otics', # <<< *** Change as needed
'consumerid' : 'streamtopic', # <<< *** Leave as is
'agenttopic' : 'agent-responses', # this topic containes the individual agent responses
'agents_topic_prompt' : """
iot-preprocess<<-You are a precise data analysis assistant. Your task is to point out any anomalies or interesting insights that could help improve the performance and functioning of
IoT device. The json data are from IOT devices. the hp field shows the data that are processed for the process variable (pv), using the process types (pt) like:
avg or average, or trend analysis, or anomprob (i.e. anomaly probability) etc. The device being processed is in the uid field of the json.
here is the json data:
<<data>>
INSTRUCTIONS:
1. Examine each number in the json array
2. Provide a brief analysis of the results
FORMAT YOUR RESPONSE:
- Filtered results: [list the qualifying numbers with their "uid" fields]
- Count of qualifying numbers: [number]
- Analysis: [brief explanation of what the filter revealed]
Be precise and concise in your response.->>
iot-ml-prediction-results-output<<-You are a precise data analysis assistant. Your task is to filter and analyze numeric data based on specified criteria.
TASK: Filter numbers from the given json array using the threshold: greater than 90
Input JSON arrary:
<<data>>
INSTRUCTIONS:
1. Examine each number in the json array
2. Apply the filter condition: number > 90
3. Return only numbers that meet the criteria with their "uid" fields
4. If no numbers meet the criteria, explicitly state this
5. Provide a brief analysis of the results
FORMAT YOUR RESPONSE:
- Filtered results: [list the qualifying numbers with their "uid" fields]
- Count of qualifying numbers: [number]
- Analysis: [brief explanation of what the filter revealed]
Be precise and concise in your response.
""", # <topic agent will monitor:prompt you want for the agent>
'teamlead_topic' : 'team-lead-responses', # Enter the team lead topic - all team lead responses will be written to this topic
'teamleadprompt' : """
Analyze the dataset containing IoT device monitoring records managed by individual agents.
Review all data fields to determine whether there are any issues or major concerns requiring urgent attention.
Focus on the following criteria:
1. Each record contains a unique device identifier stored in the field "uid".
2. Examine the failure probability for each device stored in the hp field.
3. Categorize the probabilities as follows:
- Low: 0% to 50%
- Medium: 51% to 75%
- High: 76% to 89%
- Urgent: 90% to 100%
Tasks:
- Identify and highlight devices (by their "uid") that have **urgent failure probabilities** (≥ 90%).
- For each flagged device, provide details and reasoning on why it may require immediate investigation.
- Only include devices that meet the urgent threshold. Do not report on low, medium, or high categories unless relevant for context.
- State clearly whether the identified issue is *urgent*.
- Do not use or generate any code; perform a reasoning-based analysis directly from the provided data.
""", # Enter the team lead prompt
'supervisor_topic' : 'supervisor-responses', # Enter the supervisor topic - all supervisor responses will be written to this topic
'supervisorprompt' : """
You are a team supervisor analyzing operational device data and recommending whether an alert email should be send.
You manage a send email expert and a average expert.
For send email, use send_email agent.
For average, use average agent.
INSTRUCTIONS:
1.Analyze the Team Lead assessment and determine the proper action:
- If devices are marked urgent or failure probabilities exceed 90%, select "send_email".
- If no urgent devices are found or probabilities remain below thresholds, then no action is needed.
""", # Enter the supervisor prompt
'agenttoolfunctions' : """
send_email<<-send_email<<- You are an email-sending agent. Use smtp parameters to send emails when there is an anomaly in the data, make sure to
indicate the device name in the mainuid field. do not write a smtp script, actually send the email using the SMTP parameters
smtp_server='{}'
smtp_port={}
username='{}'
password='{}'
sender='{}'
recipient='{}'
subject=''
body=''->>
average<<-average<<-You are an average agent. Take average of the device failure probabilities.
""".format(SMTP_SERVER,SMTP_PORT,SMTP_USERNAME,SMTP_PASSWORD,SMTP_USERNAME,recipient), # enter the tools : tool_function is the name of the funtions in the agenttools python file
'agent_team_supervisor_topic': 'all-agents-responses', # this topic will hold the responses from agents, team lead and supervisor
'producerid' : 'agentic-ai', # <<< *** Leave as is
'identifier' : 'This is analysing TML output with Agentic AI',
'mainip': 'http://127.0.0.1', # Ollama server container listening on this host
'mainport' : '11434', # Ollama listening on this port
'embedding': 'nomic-embed-text', # Embedding model
'preprocesstype' : '', # Leave as is
'partition' : '-1', # Leave as is
'vectordbcollectionname' : 'tml-llm-model-v2', # change as needed
'concurrency' : '2', # change as needed Leave at 1
'CUDA_VISIBLE_DEVICES' : '0', # change as needed
'temperature' : '0.1', # This value ranges between 0 and 1, it controls how conservative LLM model will be, if 0 very very, if 1 it will hallucinate
#--------------------
'ollama-model': 'phi3:3.8b,phi3:3.8b,llama3.2:3b', # maximum 3 models can be specified: agent,teamlead,supervisor
'deletevectordbcount': '5',
'vectordbpath': '/rawdata/vectordb',
'contextwindow': '4096',
'localmodelsfolder': '/mnt/c/maads/tml-airflow/rawdata/ollama'
}
Below code allows users to incorporate any tools they want to their TML multi-agentic solutions.
Note
If your tool special Python libraries you can easily install these libraries using the def install_package(package_name, importname):
This gives tremendous flexibility in integrating tools that the AI cn execute in real-time..ie send_mail tool is added as an example.
You integrate the tools to your solution by configuring the agenttoolfunctions in Step 9b DAG.
# Agent Toolfromlangchain_core.toolsimporttoolfromemail.mime.textimportMIMETextfromemail.messageimportEmailMessageimportsmtplib#from langchain_tavily import TavilySearchimportsubprocessimportsys"""You must define all your tools here for your agents to executeYou can define as many agents tools you wantYOU MUST ALSO update funcnamefuncname = ["web_search:search_agent:You are a search expert","add:math_expert:You are a math expert","maxagent:max_agent:You find the company with maximum employees"]The format is funcname = ["<function name>,<function_name>:<agent name>:<prompt>","<function name>:<agent name>:<prompt>",...]NOTE: You can assign multiple functions to agents - separate multiple functions by a comma"""# if your tool requires a package you can install it using the install_package function# the function will check if package is already installeddefinstall_package(package_name,importname):""" Installs a specified Python package using pip. """try:__import__(importname)exceptImportError:print(f"Package '{package_name}' not found. Attempting to install...")try:subprocess.check_call([sys.executable,"-m","pip","install",package_name])print(f"Package '{package_name}' installed successfully.")exceptsubprocess.CalledProcessErrorase:print(f"Error installing package '{package_name}': {e}")#install_package("langchain-tavily","from langchain_tavily import TavilySearch")# SendEmail by Agent@tooldefsend_email(smtp_server:str,smtp_port:int,username:str,password:str,sender:str,recipient:str,subject:str,body:str)->bool:""" Sends an email reply via SMTP using the generated response. """recemails=recipient.split(",")try:# Use the updated format_email which preserves body line breaksmsg=EmailMessage()msg["Subject"]=subjectmsg["From"]=usernamemsg["To"]=recipientmsg.set_content(body)withsmtplib.SMTP(smtp_server,int(smtp_port))asserver:server.starttls()server.login(username,password)# server.send_message(msg)server.sendmail(username,recemails,msg.as_string())returnTrueexceptExceptionase:print("Failed to send email:",e)returnFalse#send_email({"smtp_server":"smtp.gmail.com","smtp_port":587,"username":SMTP_USERNAME,"password":SMTP_PASSWORD,"sender":SMTP_USERNAME,"recipient":recipientlist,"subject":"test","body":"test 2"})# Example: Add two numbers@tooldefadd(a:float,b:float)->float:'''Add two numbers.'''returna+b@tooldefweb_search(query:str)->str:'''Search the web for information.'''return"Searched the web"@tooldefmax_agent(query:list)->int:'''Find the company with the most employees.'''print(query)returnmax(query)@tooldefaverage(query:list)->int:'''Find the average.'''average=0.0iflen(query)!=0:average=sum(query)/len(query)average=round(average,2)returnaverage
TSS will automatically generate documentation for your solution at READTHEDOCS. Each TML solution you create will have its own
documentation that will detail the solution parameters in the DAGs. This is another unique and powerful feature of the TSS. This enables you to share your
documentation with others - almost instantly!
Tip
The TSS will develop the base documentation for your solution.
Note. Your documentation URL will be: https://<Your Solution Name>.readthedocs.io
Your Solution Name is the name you chose here: Lets Start Building a TML Solution plus first 4 characters of your ReadTheDocs token. This project is committed under the tml-solutions folder in Github.
Watch the YouTube to see how to configure this Dag: YouTube Video
fromairflowimportDAGfromairflow.operators.pythonimportPythonOperatorfromairflow.operators.bashimportBashOperatorfromdatetimeimportdatetimefromairflow.decoratorsimportdag,taskimportosimportsysimportrequestsimportjsonimportsubprocessimporttssloggingimportshutilfromgitimportRepoimporttimesys.dont_write_bytecode=True######################################################USER CHOSEN PARAMETERS ###########################################################default_args={'conf_project':'Transactional Machine Learning (TML)','conf_copyright':'2024, Otics Advanced Analytics, Incorporated - For Support email support@otics.ca','conf_author':'Sebastian Maurice','conf_release':'0.1','conf_version':'0.1.0','dockerenv':'',# add any environmental variables for docker must be: variable1=value1, variable2=value2'dockerinstructions':'',# add instructions on how to run the docker container}############################################################### DO NOT MODIFY BELOW ####################################################deftriggerbuild(sname):URL="https://readthedocs.org/api/v3/projects/{}/versions/latest/builds/".format(sname)TOKEN=os.environ['READTHEDOCS']HEADERS={'Authorization':f'token {TOKEN}'}response=requests.post(URL,headers=HEADERS)print(response.json())defupdatebranch(sname,branch):URL="https://readthedocs.org/api/v3/projects/{}/".format(sname)TOKEN=os.environ['READTHEDOCS']HEADERS={'Authorization':f'token {TOKEN}'}data={"name":"{}".format(sname),"repository":{"url":"https://github.com/{}/{}".format(os.environ['GITUSERNAME'],sname),"type":"git"},"default_branch":"{}".format(branch),"homepage":"http://template.readthedocs.io/","programming_language":"py","language":"en","privacy_level":"public","external_builds_privacy_level":"public","tags":["automation","sphinx"]}response=requests.patch(URL,json=data,headers=HEADERS,)defsetupurls(projectname,producetype,sname):ptype=""ifproducetype=="LOCALFILE":ptype=producetypeelifproducetype=="REST":ptype="RESTAPI"elifproducetype=="MQTT":ptype=producetypeelifproducetype=="gRPC":ptype=producetypestepurl1="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_1_getparams_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl2="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_2_kafka_createtopic_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl3="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_read_{}_step_3_kafka_producetotopic_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,ptype,projectname)stepurl4="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_4_kafka_preprocess_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl4a="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_4a_kafka_preprocess_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl4b="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_4b_kafka_preprocess_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl4c="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_4c_kafka_preprocess_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl5="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_5_kafka_machine_learning_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl6="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_6_kafka_predictions_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl7="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_7_kafka_visualization_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl8="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_8_deploy_solution_to_docker_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl9="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_9_privategpt_qdrant_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl9b="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_9b_agenticai_dag-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)stepurl10="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/tml_system_step_10_documentation_dag_tml-multi-agenticai-iot-3f10-{}.py".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,projectname)print("stepurl1=",stepurl1)doparse("/{}/docs/source/details.rst".format(sname),["--step1url--;{}".format(stepurl1)])doparse("/{}/docs/source/details.rst".format(sname),["--step2url--;{}".format(stepurl2)])doparse("/{}/docs/source/details.rst".format(sname),["--step3url--;{}".format(stepurl3)])doparse("/{}/docs/source/details.rst".format(sname),["--step4url--;{}".format(stepurl4)])doparse("/{}/docs/source/details.rst".format(sname),["--step4aurl--;{}".format(stepurl4a)])doparse("/{}/docs/source/details.rst".format(sname),["--step4burl--;{}".format(stepurl4b)])doparse("/{}/docs/source/details.rst".format(sname),["--step4curl--;{}".format(stepurl4c)])doparse("/{}/docs/source/details.rst".format(sname),["--step5url--;{}".format(stepurl5)])doparse("/{}/docs/source/details.rst".format(sname),["--step6url--;{}".format(stepurl6)])doparse("/{}/docs/source/details.rst".format(sname),["--step7url--;{}".format(stepurl7)])doparse("/{}/docs/source/details.rst".format(sname),["--step8url--;{}".format(stepurl8)])doparse("/{}/docs/source/details.rst".format(sname),["--step9url--;{}".format(stepurl9)])doparse("/{}/docs/source/details.rst".format(sname),["--step9burl--;{}".format(stepurl9b)])doparse("/{}/docs/source/details.rst".format(sname),["--step10url--;{}".format(stepurl10)])defdoparse(fname,farr):data=''try:withopen(fname,'r',encoding='utf-8')asfile:data=file.readlines()r=0fordindata:forfinfarr:fs=f.split(";")iffs[0]ind:data[r]=d.replace(fs[0],fs[1])r+=1withopen(fname,'w',encoding='utf-8')asfile:file.writelines(data)exceptExceptionase:passdefupdateollamaandpgpt(op,ollamacontainername,concurrency,collection,temp,rollback,ollama,deletevector,vectordbpath,topicid,enabletls,partition,mainip,mainport,embedding,agents_topic_prompt,teamlead_topic,teamleadprompt,supervisor_topic,supervisorprompt,agenttoolfunctions,agent_team_supervisor_topic,contextwindow,pvectorsearchtype,ptemperature,pcollection,pconcurrency,pvectordimension,pcontextwindowsize,mainmodel,mainembedding,pgptcontainername):print("update==",op)ifollamacontainername!=None:doparse("/{}/ollama.yml".format(op),["--ollamacontainername--;{}".format(ollamacontainername)])doparse("/{}/ollama.yml".format(op),["--agenticai-kubeconcur--;{}".format(concurrency[1:])])doparse("/{}/ollama.yml".format(op),["--agenticai-kubecollection--;{}".format(collection)])doparse("/{}/ollama.yml".format(op),["--agenticai-kubetemperature--;{}".format(temp)])doparse("/{}/ollama.yml".format(op),["--agenticai-rollbackoffset--;{}".format(rollback)])doparse("/{}/ollama.yml".format(op),["--agenticai-ollama-model--;{}".format(ollama)])doparse("/{}/ollama.yml".format(op),["--agenticai-deletevectordbcount--;{}".format(deletevector)])doparse("/{}/ollama.yml".format(op),["--agenticai-vectordbpath--;{}".format(vectordbpath)])doparse("/{}/ollama.yml".format(op),["--agenticai-topicid--;{}".format(topicid)])doparse("/{}/ollama.yml".format(op),["--agenticai-enabletls--;{}".format(enabletls)])doparse("/{}/ollama.yml".format(op),["--agenticai-partition--;{}".format(partition)])doparse("/{}/ollama.yml".format(op),["--agenticai-vectordbcollectionname--;{}".format(collection)])doparse("/{}/ollama.yml".format(op),["--agenticai-ollamacontainername--;{}".format(ollamacontainername)])doparse("/{}/ollama.yml".format(op),["--agenticai-mainip--;{}".format(mainip)])doparse("/{}/ollama.yml".format(op),["--agenticai-mainport--;{}".format(mainport)])doparse("/{}/ollama.yml".format(op),["--agenticai-embedding--;{}".format(embedding)])doparse("/{}/ollama.yml".format(op),["--agenticai-agents_topic_prompt--;{}".format(agents_topic_prompt.strip().replace('\n','').replace("\\n","").replace("'","").replace(";",","))])doparse("/{}/ollama.yml".format(op),["--agenticai-teamlead_topic--;{}".format(teamlead_topic)])doparse("/{}/ollama.yml".format(op),["--agenticai-teamleadprompt--;{}".format(teamleadprompt.strip().replace('\n','').replace("\\n","").replace("'","").replace(";",","))])doparse("/{}/ollama.yml".format(op),["--agenticai-supervisor_topic--;{}".format(supervisor_topic)])doparse("/{}/ollama.yml".format(op),["--agenticai-supervisorprompt--;{}".format(supervisorprompt.strip().replace('\n','').replace("\\n","").replace("'","").replace(";",","))])doparse("/{}/ollama.yml".format(op),["--agenticai-agenttoolfunctions--;{}".format(agenttoolfunctions.strip().replace('\n','').replace("\\n","").replace("'","").replace(";","=="))])doparse("/{}/ollama.yml".format(op),["--agenticai-agent_team_supervisor_topic--;{}".format(agent_team_supervisor_topic)])doparse("/{}/ollama.yml".format(op),["--agenticai-contextwindow--;{}".format(contextwindow)])ifpgptcontainername!=None:doparse("/{}/privategpt.yml".format(op),["--kubevectorsearchtype--;{}".format(pvectorsearchtype)])doparse("/{}/privategpt.yml".format(op),["--kubetemperature--;{}".format(ptemperature[1:])])doparse("/{}/privategpt.yml".format(op),["--kubecollection--;{}".format(pcollection)])doparse("/{}/privategpt.yml".format(op),["--kubeconcur--;{}".format(pconcurrency[1:])])doparse("/{}/privategpt.yml".format(op),["--kubevectordimension--;{}".format(pvectordimension[1:])])doparse("/{}/privategpt.yml".format(op),["--kubecontextwindowsize--;{}".format(pcontextwindowsize[1:])])doparse("/{}/privategpt.yml".format(op),["--kubemainmodel--;{}".format(mainmodel)])doparse("/{}/privategpt.yml".format(op),["--kubemainembedding--;{}".format(mainembedding)])doparse("/{}/privategpt.yml".format(op),["--kubeprivategpt--;{}".format(pgptcontainername)])defcopyymls(projectname,sname,ingressyml,solutionyml):orepo=tsslogging.getrepo()op=f"/{orepo}/tml-airflow/dags/tml-solutions/{projectname}/ymls"os.makedirs(op,exist_ok=True)op=f"/{orepo}/tml-airflow/dags/tml-solutions/{projectname}/ymls/{sname}"os.makedirs(op,exist_ok=True)tsslogging.writeoutymls(op,ingressyml,solutionyml,sname)returnopdefgeneratedoc(**context):istss1=1if'TSS'inos.environ:ifos.environ['TSS']=="1":istss1=1else:istss1=0if'tssdoc'inos.environ:ifos.environ['tssdoc']=="1":returnsd=context['dag'].dag_idsname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutionname".format(sd))# rtdsname = tsslogging.rtdprojects(sname,sd)kube=0step9prompt=''step9context=''step9keyattribute=''step9keyprocesstype=''step9hyperbatch=''step9vectordbcollectionname=''step9concurrency=''cudavisibledevices=''step9docfolder=''step9docfolderingestinterval=''step9useidentifierinprompt=''step5processlogic=''step5independentvariables=''step9searchterms=''step9streamall=''step9temperature=''step9vectorsearchtype=''step9pcontextwindowsize=''step9pgptcontainername=''step9pgpthost=''step9pgptport=''step9vectordimension=''step4crawdatatopic=''step4csearchterms=''step4crememberpastwindows=''step4cpatternwindowthreshold=''step4crtmsstream=''step4crtmsscorethreshold=''step4cattackscorethreshold=''step4cpatternscorethreshold=''step4clocalsearchtermfolder=''step4clocalsearchtermfolderinterval=''step4crtmsfoldername=''step3localfileinputfile=''step3localfiledocfolder=''step4crtmsmaxwindows=''rtmsoutputurl=""mloutputurl=""step2raw_data_topic=""step2preprocess_data_topic=""step4raw_data_topic=""step4preprocess_data_topic=''step4preprocesstypes=""step4jsoncriteria=""step4ajsoncriteria=""step4amaxrows=""step4apreprocesstypes=""step4araw_data_topic=""step4apreprocess_data_topic=""step4bpreprocesstypes=""step4bjsoncriteria=""step4bmaxrows=""step4braw_data_topic=""step4bpreprocess_data_topic=""step9brollback=""step9bdeletevectordbcount=""step9bvectordbpath=""step9btemperature=""step9bvectordbcollectionname=""step9bollamacontainername=""step9bCUDA_VISIBLE_DEVICES=""step9bmainip=""step9bmainport=""step9bembedding=""step9bagents_topic_prompt=""step9bteamlead_topic=""step9bteamleadprompt=""step9bsupervisor_topic=""step9bagenttoolfunctions=""step9bagent_team_supervisor_topic=""step9bconcurrency=""step9bollama=""step9btopicid=""step9benabletls=""step9bpartition=""step9bsupervisorprompt=""step9bcontextwindow=""step9blocalmodelsfolder=""step9bagenttopic=""if"KUBE"inos.environ:ifos.environ["KUBE"]=="1":kube=1returntsslogging.locallogs("INFO","STEP 10: Started to build the documentation")producinghost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPRODCE".format(sname))producingport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPRODUCE".format(sname))preprocesshost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS".format(sname))preprocessport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS".format(sname))preprocesshost2=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS2".format(sname))preprocessport2=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS2".format(sname))mlhost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTML".format(sname))mlport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTML".format(sname))predictionhost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREDICT".format(sname))predictionport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREDICT".format(sname))dashboardhtml=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_dashboardhtml".format(sname))vipervizport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERVIZPORT".format(sname))solutionvipervizport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_SOLUTIONVIPERVIZPORT".format(sname))airflowport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_AIRFLOWPORT".format(sname))mqttusername=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_MQTTUSERNAME".format(sname))kafkacloudusername=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_KAFKACLOUDUSERNAME".format(sname))projectname=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_projectname".format(sd))externalport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_EXTERNALPORT".format(sname))solutionexternalport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_SOLUTIONEXTERNALPORT".format(sname))solutionairflowport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_SOLUTIONAIRFLOWPORT".format(sname))hpdehost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEHOST".format(sname))hpdeport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEPORT".format(sname))hpdepredicthost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEHOSTPREDICT".format(sname))hpdepredictport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEPORTPREDICT".format(sname))subprocess.call(["sed","-i","-e","s/--project--/{}/g".format(default_args['conf_project']),"/{}/docs/source/conf.py".format(sname)])subprocess.call(["sed","-i","-e","s/--copyright--/{}/g".format(default_args['conf_copyright']),"/{}/docs/source/conf.py".format(sname)])subprocess.call(["sed","-i","-e","s/--author--/{}/g".format(default_args['conf_author']),"/{}/docs/source/conf.py".format(sname)])subprocess.call(["sed","-i","-e","s/--release--/{}/g".format(default_args['conf_release']),"/{}/docs/source/conf.py".format(sname)])subprocess.call(["sed","-i","-e","s/--version--/{}/g".format(default_args['conf_version']),"/{}/docs/source/conf.py".format(sname)])stitle=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutiontitle".format(sname))sdesc=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_solutiondescription".format(sname))brokerhost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_brokerhost".format(sname))brokerport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_brokerport".format(sname))cloudusername=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_cloudusername".format(sname))cloudpassword=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_cloudpassword".format(sname))subprocess.call(["sed","-i","-e","s/--solutionname--/{}/g".format(sname),"/{}/docs/source/index.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--solutiontitle--/{}/g".format(stitle),"/{}/docs/source/index.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--solutiondescription--/{}/g".format(sdesc),"/{}/docs/source/index.rst".format(sname)])projecturl="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname)doparse("/{}/docs/source/index.rst".format(sname),["--projectname--;{}".format(projectname)])subprocess.call(["sed","-i","-e","s/--solutionname--/{}/g".format(sname),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--sname--/{}/g".format(sname),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--stitle--/{}/g".format(stitle),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--sdesc--/{}/g".format(sdesc),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--brokerhost--/{}/g".format(brokerhost),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--brokerport--/{}/g".format(brokerport[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--cloudusername--/{}/g".format(cloudusername),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--solutiontitle--/{}/g".format(stitle),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--solutiondescription--/{}/g".format(sdesc),"/{}/docs/source/details.rst".format(sname)])companyname=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_companyname".format(sname))myname=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_myname".format(sname))myemail=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_myemail".format(sname))mylocation=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_mylocation".format(sname))replication=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_replication".format(sname))numpartitions=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_numpartitions".format(sname))enabletls=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_enabletls".format(sname))microserviceid=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_microserviceid".format(sname))raw_data_topic=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_raw_data_topic".format(sname))step2raw_data_topic=raw_data_topicpreprocess_data_topic=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_preprocess_data_topic".format(sname))step2preprocess_data_topic=preprocess_data_topicml_data_topic=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_ml_data_topic".format(sname))prediction_data_topic=context['ti'].xcom_pull(task_ids='step_2_solution_task_createtopic',key="{}_prediction_data_topic".format(sname))subprocess.call(["sed","-i","-e","s/--companyname--/{}/g".format(companyname),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--myname--/{}/g".format(myname),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--myemail--/{}/g".format(myemail),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--mylocation--/{}/g".format(mylocation),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--replication--/{}/g".format(replication[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--numpartitions--/{}/g".format(numpartitions[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--enabletls--/{}/g".format(enabletls[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--microserviceid--/{}/g".format(microserviceid),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--raw_data_topic--/{}/g".format(raw_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocess_data_topic--/{}/g".format(preprocess_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--ml_data_topic--/{}/g".format(ml_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--prediction_data_topic--/{}/g".format(prediction_data_topic),"/{}/docs/source/details.rst".format(sname)])PRODUCETYPE=""TOPIC=""PORT=""IDENTIFIER=""HTTPADDR=""FROMHOST=""TOHOST=""CLIENTPORT=""snamertd=sname.replace("_","-")PRODUCETYPE=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_PRODUCETYPE".format(sname))TOPIC=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_TOPIC".format(sname))PORT=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_PORT".format(sname))IDENTIFIER=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_IDENTIFIER".format(sname))HTTPADDR=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_HTTPADDR".format(sname))FROMHOST=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_FROMHOST".format(sname))TOHOST=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_TOHOST".format(sname))CLIENTPORT=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_CLIENTPORT".format(sname))TSSCLIENTPORT=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_TSSCLIENTPORT".format(sname))TMLCLIENTPORT=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_TMLCLIENTPORT".format(sname))setupurls(projectname,PRODUCETYPE,sname)ifPRODUCETYPE=='LOCALFILE':inputfile=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_inputfile".format(sname))step3localfileinputfile=inputfiledocfolderprocess=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_docfolder".format(sname))step3localfiledocfolder=docfolderprocessdoctopic=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_doctopic".format(sname))chunks=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_chunks".format(sname))docingestinterval=context['ti'].xcom_pull(task_ids='step_3_solution_task_producetotopic',key="{}_docingestinterval".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--docfolderprocess--;{}".format(docfolderprocess)])doparse("/{}/docs/source/details.rst".format(sname),["--doctopic--;{}".format(doctopic)])doparse("/{}/docs/source/details.rst".format(sname),["--chunks--;{}".format(chunks[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--docingestinterval--;{}".format(docingestinterval[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--inputfile--;{}".format(inputfile)])subprocess.call(["sed","-i","-e","s/--PRODUCETYPE--/{}/g".format(PRODUCETYPE),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--TOPIC--/{}/g".format(TOPIC),"/{}/docs/source/details.rst".format(sname)])doparse("/{}/docs/source/details.rst".format(sname),["--PORT--;{}".format(PORT[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--HTTPADDR--;{}".format(HTTPADDR)])doparse("/{}/docs/source/details.rst".format(sname),["--FROMHOST--;{}".format(FROMHOST)])doparse("/{}/docs/source/details.rst".format(sname),["--TOHOST--;{}".format(TOHOST)])doparse("/{}/docs/source/details.rst".format(sname),["--datetime--;{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))])doparse("/{}/docs/source/index.rst".format(sname),["--datetime--;{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))])doparse("/{}/docs/source/operating.rst".format(sname),["--datetime--;{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))])doparse("/{}/docs/source/logs.rst".format(sname),["--datetime--;{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))])doparse("/{}/docs/source/kube.rst".format(sname),["--datetime--;{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))])iflen(CLIENTPORT)>1:doparse("/{}/docs/source/details.rst".format(sname),["--CLIENTPORT--;{}".format(CLIENTPORT[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--TSSCLIENTPORT--;{}".format(TSSCLIENTPORT[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--TMLCLIENTPORT--;{}".format(TMLCLIENTPORT[1:])])else:doparse("/{}/docs/source/details.rst".format(sname),["--CLIENTPORT--;Not Applicable"])doparse("/{}/docs/source/details.rst".format(sname),["--TSSCLIENTPORT--;Not Applicable"])doparse("/{}/docs/source/details.rst".format(sname),["--TMLCLIENTPORT--;Not Applicable"])doparse("/{}/docs/source/details.rst".format(sname),["--IDENTIFIER--;{}".format(IDENTIFIER)])subprocess.call(["sed","-i","-e","s/--ingestdatamethod--/{}/g".format(PRODUCETYPE),"/{}/docs/source/details.rst".format(sname)])raw_data_topic=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_raw_data_topic".format(sname))ifraw_data_topic:step4raw_data_topic=raw_data_topicpreprocess_data_topic=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_preprocess_data_topic".format(sname))ifpreprocess_data_topic:step4preprocess_data_topic=preprocess_data_topicpreprocessconditions=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_preprocessconditions".format(sname))delay=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_delay".format(sname))array=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_array".format(sname))saveasarray=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_saveasarray".format(sname))topicid=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_topicid".format(sname))rawdataoutput=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_rawdataoutput".format(sname))asynctimeout=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_asynctimeout".format(sname))timedelay=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_timedelay".format(sname))usemysql=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_usemysql".format(sname))preprocesstypes=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_preprocesstypes".format(sname))ifpreprocesstypes:step4preprocesstypes=preprocesstypespathtotmlattrs=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_pathtotmlattrs".format(sname))identifier=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_identifier".format(sname))jsoncriteria=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_jsoncriteria".format(sname))ifjsoncriteria:step4jsoncriteria=jsoncriteriamaxrows4=context['ti'].xcom_pull(task_ids='step_4_solution_task_preprocess',key="{}_maxrows".format(sname))ifmaxrows4:step4maxrows=maxrows4ifpreprocess_data_topic:subprocess.call(["sed","-i","-e","s/--raw_data_topic--/{}/g".format(raw_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocess_data_topic--/{}/g".format(preprocess_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocessconditions--/{}/g".format(preprocessconditions),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--delay--/{}/g".format(delay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--array--/{}/g".format(array[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--saveasarray--/{}/g".format(saveasarray[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--topicid--/{}/g".format(topicid[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rawdataoutput--/{}/g".format(rawdataoutput[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--asynctimeout--/{}/g".format(asynctimeout[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--timedelay--/{}/g".format(timedelay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocesstypes--/{}/g".format(preprocesstypes),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--pathtotmlattrs--/{}/g".format(pathtotmlattrs),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--identifier--/{}/g".format(identifier),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--jsoncriteria--/{}/g".format(jsoncriteria),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--maxrows--/{}/g".format(maxrows4[1:]),"/{}/docs/source/details.rst".format(sname)])raw_data_topic=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_raw_data_topic".format(sname))ifraw_data_topic:step4araw_data_topic=raw_data_topicpreprocess_data_topic=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_preprocess_data_topic".format(sname))ifpreprocess_data_topic:step4apreprocess_data_topic=preprocess_data_topicpreprocessconditions=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_preprocessconditions".format(sname))delay=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_delay".format(sname))array=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_array".format(sname))saveasarray=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_saveasarray".format(sname))topicid=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_topicid".format(sname))rawdataoutput=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_rawdataoutput".format(sname))asynctimeout=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_asynctimeout".format(sname))timedelay=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_timedelay".format(sname))usemysql=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_usemysql".format(sname))preprocesstypes=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_preprocesstypes".format(sname))ifpreprocesstypes:step4apreprocesstypes=preprocesstypespathtotmlattrs=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_pathtotmlattrs".format(sname))identifier=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_identifier".format(sname))jsoncriteria=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_jsoncriteria".format(sname))ifjsoncriteria:step4ajsoncriteria=jsoncriteriamaxrows4=context['ti'].xcom_pull(task_ids='step_4a_solution_task_preprocess',key="{}_maxrows".format(sname))ifmaxrows4:step4amaxrows=maxrows4ifpreprocess_data_topic:subprocess.call(["sed","-i","-e","s/--raw_data_topic1--/{}/g".format(raw_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocess_data_topic1--/{}/g".format(preprocess_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocessconditions1--/{}/g".format(preprocessconditions),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--delay1--/{}/g".format(delay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--array1--/{}/g".format(array[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--saveasarray1--/{}/g".format(saveasarray[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--topicid1--/{}/g".format(topicid[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rawdataoutput1--/{}/g".format(rawdataoutput[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--asynctimeout1--/{}/g".format(asynctimeout[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--timedelay1--/{}/g".format(timedelay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocesstypes1--/{}/g".format(preprocesstypes),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--pathtotmlattrs1--/{}/g".format(pathtotmlattrs),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--identifier1--/{}/g".format(identifier),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--jsoncriteria1--/{}/g".format(jsoncriteria),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--maxrows1--/{}/g".format(maxrows4[1:]),"/{}/docs/source/details.rst".format(sname)])raw_data_topic=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_raw_data_topic".format(sname))ifraw_data_topic:step4braw_data_topic=raw_data_topicpreprocess_data_topic=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_preprocess_data_topic".format(sname))ifpreprocess_data_topic:step4bpreprocess_data_topic=preprocess_data_topicpreprocessconditions=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_preprocessconditions".format(sname))delay=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_delay".format(sname))array=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_array".format(sname))saveasarray=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_saveasarray".format(sname))topicid=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_topicid".format(sname))rawdataoutput=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_rawdataoutput".format(sname))asynctimeout=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_asynctimeout".format(sname))timedelay=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_timedelay".format(sname))usemysql=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_usemysql".format(sname))preprocesstypes=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_preprocesstypes".format(sname))ifpreprocesstypes:step4bpreprocesstypes=preprocesstypespathtotmlattrs=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_pathtotmlattrs".format(sname))identifier=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_identifier".format(sname))jsoncriteria=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_jsoncriteria".format(sname))ifjsoncriteria:step4bjsoncriteria=jsoncriteriamaxrows4b=context['ti'].xcom_pull(task_ids='step_4b_solution_task_preprocess',key="{}_maxrows".format(sname))ifmaxrows4b:step4bmaxrows=maxrows4bifpreprocess_data_topic:subprocess.call(["sed","-i","-e","s/--raw_data_topic2--/{}/g".format(raw_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocess_data_topic2--/{}/g".format(preprocess_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocessconditions2--/{}/g".format(preprocessconditions),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--delay2--/{}/g".format(delay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--array2--/{}/g".format(array[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--saveasarray2--/{}/g".format(saveasarray[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--topicid2--/{}/g".format(topicid[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rawdataoutput2--/{}/g".format(rawdataoutput[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--asynctimeout2--/{}/g".format(asynctimeout[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--timedelay2--/{}/g".format(timedelay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocesstypes2--/{}/g".format(preprocesstypes),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--pathtotmlattrs2--/{}/g".format(pathtotmlattrs),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--identifier2--/{}/g".format(identifier),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--jsoncriteria2--/{}/g".format(jsoncriteria),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--maxrows2--/{}/g".format(maxrows4b[1:]),"/{}/docs/source/details.rst".format(sname)])raw_data_topic=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_raw_data_topic".format(sname))preprocess_data_topic=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_preprocess_data_topic".format(sname))delay=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_delay".format(sname))array=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_array".format(sname))saveasarray=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_saveasarray".format(sname))topicid=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_topicid".format(sname))rawdataoutput=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_rawdataoutput".format(sname))asynctimeout=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_asynctimeout".format(sname))timedelay=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_timedelay".format(sname))usemysql=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_usemysql".format(sname))searchterms=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_searchterms".format(sname))rememberpastwindows=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_rememberpastwindows".format(sname))identifier=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_identifier".format(sname))patternwindowthreshold=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_patternwindowthreshold".format(sname))maxrows4c=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_maxrows".format(sname))rtmsstream=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_rtmsstream".format(sname))rtmsscorethresholdtopic=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_rtmsscorethresholdtopic".format(sname))attackscorethresholdtopic=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_attackscorethresholdtopic".format(sname))patternscorethresholdtopic=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_patternscorethresholdtopic".format(sname))rtmsscorethreshold=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_rtmsscorethreshold".format(sname))attackscorethreshold=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_attackscorethreshold".format(sname))patternscorethreshold=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_patternscorethreshold".format(sname))rtmsmaxwindows=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_rtmsmaxwindows".format(sname))ifrtmsmaxwindows:step4crtmsmaxwindows=rtmsmaxwindowssubprocess.call(["sed","-i","-e","s/--rtmsmaxwindows--/{}/g".format(rtmsmaxwindows[1:]),"/{}/docs/source/details.rst".format(sname)])localsearchtermfolder=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_localsearchtermfolder".format(sname))localsearchtermfolderinterval=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_localsearchtermfolderinterval".format(sname))rtmsfoldername=context['ti'].xcom_pull(task_ids='step_4c_solution_task_preprocess',key="{}_rtmsfoldername".format(sname))ifsearchterms:doparse("/{}/docs/source/details.rst".format(sname),["--rtmsscorethresholdtopic--;{}".format(rtmsscorethresholdtopic)])doparse("/{}/docs/source/details.rst".format(sname),["--attackscorethresholdtopic--;{}".format(attackscorethresholdtopic)])doparse("/{}/docs/source/details.rst".format(sname),["--patternscorethresholdtopic--;{}".format(patternscorethresholdtopic)])doparse("/{}/docs/source/details.rst".format(sname),["--rtmsfoldername--;{}".format(rtmsfoldername)])doparse("/{}/docs/source/details.rst".format(sname),["--rtmsscorethreshold--;{}".format(rtmsscorethreshold[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--attackscorethreshold--;{}".format(attackscorethreshold[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--patternscorethreshold--;{}".format(patternscorethreshold[1:])])subprocess.call(["sed","-i","-e","s/--raw_data_topic3--/{}/g".format(raw_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--preprocess_data_topic3--/{}/g".format(preprocess_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rtmsstream--/{}/g".format(rtmsstream),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--delay3--/{}/g".format(delay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--array3--/{}/g".format(array[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--saveasarray3--/{}/g".format(saveasarray[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--topicid3--/{}/g".format(topicid[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rawdataoutput3--/{}/g".format(rawdataoutput[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--asynctimeout3--/{}/g".format(asynctimeout[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--timedelay3--/{}/g".format(timedelay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rememberpastwindows--/{}/g".format(rememberpastwindows[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--patternwindowthreshold--/{}/g".format(patternwindowthreshold[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--identifier3--/{}/g".format(identifier),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--maxrows3--/{}/g".format(maxrows4c[1:]),"/{}/docs/source/details.rst".format(sname)])doparse("/{}/docs/source/details.rst".format(sname),["--rtmssearchterms--;{}".format(searchterms)])rtmsoutputurl="https:\/\/github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/{}".format(os.environ["GITUSERNAME"],tsslogging.getrepo(),projectname,rtmsfoldername)doparse("/{}/docs/source/details.rst".format(sname),["--rtmsoutputurl--;{}".format(rtmsoutputurl)])doparse("/{}/docs/source/details.rst".format(sname),["--localsearchtermfolder--;{}".format(localsearchtermfolder)])doparse("/{}/docs/source/details.rst".format(sname),["--localsearchtermfolderinterval--;{}".format(localsearchtermfolderinterval[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--rtmsfoldername--;{}".format(rtmsfoldername)])step4crawdatatopic=raw_data_topicstep4csearchterms=searchtermsstep4crememberpastwindows=rememberpastwindowsstep4cpatternwindowthreshold=patternwindowthresholdstep4crtmsstream=rtmsstreamstep4crtmsscorethreshold=rtmsscorethresholdstep4cattackscorethreshold=attackscorethresholdstep4cpatternscorethreshold=patternscorethresholdstep4clocalsearchtermfolder=localsearchtermfolderstep4clocalsearchtermfolderinterval=localsearchtermfolderintervalstep4crtmsfoldername=rtmsfoldernamepreprocess_data_topic=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_preprocess_data_topic".format(sname))ml_data_topic=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_ml_data_topic".format(sname))modelruns=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_modelruns".format(sname))offset=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_offset".format(sname))islogistic=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_islogistic".format(sname))networktimeout=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_networktimeout".format(sname))modelsearchtuner=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_modelsearchtuner".format(sname))dependentvariable=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_dependentvariable".format(sname))independentvariables=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_independentvariables".format(sname))ifindependentvariables:step5independentvariables=independentvariablesrollbackoffsets=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_rollbackoffsets".format(sname))topicid=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_topicid".format(sname))consumefrom=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_consumefrom".format(sname))fullpathtotrainingdata=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_fullpathtotrainingdata".format(sname))transformtype=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_transformtype".format(sname))sendcoefto=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_sendcoefto".format(sname))coeftoprocess=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_coeftoprocess".format(sname))coefsubtopicnames=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_coefsubtopicnames".format(sname))processlogic=context['ti'].xcom_pull(task_ids='step_5_solution_task_ml',key="{}_processlogic".format(sname))iffullpathtotrainingdata:step5sp=fullpathtotrainingdata.split("/")iflen(step5sp)>0:mloutputurl="https:\/\/github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/mldata/{}".format(os.environ["GITUSERNAME"],tsslogging.getrepo(),projectname,step5sp[-1])doparse("/{}/docs/source/details.rst".format(sname),["--mloutputurl--;{}".format(mloutputurl)])ifprocesslogic:step5processlogic=processlogicifmodelruns:subprocess.call(["sed","-i","-e","s/--preprocess_data_topic--/{}/g".format(preprocess_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--ml_data_topic--/{}/g".format(ml_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--modelruns--/{}/g".format(modelruns[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--offset--/{}/g".format(offset[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--islogistic--/{}/g".format(islogistic[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--networktimeout--/{}/g".format(networktimeout[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--modelsearchtuner--/{}/g".format(modelsearchtuner[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--dependentvariable--/{}/g".format(dependentvariable),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--independentvariables--/{}/g".format(independentvariables),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rollbackoffsets--/{}/g".format(rollbackoffsets[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--topicid--/{}/g".format(topicid[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--consumefrom--/{}/g".format(consumefrom),"/{}/docs/source/details.rst".format(sname)])doparse("/{}/docs/source/details.rst".format(sname),["--fullpathtotrainingdata--;{}".format(fullpathtotrainingdata)])doparse("/{}/docs/source/details.rst".format(sname),["--processlogic--;{}".format(processlogic)])subprocess.call(["sed","-i","-e","s/--transformtype--/{}/g".format(transformtype),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--sendcoefto--/{}/g".format(sendcoefto),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--coeftoprocess--/{}/g".format(coeftoprocess),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--coefsubtopicnames--/{}/g".format(coefsubtopicnames),"/{}/docs/source/details.rst".format(sname)])preprocess_data_topic=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_preprocess_data_topic".format(sname))ml_prediction_topic=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_ml_prediction_topic".format(sname))streamstojoin=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_streamstojoin".format(sname))inputdata=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_inputdata".format(sname))consumefrom2=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_consumefrom".format(sname))offset=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_offset".format(sname))delay=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_delay".format(sname))usedeploy=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_usedeploy".format(sname))networktimeout=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_networktimeout".format(sname))maxrows=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_maxrows".format(sname))topicid=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_topicid".format(sname))pathtoalgos=context['ti'].xcom_pull(task_ids='step_6_solution_task_prediction',key="{}_pathtoalgos".format(sname))ifml_prediction_topic:subprocess.call(["sed","-i","-e","s/--preprocess_data_topic--/{}/g".format(preprocess_data_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--ml_prediction_topic--/{}/g".format(ml_prediction_topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--streamstojoin--/{}/g".format(streamstojoin),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--inputdata--/{}/g".format(inputdata),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--consumefrom2--/{}/g".format(consumefrom2),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--offset--/{}/g".format(offset[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--delay--/{}/g".format(delay[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--usedeploy--/{}/g".format(usedeploy[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--networktimeout--/{}/g".format(networktimeout[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--maxrows--/{}/g".format(maxrows[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--topicid--/{}/g".format(topicid[1:]),"/{}/docs/source/details.rst".format(sname)])doparse("/{}/docs/source/details.rst".format(sname),["--pathtoalgos--;{}".format(pathtoalgos)])topic=context['ti'].xcom_pull(task_ids='step_7_solution_task_visualization',key="{}_topic".format(sname))secure=context['ti'].xcom_pull(task_ids='step_7_solution_task_visualization',key="{}_secure".format(sname))offset=context['ti'].xcom_pull(task_ids='step_7_solution_task_visualization',key="{}_offset".format(sname))append=context['ti'].xcom_pull(task_ids='step_7_solution_task_visualization',key="{}_append".format(sname))chip=context['ti'].xcom_pull(task_ids='step_7_solution_task_visualization',key="{}_chip".format(sname))rollbackoffset=context['ti'].xcom_pull(task_ids='step_7_solution_task_visualization',key="{}_rollbackoffset".format(sname))dashboardhtml=context['ti'].xcom_pull(task_ids='step_7_solution_task_visualization',key="{}_dashboardhtml".format(sname))containername=context['ti'].xcom_pull(task_ids='step_8_solution_task_containerize',key="{}_containername".format(sname))ifcontainername:hcname=containername.split('/')[1]huser=containername.split('/')[0]hurl="https://hub.docker.com/r/{}/{}".format(huser,hcname)else:containername="TBD"ifvipervizport:subprocess.call(["sed","-i","-e","s/--vipervizport--/{}/g".format(vipervizport[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--topic--/{}/g".format(topic),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--dashboardhtml--/{}/g".format(dashboardhtml),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--secure--/{}/g".format(secure[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--offset--/{}/g".format(offset[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--append--/{}/g".format(append[1:]),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--chip--/{}/g".format(chip),"/{}/docs/source/details.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--rollbackoffset--/{}/g".format(rollbackoffset[1:]),"/{}/docs/source/details.rst".format(sname)])repo=tsslogging.getrepo()gitrepo="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}".format(os.environ['GITUSERNAME'],repo,projectname)# gitrepo = "\/{}\/tml-airflow\/dags\/tml-solutions\/{}".format(repo,sname)v=subprocess.call(["sed","-i","-e","s/--gitrepo--/{}/g".format(gitrepo),"/{}/docs/source/operating.rst".format(sname)])print("V=",v)doparse("/{}/docs/source/operating.rst".format(sname),["--gitrepo--;{}".format(gitrepo)])subprocess.call(["sed","-i","-e","s/--solutionname--/{}/g".format(sname),"/{}/docs/source/operating.rst".format(sname)])subprocess.call(["sed","-i","-e","s/--dockercontainer--/{}\n\n{}/g".format(containername,hurl),"/{}/docs/source/operating.rst".format(sname)])chipmain=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_chip".format(sname))doparse("/{}/docs/source/operating.rst".format(sname),["--justcontainer--;{}".format(containername)])doparse("/{}/docs/source/operating.rst".format(sname),["--tsscontainer--;maadsdocker/tml-solution-studio-with-airflow-{}".format(chip)])doparse("/{}/docs/source/operating.rst".format(sname),["--chip--;{}".format(chipmain)])ifistss1==0:doparse("/{}/docs/source/operating.rst".format(sname),["--solutionairflowport--;{}".format(solutionairflowport[1:])])else:doparse("/{}/docs/source/operating.rst".format(sname),["--solutionairflowport--;{}".format("TBD")])doparse("/{}/docs/source/operating.rst".format(sname),["--externalport--;{}".format(externalport[1:])])ifistss1==0:doparse("/{}/docs/source/operating.rst".format(sname),["--solutionexternalport--;{}".format(solutionexternalport[1:])])else:doparse("/{}/docs/source/operating.rst".format(sname),["--solutionexternalport--;{}".format("TBD")])pconsumefrom=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_consumefrom".format(sname))pgpt_data_topic=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_pgpt_data_topic".format(sname))pgptcontainername=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_pgptcontainername".format(sname))pmainmodel=""pmainembedding=""ifpgptcontainername!=None:step9pgptcontainername=pgptcontainernamedoparse("/{}/docs/source/kube.rst".format(sname),["--kubeprivategpt--;{}".format(pgptcontainername)])mainmodel=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_mainmodel".format(sname))pmainmodel=mainmodelmainembedding=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_mainembedding".format(sname))pmainembedding=mainembeddingdoparse("/{}/docs/source/kube.rst".format(sname),["--kubemainmodel--;{}".format(mainmodel)])doparse("/{}/docs/source/kube.rst".format(sname),["--kubemainembedding--;{}".format(mainembedding)])poffset=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_offset".format(sname))prollbackoffset=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_rollbackoffset".format(sname))ptopicid=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_topicid".format(sname))penabletls=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_enabletls".format(sname))ppartition=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_partition".format(sname))pprompt=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_prompt".format(sname))pcontextwindowsize=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_contextwindowsize".format(sname))pvectordimension=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_vectordimension".format(sname))pmitrejson=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_mitrejson".format(sname))ifpmitrejson:doparse("/{}/docs/source/details.rst".format(sname),["--mitrejson--;{}".format(pmitrejson)])ifpcontextwindowsize:step9pcontextwindowsize=pcontextwindowsizedoparse("/{}/docs/source/details.rst".format(sname),["--contextwindowsize--;{}".format(pcontextwindowsize[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--kubecontextwindowsize--;{}".format(pcontextwindowsize[1:])])ifpvectordimension:step9vectordimension=pvectordimensiondoparse("/{}/docs/source/details.rst".format(sname),["--vectordimension--;{}".format(pvectordimension[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--kubevectordimension--;{}".format(pvectordimension[1:])])ifpprompt:step9prompt=ppromptstep9prompt=step9prompt.strip().replace('\n','').replace("\\n","").replace(";",",").replace("''","")pdocfolder=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_docfolder".format(sname))ifpdocfolder:step9docfolder=pdocfolderdoparse("/{}/docs/source/details.rst".format(sname),["--docfolder--;{}".format(pdocfolder)])pdocfolderingestinterval=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_docfolderingestinterval".format(sname))ifpdocfolderingestinterval:step9docfolderingestinterval=pdocfolderingestintervaldoparse("/{}/docs/source/details.rst".format(sname),["--docfolderingestinterval--;{}".format(pdocfolderingestinterval[1:])])puseidentifierinprompt=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_useidentifierinprompt".format(sname))ifpuseidentifierinprompt:step9useidentifierinprompt=puseidentifierinpromptdoparse("/{}/docs/source/details.rst".format(sname),["--useidentifierinprompt--;{}".format(puseidentifierinprompt[1:])])pcontext=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_context".format(sname))ifpcontext:step9context=pcontextpjsonkeytogather=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_jsonkeytogather".format(sname))pkeyattribute=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_keyattribute".format(sname))ifpkeyattribute:step9keyattribute=pkeyattributepconcurrency=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_concurrency".format(sname))ifpconcurrency:step9concurrency=pconcurrencydoparse("/{}/docs/source/kube.rst".format(sname),["--kubeconcur--;{}".format(pconcurrency[1:])])pcuda=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_cuda".format(sname))ifpcuda:cudavisibledevices=pcudapcollection=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_vectordbcollectionname".format(sname))ifpcollection:step9vectordbcollectionname=pcollectiondoparse("/{}/docs/source/kube.rst".format(sname),["--kubecollection--;{}".format(pcollection)])pgpthost=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_pgpthost".format(sname))ifpgpthost:step9pgpthost=pgpthostpgptport=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_pgptport".format(sname))ifpgptport:step9pgptport=pgptportpprocesstype=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_keyprocesstype".format(sname))ifpprocesstype:step9keyprocesstype=pprocesstypehyperbatch=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_hyperbatch".format(sname))ifhyperbatch:step9hyperbatch=hyperbatchpsearchterms=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_searchterms".format(sname))ifpsearchterms:step9searchterms=psearchtermsdoparse("/{}/docs/source/details.rst".format(sname),["--searchterms--;{}".format(psearchterms)])pstreamall=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_streamall".format(sname))ifpstreamall:step9streamall=pstreamalldoparse("/{}/docs/source/details.rst".format(sname),["--streamall--;{}".format(pstreamall[1:])])ptemperature=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_temperature".format(sname))ifptemperature:step9temperature=ptemperaturedoparse("/{}/docs/source/details.rst".format(sname),["--temperature--;{}".format(ptemperature[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--kubetemperature--;{}".format(ptemperature[1:])])pvectorsearchtype=context['ti'].xcom_pull(task_ids='step_9_solution_task_ai',key="{}_vectorsearchtype".format(sname))ifpvectorsearchtype:step9vectorsearchtype=pvectorsearchtypedoparse("/{}/docs/source/details.rst".format(sname),["--vectorsearchtype--;{}".format(pvectorsearchtype)])doparse("/{}/docs/source/kube.rst".format(sname),["--kubevectorsearchtype--;{}".format(pvectorsearchtype)])ollama=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_ollama-model".format(sname))ifollama!=None:# Step 9b executingstep9bollama=ollamadoparse("/{}/docs/source/details.rst".format(sname),["--agenticai-ollama-model--;{}".format(ollama)])rollback=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_rollbackoffset".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-rollbackoffset--;{}".format(rollback[1:])])step9brollback=rollback[1:]deletevector=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_deletevectordbcount".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-deletevectordbcount--;{}".format(deletevector[1:])])step9bdeletevectordbcount=deletevector[1:]vectordbpath=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_vectordbpath".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-vectordbpath--;{}".format(vectordbpath)])step9bvectordbpath=vectordbpathtemp=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_temperature".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-temperature--;{}".format(temp[1:])])step9btemperature=temp[1:]topicid=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_topicid".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-topicid--;{}".format(topicid[1:])])step9btopicid=topicid[1:]enabletls=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_enabletls".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-enabletls--;{}".format(enabletls[1:])])step9benabletls=enabletls[1:]partition=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_partition".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-partition--;{}".format(partition[1:])])step9bpartition=partition[1:]collection=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_vectordbcollectionname".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-vectordbcollectionname--;{}".format(collection)])step9bvectordbcollectionname=collectionollamacontainername=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_ollamacontainername".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-ollamacontainername--;{}".format(ollamacontainername)])step9bollamacontainername=ollamacontainernamemainip=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_mainip".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-mainip--;{}".format(mainip)])step9bmainip=mainipmainport=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_mainport".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-mainport--;{}".format(mainport[1:])])step9bmainport=mainport[1:]embedding=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_embedding".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-embedding--;{}".format(embedding)])step9bembedding=embeddingagents_topic_prompt=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_agents_topic_prompt".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-agents_topic_prompt--;{}".format(agents_topic_prompt)])step9bagents_topic_prompt=agents_topic_promptteamlead_topic=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_teamlead_topic".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-teamlead_topic--;{}".format(teamlead_topic)])step9bteamlead_topic=teamlead_topicteamleadprompt=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_teamleadprompt".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-teamleadprompt--;{}".format(teamleadprompt)])step9bteamleadprompt=teamleadpromptstep9bteamleadprompt=step9bteamleadprompt.replace('\n',' ').replace("\\n","").strip().replace(";",",").replace("''","")supervisor_topic=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_supervisor_topic".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-supervisor_topic--;{}".format(supervisor_topic)])step9bsupervisor_topic=supervisor_topicsupervisorprompt=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_supervisorprompt".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-supervisorprompt--;{}".format(supervisorprompt)])step9bsupervisorprompt=supervisorpromptstep9bsupervisorprompt=step9bsupervisorprompt.replace('\n','').replace("\\n","").strip().replace(";",",").replace("''","")agenttoolfunctions=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_agenttoolfunctions".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-agenttoolfunctions--;{}".format(agenttoolfunctions)])step9bagenttoolfunctions=agenttoolfunctionsstep9bagenttoolfunctions=step9bagenttoolfunctions.replace('\n','').replace("\\n","").strip().replace(";",",").replace("''","")agent_team_supervisor_topic=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_agent_team_supervisor_topic".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-agent_team_supervisor_topic--;{}".format(agent_team_supervisor_topic)])step9bagent_team_supervisor_topic=agent_team_supervisor_topicagenttopic=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_agenttopic".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-agenttopic--;{}".format(agenttopic)])step9bagenttopic=agenttopiclocalmodelsfolder=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_localmodelsfolder".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-localmodelsfolder--;{}".format(localmodelsfolder)])step9blocalmodelsfolder=localmodelsfolderconcurrency=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_concurrency".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-concurrency--;{}".format(concurrency[1:])])step9bconcurrency=concurrency[1:]cuda=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_cuda".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-cuda--;{}".format(cuda[1:])])step9bCUDA_VISIBLE_DEVICES=cuda[1:]contextwindow=context['ti'].xcom_pull(task_ids='step_9b_solution_task_agenticai',key="{}_contextwindow".format(sname))doparse("/{}/docs/source/details.rst".format(sname),["--agenticai-contextwindow--;{}".format(contextwindow[1:])])step9bcontextwindow=contextwindow[1:]doparse("/{}/docs/source/kube.rst".format(sname),["--ollamacontainername--;{}".format(ollamacontainername)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-kubeconcur--;{}".format(concurrency[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-kubecollection--;{}".format(collection)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-kubetemperature--;{}".format(temp[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-rollbackoffset--;{}".format(rollback[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-ollama-model--;{}".format(ollama)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-deletevectordbcount--;{}".format(deletevector[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-vectordbpath--;{}".format(vectordbpath)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-topicid--;{}".format(topicid[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-enabletls--;{}".format(enabletls[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-partition--;{}".format(partition[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-vectordbcollectionname--;{}".format(collection)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-ollamacontainername--;{}".format(ollamacontainername)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-mainip--;{}".format(mainip)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-mainport--;{}".format(mainport[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-contextwindow--;{}".format(contextwindow[1:])])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-agenttopic--;{}".format(agenttopic)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-localmodelsfolder--;{}".format(localmodelsfolder)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-embedding--;{}".format(embedding)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-agents_topic_prompt--;{}".format(agents_topic_prompt.strip().replace('\n','').replace("\\n","").replace("'","").replace(";",","))])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-teamlead_topic--;{}".format(teamlead_topic)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-teamleadprompt--;{}".format(teamleadprompt.strip().replace('\n','').replace("\\n","").replace("'","").replace(";",","))])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-supervisor_topic--;{}".format(supervisor_topic)])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-supervisorprompt--;{}".format(supervisorprompt.strip().replace('\n','').replace("\\n","").replace("'","").replace(";",","))])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-agenttoolfunctions--;{}".format(agenttoolfunctions.strip().replace('\n','').replace("\\n","").replace("'","").replace(";","=="))])doparse("/{}/docs/source/kube.rst".format(sname),["--agenticai-agent_team_supervisor_topic--;{}".format(agent_team_supervisor_topic)])ebuf=""if'dockerenv'indefault_args:ifdefault_args['dockerenv']!='':buf=default_args['dockerenv']darr=buf.split("***")ebuf="\n"fordindarr:v=d.split("=")iflen(v)>1:if'jsoncriteria'inv[0].strip():d=d[d.index("=")+1:]ebuf=ebuf+' --env '+v[0].strip()+'=\"'+d+'\"\\\n'else:ebuf=ebuf+' --env '+v[0].strip()+'=\"'+v[1].strip()+'\"\\\n'else:ebuf=ebuf+' --env '+v[0].strip()+'='+' \\\n'ebuf=ebuf[:-1]ifdefault_args['dockerinstructions']!='':doparse("/{}/docs/source/operating.rst".format(sname),["--dockerinstructions--;{}".format(default_args['dockerinstructions'])])else:doparse("/{}/docs/source/operating.rst".format(sname),["--dockerinstructions--;{}".format("Please ask the developer of this solution.")])iflen(CLIENTPORT)>1:doparse("/{}/docs/source/operating.rst".format(sname),["--clientport--;{}".format(TMLCLIENTPORT[1:])])dockerrun="""docker run -d --net=host -p {}:{} -p {}:{} -p {}:{} -p {}:{}\\ --env TSS=0 \\ --env SOLUTIONNAME={}\\ --env SOLUTIONDAG={}\\ --env GITUSERNAME=<Enter Github Username> \\ --env GITPASSWORD='<Enter Github Password>' \\ --env GITREPOURL=<Enter Github Repo URL> \\ --env SOLUTIONEXTERNALPORT={}\\ -v /var/run/docker.sock:/var/run/docker.sock:z \\ -v /your_localmachine/foldername:/rawdata:z \\ --env CHIP={}\\ --env SOLUTIONAIRFLOWPORT={}\\ --env SOLUTIONVIPERVIZPORT={}\\ --env DOCKERUSERNAME='' \\ --env CLIENTPORT={}\\ --env EXTERNALPORT={}\\ --env KAFKABROKERHOST=127.0.0.1:9092 \\ --env KAFKACLOUDUSERNAME='<Enter API key>' \\ --env KAFKACLOUDPASSWORD='<Enter API secret>' \\ --env SASLMECHANISM=PLAIN \\ --env VIPERVIZPORT={}\\ --env MQTTUSERNAME='' \\ --env MQTTPASSWORD='' \\ --env AIRFLOWPORT={}\\ --env READTHEDOCS='<Enter Readthedocs token>' \\{}{}""".format(solutionexternalport[1:],solutionexternalport[1:],solutionairflowport[1:],solutionairflowport[1:],solutionvipervizport[1:],solutionvipervizport[1:],TMLCLIENTPORT[1:],TMLCLIENTPORT[1:],sname,sd,solutionexternalport[1:],chipmain,solutionairflowport[1:],solutionvipervizport[1:],TMLCLIENTPORT[1:],externalport[1:],vipervizport[1:],airflowport[1:],ebuf,containername)else:doparse("/{}/docs/source/operating.rst".format(sname),["--clientport--;Not Applicable"])dockerrun="""docker run -d --net=host -p {}:{} -p {}:{} -p {}:{}\\ --env TSS=0 \\ --env SOLUTIONNAME={}\\ --env SOLUTIONDAG={}\\ --env GITUSERNAME=<Enter Github Username> \\ --env GITPASSWORD='<Enter Github Password>' \\ --env GITREPOURL=<Enter Github Repo URL> \\ --env SOLUTIONEXTERNALPORT={}\\ -v /var/run/docker.sock:/var/run/docker.sock:z \\ -v /your_localmachine/foldername:/rawdata:z \\ --env CHIP={}\\ --env SOLUTIONAIRFLOWPORT={}\\ --env SOLUTIONVIPERVIZPORT={}\\ --env DOCKERUSERNAME='' \\ --env EXTERNALPORT={}\\ --env KAFKABROKERHOST=127.0.0.1:9092 \\ --env KAFKACLOUDUSERNAME='<Enter API key>' \\ --env KAFKACLOUDPASSWORD='<Enter API secret>' \\ --env SASLMECHANISM=PLAIN \\ --env VIPERVIZPORT={}\\ --env MQTTUSERNAME='' \\ --env MQTTPASSWORD='' \\ --env AIRFLOWPORT={}\\ --env READTHEDOCS='<Enter Readthedocs token>' \\{}{}""".format(solutionexternalport[1:],solutionexternalport[1:],solutionairflowport[1:],solutionairflowport[1:],solutionvipervizport[1:],solutionvipervizport[1:],sname,sd,solutionexternalport[1:],chipmain,solutionairflowport[1:],solutionvipervizport[1:],externalport[1:],vipervizport[1:],airflowport[1:],ebuf,containername)# dockerrun = re.escape(dockerrun)v=subprocess.call(["sed","-i","-e","s/--dockerrun--/{}/g".format(dockerrun),"/{}/docs/source/operating.rst".format(sname)])ifistss1==1:doparse("/{}/docs/source/operating.rst".format(sname),["--dockerrun--;{}".format(dockerrun),"--dockercontainer--;{} ({})".format(containername,hurl)])doparse("/{}/docs/source/details.rst".format(sname),["--dockerrun--;{}".format(dockerrun),"--dockercontainer--;{} ({})".format(containername,hurl)])else:try:withopen("/tmux/step1solutionold.txt","r")asf:msname=f.read()mbuf="Refer to the original solution container and documenation here: https://{}.readthedocs.io/en/latest/operating.html".format(msname.strip())doparse("/{}/docs/source/operating.rst".format(sname),["--dockerrun--;{}".format(dockerrun),"--dockercontainer--;{}".format(mbuf)])exceptExceptionase:passstep9rollbackoffset=-1step9llmmodel=''step9embedding=''step9vectorsize=''ifpgptcontainername!=None:ifos.environ['TSS']=="1":privategptrun="docker run -d -p {}:{} --net=host --gpus all -v /var/run/docker.sock:/var/run/docker.sock:z --env PORT={} --env TSS=1 --env GPU=1 --env COLLECTION={} --env WEB_CONCURRENCY={} --env CUDA_VISIBLE_DEVICES={} --env TOKENIZERS_PARALLELISM=false --env temperature={} --env vectorsearchtype=\"{}\" --env contextwindowsize={} --env vectordimension={}{}".format(pgptport[1:],pgptport[1:],pgptport[1:],pcollection,pconcurrency[1:],pcuda[1:],ptemperature[1:],pvectorsearchtype,pcontextwindowsize[1:],pvectordimension[1:],pgptcontainername)else:privategptrun="docker run -d -p {}:{} --net=host --gpus all -v /var/run/docker.sock:/var/run/docker.sock:z --env PORT={} --env TSS=0 --env GPU=1 --env COLLECTION={} --env WEB_CONCURRENCY={} --env CUDA_VISIBLE_DEVICES={} --env TOKENIZERS_PARALLELISM=false --env temperature={} --env vectorsearchtype=\"{}\" --env contextwindowsize={} --env vectordimension={}{}".format(pgptport[1:],pgptport[1:],pgptport[1:],pcollection,pconcurrency[1:],pcuda[1:],ptemperature[1:],pvectorsearchtype,pcontextwindowsize[1:],pvectordimension[1:],pgptcontainername)step9llmmodel='Refer to: https://tml.readthedocs.io/en/latest/genai.html'step9embedding='Refer to: https://tml.readthedocs.io/en/latest/genai.html'step9vectorsize='Refer to: https://tml.readthedocs.io/en/latest/genai.html'doparse("/{}/docs/source/details.rst".format(sname),["--llmmodel--;{}".format(step9llmmodel)])doparse("/{}/docs/source/details.rst".format(sname),["--embedding--;{}".format(step9embedding)])doparse("/{}/docs/source/details.rst".format(sname),["--vectorsize--;{}".format(step9vectorsize)])doparse("/{}/docs/source/details.rst".format(sname),["--pgptcontainername--;{}".format(pgptcontainername),"--privategptrun--;{}".format(privategptrun)])qdrantcontainer="qdrant/qdrant"qdrantrun="docker run -d -p 6333:6333 -v $(pwd)/qdrant_storage:/qdrant/storage:z qdrant/qdrant"doparse("/{}/docs/source/details.rst".format(sname),["--qdrantcontainer--;{}".format(qdrantcontainer),"--qdrantrun--;{}".format(qdrantrun)])doparse("/{}/docs/source/details.rst".format(sname),["--consumefrom--;{}".format(pconsumefrom)])doparse("/{}/docs/source/details.rst".format(sname),["--pgpt_data_topic--;{}".format(pgpt_data_topic)])doparse("/{}/docs/source/details.rst".format(sname),["--vectordbcollectionname--;{}".format(pcollection)])doparse("/{}/docs/source/details.rst".format(sname),["--offset--;{}".format(poffset[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--rollbackoffset--;{}".format(prollbackoffset[1:])])step9rollbackoffset=prollbackoffset[1:]doparse("/{}/docs/source/details.rst".format(sname),["--topicid--;{}".format(ptopicid[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--enabletls--;{}".format(penabletls[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--partition--;{}".format(ppartition[1:])])pprompt=pprompt.replace("\\n"," ")doparse("/{}/docs/source/details.rst".format(sname),["--prompt--;{}".format(pprompt)])doparse("/{}/docs/source/details.rst".format(sname),["--context--;{}".format(pcontext)])doparse("/{}/docs/source/details.rst".format(sname),["--jsonkeytogather--;{}".format(pjsonkeytogather)])doparse("/{}/docs/source/details.rst".format(sname),["--keyattribute--;{}".format(pkeyattribute)])doparse("/{}/docs/source/details.rst".format(sname),["--concurrency--;{}".format(pconcurrency[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--cuda--;{}".format(pcuda[1:])])ifkube==1:doparse("/{}/docs/source/details.rst".format(sname),["--pgpthost--;{}".format('privategpt-service')])else:doparse("/{}/docs/source/details.rst".format(sname),["--pgpthost--;{}".format(pgpthost)])doparse("/{}/docs/source/details.rst".format(sname),["--pgptport--;{}".format(pgptport[1:])])doparse("/{}/docs/source/details.rst".format(sname),["--keyprocesstype--;{}".format(pprocesstype)])doparse("/{}/docs/source/details.rst".format(sname),["--hyperbatch--;{}".format(hyperbatch[1:])])snamerp=sname.replace("_","-")rbuf="https://{}.readthedocs.io".format(snamerp)doparse("/{}/docs/source/details.rst".format(sname),["--readthedocs--;{}".format(rbuf)])############# VIZ URLSvizurl="http:\/\/localhost:{}\/{}?topic={}\&offset={}\&groupid=\&rollbackoffset={}\&topictype=prediction\&append={}\&secure={}".format(solutionvipervizport[1:],dashboardhtml,topic,offset[1:],rollbackoffset[1:],append[1:],secure[1:])vizurlkube="http://localhost:{}/{}?topic={}&offset={}&groupid=&rollbackoffset={}&topictype=prediction&append={}&secure={}".format(solutionvipervizport[1:],dashboardhtml,topic,offset[1:],rollbackoffset[1:],append[1:],secure[1:])if'gRPC'inPRODUCETYPE:vizurlkubeing="http://tml.tss2/viz/{}?topic={}&offset={}&groupid=&rollbackoffset={}&topictype=prediction&append={}&secure={}".format(dashboardhtml,topic,offset[1:],rollbackoffset[1:],append[1:],secure[1:])else:vizurlkubeing="http://tml.tss/viz/{}?topic={}&offset={}&groupid=&rollbackoffset={}&topictype=prediction&append={}&secure={}".format(dashboardhtml,topic,offset[1:],rollbackoffset[1:],append[1:],secure[1:])ifistss1==0:subprocess.call(["sed","-i","-e","s/--visualizationurl--/{}/g".format(vizurl),"/{}/docs/source/operating.rst".format(sname)])else:subprocess.call(["sed","-i","-e","s/--visualizationurl--/{}/g".format("This will appear AFTER you run Your Solution Docker Container"),"/{}/docs/source/operating.rst".format(sname)])tssvizurl="http:\/\/localhost:{}\/{}?topic={}\&offset={}\&groupid=\&rollbackoffset={}\&topictype=prediction\&append={}\&secure={}".format(vipervizport[1:],dashboardhtml,topic,offset[1:],rollbackoffset[1:],append[1:],secure[1:])subprocess.call(["sed","-i","-e","s/--tssvisualizationurl--/{}/g".format(tssvizurl),"/{}/docs/source/operating.rst".format(sname)])tsslogfile="http:\/\/localhost:{}\/viperlogs.html?topic=viperlogs\&append=0".format(vipervizport[1:])subprocess.call(["sed","-i","-e","s/--tsslogfile--/{}/g".format(tsslogfile),"/{}/docs/source/operating.rst".format(sname)])solutionlogfile="http:\/\/localhost:{}\/viperlogs.html?topic=viperlogs\&append=0".format(solutionvipervizport[1:])ifistss1==0:subprocess.call(["sed","-i","-e","s/--solutionlogfile--/{}/g".format(solutionlogfile),"/{}/docs/source/operating.rst".format(sname)])else:subprocess.call(["sed","-i","-e","s/--solutionlogfile--/{}/g".format("This will appear AFTER you run Your Solution Docker Container"),"/{}/docs/source/operating.rst".format(sname)])githublogs="https:\/\/github.com\/{}\/{}\/blob\/main\/tml-airflow\/logs\/logs.txt".format(os.environ['GITUSERNAME'],repo)subprocess.call(["sed","-i","-e","s/--githublogs--/{}/g".format(githublogs),"/{}/docs/source/operating.rst".format(sname)])#-----------------------subprocess.call(["sed","-i","-e","s/--githublogs--/{}/g".format(githublogs),"/{}/docs/source/logs.rst".format(sname)])tsslogging.locallogs("INFO","STEP 10: Documentation successfully built on GitHub..Readthedocs build in process and should complete in few seconds")try:sf=""withopen('/dagslocalbackup/logs.txt',"r")asf:sf=f.read()doparse("/{}/docs/source/logs.rst".format(sname),["--logs--;{}".format(sf)])exceptExceptionase:print("Cannot open file - ",e)pass#-------------------airflowurl="http:\/\/localhost:{}".format(airflowport[1:])subprocess.call(["sed","-i","-e","s/--airflowurl--/{}/g".format(airflowurl),"/{}/docs/source/operating.rst".format(sname)])readthedocs="https:\/\/{}.readthedocs.io".format(sname)subprocess.call(["sed","-i","-e","s/--readthedocs--/{}/g".format(readthedocs),"/{}/docs/source/operating.rst".format(sname)])triggername=sdprint("triggername=",triggername)doparse("/{}/docs/source/operating.rst".format(sname),["--triggername--;{}".format(sd)])doparse("/{}/docs/source/operating.rst".format(sname),["--airflowport--;{}".format(airflowport[1:])])doparse("/{}/docs/source/operating.rst".format(sname),["--vipervizport--;{}".format(vipervizport[1:])])ifistss1==0:doparse("/{}/docs/source/operating.rst".format(sname),["--solutionvipervizport--;{}".format(solutionvipervizport[1:])])else:doparse("/{}/docs/source/operating.rst".format(sname),["--solutionvipervizport--;{}".format("TBD")])tssdockerrun=("docker run -d \-\-net=host \-\-env AIRFLOWPORT={} " \
" -v <change to your local folder>:/dagslocalbackup:z " \
" -v /var/run/docker.sock:/var/run/docker.sock:z " \
" -v /your_localmachine/foldername:/rawdata:z " \
" \-\-env GITREPOURL={} " \
" \-\-env CHIP={} \-\-env TSS=1 \-\-env SOLUTIONNAME=TSS " \
" \-\-env EXTERNALPORT={} " \
" \-\-env VIPERVIZPORT={} " \
" \-\-env GITUSERNAME='{}' " \
" \-\-env DOCKERUSERNAME='{}' " \
" \-\-env MQTTUSERNAME='{}' " \
" \-\-env KAFKACLOUDUSERNAME='{}' " \
" \-\-env KAFKACLOUDPASSWORD='<Enter your API secret>' " \
" \-\-env READTHEDOCS='<Enter your readthedocs token>' " \
" \-\-env GITPASSWORD='<Enter personal access token>' " \
" \-\-env DOCKERPASSWORD='<Enter your docker hub password>' " \
" \-\-env MQTTPASSWORD='<Enter your mqtt password>' " \
" \-\-env UPDATE=1 " \
" maadsdocker/tml-solution-studio-with-airflow-{}".format(airflowport[1:],os.environ['GITREPOURL'],chip,externalport[1:],vipervizport[1:],os.environ['GITUSERNAME'],os.environ['DOCKERUSERNAME'],mqttusername,kafkacloudusername,chip))doparse("/{}/docs/source/operating.rst".format(sname),["--tssdockerrun--;{}".format(tssdockerrun)])producinghost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPRODUCE".format(sname))producingport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_SOLUTIONEXTERNALPORT".format(sname))preprocesshost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS".format(sname))preprocessport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS".format(sname))preprocesshost2=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESS2".format(sname))preprocessport2=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESS2".format(sname))preprocesshostpgpt=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREPROCESSPGPT".format(sname))preprocessportpgpt=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREPROCESSPGPT".format(sname))mlhost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTML".format(sname))mlport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTML".format(sname))predictionhost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERHOSTPREDICT".format(sname))predictionport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_VIPERPORTPREDICT".format(sname))hpdehost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEHOST".format(sname))hpdeport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEPORT".format(sname))hpdepredicthost=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEHOSTPREDICT".format(sname))hpdepredictport=context['ti'].xcom_pull(task_ids='step_1_solution_task_getparams',key="{}_HPDEPORTPREDICT".format(sname))tmlbinaries=("VIPERHOST_PRODUCE={}, VIPERPORT_PRODUCE={}, ""VIPERHOST_PREPOCESS={}, VIPERPORT_PREPROCESS={}, ""VIPERHOST_PREPOCESS2={}, VIPERPORT_PREPROCESS2={}, ""VIPERHOST_PREPOCESS_PGPT={}, VIPERPORT_PREPROCESS_PGPT={}, ""VIPERHOST_ML={}, VIPERPORT_ML={}, ""VIPERHOST_PREDCT={}, VIPERPORT_PREDICT={}, ""HPDEHOST={}, HPDEPORT={}, ""HPDEHOST_PREDICT={}, HPDEPORT_PREDICT={}".format(producinghost,producingport[1:],preprocesshost,preprocessport[1:],preprocesshost2,preprocessport2[1:],preprocesshostpgpt,preprocessportpgpt[1:],mlhost,mlport[1:],predictionhost,predictionport[1:],hpdehost,hpdeport[1:],hpdepredicthost,hpdepredictport[1:]))subprocess.call(["sed","-i","-e","s/--tmlbinaries--/{}/g".format(tmlbinaries),"/{}/docs/source/operating.rst".format(sname)])########################## Kubernetesdoparse("/{}/docs/source/kube.rst".format(sname),["--solutionnamefile--;{}.yml".format(sname)])doparse("/{}/docs/source/kube.rst".format(sname),["--solutionname--;{}".format(sname)])ifpgptcontainername!=Noneandollama!=None:if'127.0.0.1'inbrokerhost:kcmd="kubectl apply -f kafka.yml -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f qdrant.yml -f privategpt.yml -f ollama.yml -f {}.yml".format(sname)else:kcmd="kubectl apply -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f qdrant.yml -f privategpt.yml -f ollama.yml -f {}.yml".format(sname)doparse("/{}/docs/source/kube.rst".format(sname),["--kubectl--;{}".format(kcmd)])elifpgptcontainername!=None:if'127.0.0.1'inbrokerhost:kcmd="kubectl apply -f kafka.yml -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f qdrant.yml -f privategpt.yml -f {}.yml".format(sname)else:kcmd="kubectl apply -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f qdrant.yml -f privategpt.yml -f {}.yml".format(sname)doparse("/{}/docs/source/kube.rst".format(sname),["--kubectl--;{}".format(kcmd)])elifollama!=None:if'127.0.0.1'inbrokerhost:kcmd="kubectl apply -f kafka.yml -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f {}.yml -f ollama.yml".format(sname)else:kcmd="kubectl apply -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f {}.yml -f ollama.yml".format(sname)doparse("/{}/docs/source/kube.rst".format(sname),["--kubectl--;{}".format(kcmd)])else:if'127.0.0.1'inbrokerhost:kcmd="kubectl apply -f kafka.yml -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f {}.yml".format(sname)else:kcmd="kubectl apply -f secrets.yml -f mysql-storage.yml -f mysql-db-deployment.yml -f {}.yml".format(sname)doparse("/{}/docs/source/kube.rst".format(sname),["--kubectl--;{}".format(kcmd)])ifmaxrows4:step4maxrows=maxrows4[1:]else:step4maxrows=-1ifmaxrows4b:step4bmaxrows=maxrows4b[1:]else:step4bmaxrows=-1ifmaxrows4c:step4cmaxrows=maxrows4c[1:]else:step4cmaxrows=-1ifrollbackoffsets:step5rollbackoffsets=rollbackoffsets[1:]else:step5rollbackoffsets=-1ifmaxrows:step6maxrows=maxrows[1:]else:step6maxrows=-1kubebroker='kafka-service:9092'if'KUBEBROKERHOST'inos.environ:kubebroker=os.environ['KUBEBROKERHOST']kafkabroker='127.0.0.1:9092'if'KAFKABROKERHOST'inos.environ:kafkabroker=os.environ['KAFKABROKERHOST']step1solutiontitle=stitlestep1description=sdesctry:withopen("/tmux/cname.txt","r")asf:containername=f.read()exceptExceptionase:pass# step9bagenttoolfunctions=""step9bagents_topic_prompt=step9bagents_topic_prompt.replace("\\n","").replace('\n','').strip().replace(";","==").replace("'","")iflen(CLIENTPORT)>1:kcmd2=tsslogging.genkubeyaml(sname,containername,TMLCLIENTPORT[1:],solutionairflowport[1:],solutionvipervizport[1:],solutionexternalport[1:],sd,os.environ['GITUSERNAME'],os.environ['GITREPOURL'],chipmain,os.environ['DOCKERUSERNAME'],externalport[1:],kafkacloudusername,mqttusername,airflowport[1:],vipervizport[1:],step4maxrows,step4bmaxrows,step5rollbackoffsets,step6maxrows,step1solutiontitle,step1description,step9rollbackoffset,kubebroker,kafkabroker,PRODUCETYPE,step9prompt,step9context,step9keyattribute,step9keyprocesstype,step9hyperbatch[1:],step9vectordbcollectionname,step9concurrency[1:],cudavisibledevices[1:],step9docfolder,step9docfolderingestinterval[1:],step9useidentifierinprompt[1:],step5processlogic,step5independentvariables,step9searchterms,step9streamall[1:],step9temperature[1:],step9vectorsearchtype,step9llmmodel,step9embedding,step9vectorsize,step4cmaxrows,step4crawdatatopic,step4csearchterms,step4crememberpastwindows[1:],step4cpatternwindowthreshold[1:],step4crtmsstream,projectname,step4crtmsscorethreshold[1:],step4cattackscorethreshold[1:],step4cpatternscorethreshold[1:],step4clocalsearchtermfolder,step4clocalsearchtermfolderinterval[1:],step4crtmsfoldername,step3localfileinputfile,step3localfiledocfolder,step4crtmsmaxwindows[1:],step9pcontextwindowsize[1:],step9pgptcontainername,step9pgpthost,step9pgptport[1:],step9vectordimension[1:],step2raw_data_topic,step2preprocess_data_topic,step4raw_data_topic,step4preprocesstypes,step4jsoncriteria,step4ajsoncriteria,step4amaxrows[1:],step4apreprocesstypes,step4araw_data_topic,step4apreprocess_data_topic,step4bpreprocesstypes,step4bjsoncriteria,step4braw_data_topic,step4bpreprocess_data_topic,step4preprocess_data_topic,step9brollback,step9bdeletevectordbcount,step9bvectordbpath,step9btemperature,step9bvectordbcollectionname,step9bollamacontainername,step9bCUDA_VISIBLE_DEVICES,step9bmainip,step9bmainport,step9bembedding,step9bagents_topic_prompt,step9bteamlead_topic,step9bteamleadprompt,step9bsupervisor_topic,step9bagenttoolfunctions,step9bagent_team_supervisor_topic,step9bcontextwindow,step9blocalmodelsfolder,step9bagenttopic)else:kcmd2=tsslogging.genkubeyamlnoext(sname,containername,TMLCLIENTPORT[1:],solutionairflowport[1:],solutionvipervizport[1:],solutionexternalport[1:],sd,os.environ['GITUSERNAME'],os.environ['GITREPOURL'],chipmain,os.environ['DOCKERUSERNAME'],externalport[1:],kafkacloudusername,mqttusername,airflowport[1:],vipervizport[1:],step4maxrows,step4bmaxrows,step5rollbackoffsets,step6maxrows,step1solutiontitle,step1description,step9rollbackoffset,kubebroker,kafkabroker,step9prompt,step9context,step9keyattribute,step9keyprocesstype,step9hyperbatch[1:],step9vectordbcollectionname,step9concurrency[1:],cudavisibledevices[1:],step9docfolder,step9docfolderingestinterval[1:],step9useidentifierinprompt[1:],step5processlogic,step5independentvariables,step9searchterms,step9streamall[1:],step9temperature[1:],step9vectorsearchtype,step9llmmodel,step9embedding,step9vectorsize,step4cmaxrows,step4crawdatatopic,step4csearchterms,step4crememberpastwindows[1:],step4cpatternwindowthreshold[1:],step4crtmsstream,projectname,step4crtmsscorethreshold[1:],step4cattackscorethreshold[1:],step4cpatternscorethreshold[1:],step4clocalsearchtermfolder,step4clocalsearchtermfolderinterval[1:],step4crtmsfoldername,step3localfileinputfile,step3localfiledocfolder,step4crtmsmaxwindows[1:],step9pcontextwindowsize[1:],step9pgptcontainername,step9pgpthost,step9pgptport[1:],step9vectordimension[1:],step2raw_data_topic,step2preprocess_data_topic,step4raw_data_topic,step4preprocesstypes,step4jsoncriteria,step4ajsoncriteria,step4amaxrows[1:],step4apreprocesstypes,step4araw_data_topic,step4apreprocess_data_topic,step4bpreprocesstypes,step4bjsoncriteria,step4braw_data_topic,step4bpreprocess_data_topic,step4preprocess_data_topic,step9brollback,step9bdeletevectordbcount,step9bvectordbpath,step9btemperature,step9bvectordbcollectionname,step9bollamacontainername,step9bCUDA_VISIBLE_DEVICES,step9bmainip,step9bmainport,step9bembedding,step9bagents_topic_prompt,step9bteamlead_topic,step9bteamleadprompt,step9bsupervisor_topic,step9bagenttoolfunctions,step9bagent_team_supervisor_topic,step9bcontextwindow,step9blocalmodelsfolder,step9bagenttopic)doparse("/{}/docs/source/kube.rst".format(sname),["--solutionnamecode--;{}".format(kcmd2)])kpfwd="kubectl port-forward deployment/{}{}:{}".format(sname,solutionvipervizport[1:],solutionvipervizport[1:])doparse("/{}/docs/source/kube.rst".format(sname),["--kube-portforward--;{}".format(kpfwd)])doparse("/{}/docs/source/kube.rst".format(sname),["--visualizationurl--;{}".format(vizurlkube)])doparse("/{}/docs/source/kube.rst".format(sname),["--visualizationurling--;{}".format(vizurlkubeing)])doparse("/{}/docs/source/kube.rst".format(sname),["--nginxname--;{}".format(sname)])iflen(CLIENTPORT)>1:if'gRPC'inPRODUCETYPE:kcmd3=tsslogging.ingressgrpc(sname)else:kcmd3=tsslogging.ingress(sname)else:# localfile being processedkcmd3=tsslogging.ingressnoext(sname)doparse("/{}/docs/source/kube.rst".format(sname),["--ingress--;{}".format(kcmd3)])###########################try:tmuxwindows="None"withopen("/tmux/pythonwindows_{}.txt".format(sname),'r',encoding='utf-8')asfile:data=file.readlines()data.append("viper-produce")data.append("viper-preprocess")data.append("viper-preprocess-pgpt")data.append("viper-preprocess-agenticai")data.append("viper-ml")data.append("viper-predict")tmuxwindows=", ".join(data)tmuxwindows=tmuxwindows.replace("\n","")print("tmuxwindows=",tmuxwindows)exceptExceptionase:passdoparse("/{}/docs/source/operating.rst".format(sname),["--tmuxwindows--;{}".format(tmuxwindows)])#try:ifos.environ['TSS']=="1":doparse("/{}/docs/source/operating.rst".format(sname),["--tssgen--;TSS Development Environment Container"])else:if"KUBE"notinos.environ:doparse("/{}/docs/source/operating.rst".format(sname),["--tssgen--;TML Solution Container"])else:ifos.environ["KUBE"]=="0":doparse("/{}/docs/source/operating.rst".format(sname),["--tssgen--;TML Solution Container"])else:doparse("/{}/docs/source/operating.rst".format(sname),["--tssgen--;TML Solution Container (RUNNING IN KUBERNETES)"])# Kick off shell script#tsslogging.git_push("/{}".format(sname),"For solution details GOTO: https://{}.readthedocs.io".format(sname),sname)rtd=context['ti'].xcom_pull(task_ids='step_10_solution_task_document',key="{}_RTD".format(sname))#try:sp=f"{sname}/docs/source"orepo=tsslogging.getrepo()op=f"/{orepo}/tml-airflow/dags/tml-solutions/{projectname}"files,opath=tsslogging.dorst2pdf(sp,op)tsslogging.mergepdf(opath,files,f"{sname}")gb="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/pdf_documentation/{}.pdf".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,sname)print("INFO: Your PDF Documentation will be found here: {}".format(gb))# gitymlgityml="https://github.com/{}/{}/tree/main/tml-airflow/dags/tml-solutions/{}/ymls/{}".format(os.environ['GITUSERNAME'],tsslogging.getrepo(),projectname,sname)doparse("/{}/docs/source/kube.rst".format(sname),["--gityml--;{}".format(gityml)])oppt=copyymls(projectname,sname,kcmd3,kcmd2)updateollamaandpgpt(oppt,step9bollamacontainername,step9bconcurrency,step9bvectordbcollectionname,step9btemperature,step9brollback,step9bollama,step9bdeletevectordbcount,step9bvectordbpath,step9btopicid,step9benabletls,step9bpartition,step9bmainip,step9bmainport,step9bembedding,step9bagents_topic_prompt,step9bteamlead_topic,step9bteamleadprompt,step9bsupervisor_topic,step9bsupervisorprompt,step9bagenttoolfunctions,step9bagent_team_supervisor_topic,step9bcontextwindow,pvectorsearchtype,ptemperature,pcollection,pconcurrency,pvectordimension,pcontextwindowsize,pmainmodel,pmainembedding,pgptcontainername)subprocess.call("/tmux/gitp.sh {} 'For solution details GOTO: https://{}.readthedocs.io'".format(sname,snamertd),shell=True)#except Exception as e:# print("Error=",e)try:ifrtd==None:URL='https://readthedocs.org/api/v3/projects/'TOKEN=os.environ['READTHEDOCS']HEADERS={'Authorization':f'token {TOKEN}'}data={"name":"{}".format(sname),"repository":{"url":"https://github.com/{}/{}".format(os.environ['GITUSERNAME'],sname),"type":"git"},"homepage":"http://template.readthedocs.io/","programming_language":"py","language":"en","privacy_level":"public","external_builds_privacy_level":"public","tags":["automation","sphinx"]}response=requests.post(URL,json=data,headers=HEADERS,)print(response.json())tsslogging.tsslogit(response.json())os.environ['tssdoc']="1"time.sleep(10)updatebranch(sname,"main")triggerbuild(sname)ti=context['task_instance']ti.xcom_push(key="{}_RTD".format(sname),value="DONE")print("INFO: Your Documentation will be found here: https://{}.readthedocs.io/en/latest".format(snamertd))exceptExceptionase:print("ERROR=",e)
Json Key
Explanation
conf_project
This is the project name that will be
used in Readthedocs documentation
conf_copyright
This is the copyright information
that will be used in Readthedocs documentation
conf_author
This is the author name that will
be used in Readthedocs documentation
conf_release
This is the release number for
your Readthedocs documentation
conf_version
This is the version number that will
be used in Readthedocs documentation
dockerenv
Ideally, TML solution containers run in Kubernetes.
But, if you or other users run this container
you can specify the docker environmental variables
that can be modified at runtime. The format must be
variable1=value1***variable2=value2*…**, use
THREE (3) stars to separate variable and value pairs.
dockerinstructions
You can specify instructions for users on how to
to run your container.
8.18. Example Of Setting Docker Instructions in Step 10
default_args={'conf_project':'Transactional Machine Learning (TML)','conf_copyright':'2024, Otics Advanced Analytics, Incorporated - For Support email support@otics.ca','conf_author':'Sebastian Maurice','conf_release':'0.1','conf_version':'0.1.0','dockerenv':'step4cmaxrows=100***step4crawdatatopic=iot-preprocess***step4csearchterms=rgx:p([a-z]+)ch ~~~ |authentication failure,--entity-- password failure ***\ step4crememberpastwindows=500***step4cpatternwindowthreshold=30***step4crtmsscorethreshold=0.6***step4cattackscorethreshold=0.6***\ step4cpatternscorethreshold=0.6***step4crtmsstream=rtms-stream-mylogs***step4clocalsearchtermfolder=|mysearchfile1,|mysearchfile2***\ step4clocalsearchtermfolderinterval=60***step4crtmsfoldername=rtms2***step3localfiledocfolder=mylogs,mylogs2***step4crtmsmaxwindows=1000000',# add any environmental variables for docker must be: variable1=value1***variable2=value2'dockerinstructions':"""To run this docker container Enter the following CORE parameters: 1. KAFKABROKERHOST=127.0.0.1:9092 - this uses the Local Kafka installed in your TML solution container. You can specify a Kafka Cloud URL if using AWS MSK or Confluent Kafka Cloud, simply replace this field. 2. Enter KAFKACLOUDUSERNAME and KAFKACLOUDPASSWORD IF using Kafka Cloud from AWS MSK and Confluent, if using local kafka (127.0.0.1:9092), these MUST be empty. 3. SASLMECHANISM=PLAIN is set for Local Kafka and Confluent Kafka Cloud. If using AWS MSK, this MUST be changed to SCRAM512. 4. Enter GITUSERNAME 5. Enter GITPASSWORD 6. Enter READTHEDOCS 7. Update volume mapping: /your_localmachine/foldername:/rawdata:z 8. IF YOU ARE DISTRUBUTING THIS CONTAINER TO OTHERS THEN SEND THEM THIS DOCKER RUN BUT THEY WILL NEED TO ENTER THE ABOVE CORE PARAMETERS. TO MAKE IT EASY FOR OTHERS TO RUN YOUR SOLUTION YOU CAN USE THE TSSTMLDEMO GITHUB AND READTHEDOCS ACCOUNT - UPDATE THE FOLLOWING: 9. GITUSERNAME=tsstmldemo 10. GITREPOURL=https://github.com/tsstmldemo/tsstmldemo 11. GITPASSWORD=<Will be retrieved from OS IF using tsstmldemo> 12. READTHEDOCS=aefa71df39ad764ac2785b3167b77e8c1d7c553a 13. step4cmaxrows=100 this means the number of offsets to rollback. Change to higher or lower number. Higher number more data will be processed and more memory consumed. 14. step4crawdatatopic=iot-preprocess, this is the Step 4 preprocessing topic of the entities. If this is empty string, no entities are cross-refenced with the log files. Only log files will be processed. 15. step4csearchterms=rgx:p([a-z]+)ch ~~~ |authentication failure,--entity-- password failure, these are the fixed search terms. You can specify dynamic search terms in the field step4clocalsearchtermfolder 16. step4crememberpastwindows=500, this is the past, short-term windows for TML to remember. TML RTMS will go back 500 sliding time windows. 17. step4cpatternwindowthreshold=30, this is the maximum pattern threshold before raising an alarm. 18. step4crtmsscorethreshold=0.6, this is the RTMS score threshold. This is used to send messages that exceed this RTMS threshold to its own rtms topic. 19. step4cattackscorethreshold=0.6, this is the Attack score threshold. This is used to send messages that exceed this attack threshold to its own attack topic. 20. step4cpatternscorethreshold=0.6, this is the Pattern score threshold. This is used to send messages that exceed this pattern threshold to its own pattern topic. 21. step4crtmsstream=rtms-stream-mylogs, this is the kafka topic that stores ALL the results from RTMS. 22. step4clocalsearchtermfolder=|mysearchfile1,|mysearchfile2, this is name of the folders that contain text files for searches. A | for OR, and @ for AND. TML will read the search terms in real-time and immediately start applying them to the streamed data. 23. step4clocalsearchtermfolderinterval=60, this is the number in seconds that the files in the folders specified in step4clocalsearchtermfolder, will be read. So, 60 means, read files every 60 seconds. 24. step4crtmsfoldername=rtms2, TML RTMS will output logs of the search results to GitHub. This is convenient for testing and validation. NOTE: Only the latest 950 files will be sent to GitHub because GitHub has a maximum file limit of 1000. 25. step3localfiledocfolder=mylogs,mylogs2, these are the folders that contain your log text log files. These are read in STEP 3 LOCALFILE task. 26. step4crtmsmaxwindows=1000000, this is the maximum number of windows for LONG-TERM pattern matching. Here, TML will go-back 1,000,000 sliding time windows, which in effect could be months of analysis. Yoi can easily increase this number. - PLEASE NOTE: THE GITHUB AND READTHEDOCS ACCOUNTS ARE PUBLIC AND SHARED ACCOUNTS BY OTHERS. - THEY ARE MEANT ONLY FOR QUICK DEMOS. IDEALLY, PERSONAL GITHUB AND READTHEDOCS ACCONTS SHOULD BE USED."""}
Go to your project folder in TSS - as shown in figure below
Create and SAVE your DAG
Tip
You should copy a previously written TML Dag and then simply modify it for your needs.
Your new DAG will be in the project folder.
Important
Make sure you click Git Workspaces to commit your DAG to Github. As shown in the figure below.
Now add your new DAG to one of the solution templates. Simply click one of the solution templates.
Lets choose solution DAG solution_template_processing_dag-myawesometmlsolution.py. Import your new DAG into the temlate by adding an import statement for your new DAG. Here you can create step 11 for your new DAG called “mynewdag”:
Now, connect your new DAG to the solution process flow - as shown in figure below:
Note
This task assumes you have a function named mycooldag in your python script: tml-solutions.myawesometmlsolution.mynewdag.py and now TSS will also
run sensor_H task you just created.
To run your new solution - click DAGs in the top-menu.
You should see your new STEP 11. If so, CONGRATULATIONS! You just created a new/custom TML solution.
You may, sometimes, encounter an issue pushing to Github in the UI. IF this happens, you can issue a +gitresetpull or +gitresetpush as shown in the figure below:
Note
This ususaly happens if there is commit from another process.
Important to note that +gitresetpull will fetch all of the commits and add them to the main branch.
+gitresetpush will rebase the commit to the head of the main branch, commit the changes and push it to main branch.
After the +gitresetpull – you can then Push your changes.
8.21. Example TML Solution Container Reference Architecture
The above image shows a typical TML solution container
Attention
Every TML solution runs in a Docker container
Linux is installed in the container
TMUX (terminal multiplexer) is used to structure TML solution components in their own task windows to make it easier
to maintain and operationalize TML solutions
Apache Kafka is installed (Cloud Kafka can easily be used)
maria db is used as a configuration database for TML solutions
specific solution python scripts are installed and run the TML solution
TML dashboard code (html/javascript) runs in the container
If you want to copy from a previous TML project and rename to a new project then:
In STEP 3 type myawesometmlproject>myawesometmlproject2, the character “>” means copy myawesometmlproject to myawesometmlproject2 (as shown in figure below)
Hit Save
Voila! You just copied an older projec to a new one and saved the time in entering paramters in the DAGs.
To confirm the new project was properly copied repeat STEPS 4 - 6. You should see your myawesometmlproject2-3f10 committed to Github:
Important
The documentation link WILL ONLY be functional AFTER you run your project in TSS.
Here are your new DAGs:
Tip
Check the logs for status updates: Go to /raspberrypi/tml-airflow/logs/logs.txt
After you create a project in STEP 1 above, these templates will be copied under your project.
DO NOT MODIFY the original templates, create a project first, then work on the renamed templates under your project name.
This ensure proper versioning of projects, and ensures project integrity. Also, it allows you to see the differences between multiple projects.
Important
This solution reads a local file. All local files are in the /rawdata folder in the container. If you want to read your own local file, you MUST map a local folder to the rawdata folder. For further details refer to here Producing Data Using a Local File
As an example, let choose solution_preprocessing_dag-myawesometmlsolution-3f10
Tip
Note, when you create your own project - I called mine: myawesometmlsolution - all of the DAGs and solution templates are copied, renamed and committed to Github. It is a copy of DAG 8. Solution Template: solution_template_processing_dag.py and simply copied, renamed and moved under your project folder myawesometmlsolution-3f10. Go to TSS and see it as in STEP 3.
Also, this project folder will automatically be committed to your Github folder - see figure below.
Now, as per STEP 3. Make a Parameter Modification to Your Project’s TML DAGs as you need. This DAG uses a local file for ingesting data: how do I know this? See The Solution Template Naming Conventions
tml_read_LOCALFILE_step_3_kafka_producetotopic_dag-myawesometmlsolution-3f10.py: Change the inputfile field to point to your local data file:
I added ‘inputfile’ : ‘/rawdata/IoTData.txt’ - the IoTData.txt is provided to you for demonstation inside the TSS container in the /rawdata folder.
SAVE the file
tml_system_step_1_getparams_dag-myawesometmlsolution-3f10.py: Most of the parameters are set for you. But, if you are using KAFKA CLOUD you may want to set:
brokerhost : ‘127.0.0.1’, # <<<<************* THIS WILL ACCESS LOCAL KAFKA - YOU CAN CHANGE TO CLOUD KAFKA HOST
brokerport : ‘9092’, # <<<<************* LOCAL AND CLOUD KAFKA listen on PORT 9092
cloudusername : ‘’, # <<<< –THIS WILL BE UPDATED FOR YOU IF USING KAFKA CLOUD WITH API KEY - LEAVE BLANK
cloudpassword : ‘’, # <<<< –THIS WILL BE UPDATED FOR YOU IF USING KAFKA CLOUD WITH API SECRET - LEAVE BLANK
tml_system_step_4_kafka_preprocess_dag-myawesometmlsolution-3f10.py: Modify the preprocessing JSONCRITERIA.
Refer to JSON PROCESSING for more explanation. The following jsoncriteria is being used.
'jsoncriteria' : 'uid=metadata.dsn,filter:allrecords~\
subtopics=metadata.property_name~\
values=datapoint.value~\
identifiers=metadata.display_name~\
datetime=datapoint.updated_at~\
msgid=datapoint.id~\
latlong=lat:long', # <<< **** Specify your json criteria. Here is an example of a multiline json -
Note
Since this is preprocessing ONLY we are skipping the Machine Learning and AI DAGs - DAGS 5, 6 and 9.